AITER: AI Tensor Engine For ROCm#

Performance optimization is critical when working with GPUs, especially for tasks involving artificial intelligence, which can be extremely demanding. To fully leverage the capabilities of advanced hardware, it’s essential to master optimization strategies and ensure every available resource is utilized efficiently. In this blog we will provide an overview of AMD’s AI Tensor Engine for ROCm (AITER) and show you how easy it is to integrate AITER kernels in basic LLM training and inference workload. AITER helps developers to focus on creating operators while allowing customers to seamlessly integrate this operator collection into their own private, public, or any custom framework.
What is AI Tensor Engine for ROCm (AITER)#
AMD is introducing the AI Tensor Engine for ROCm (AITER), a centralized repository filled with high-performance AI operators [1] designed to accelerate various AI workloads. AITER serves as a unified platform where customers can easily find and integrate optimized operators into their existing frameworks—be it private, public, or custom-built as you can see in Figure 1 below. With AITER, AMD simplifies the complexity of optimization, enabling users to maximize performance while providing flexibility to meet diverse AI requirements.
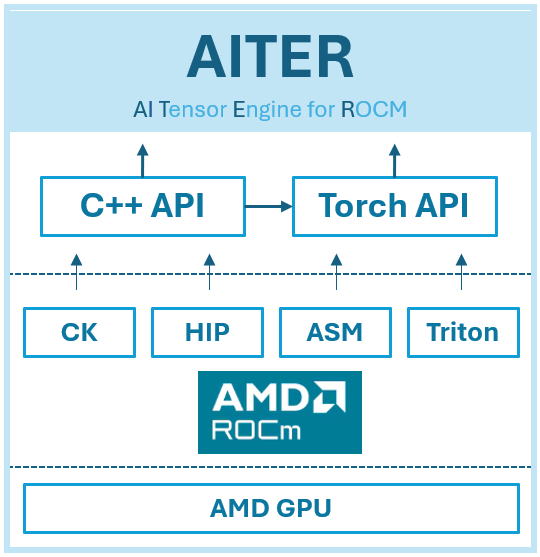
Figure 1: Block level diagram of AITER#
Key Features#
Versatile and User-Friendly Design: AITER’s architecture is carefully crafted for versatility and ease of use, allowing seamless integration into various workflows and systems.
Dual Programming Interfaces: At the highest abstraction level, AITER supports two primary interfaces—C++ and Python (Torch API). This dual-interface approach makes AITER highly accessible, catering to developers with different programming preferences and skillsets.
Robust Kernel Infrastructure: Underneath the user-level APIs, AITER employs a powerful and robust kernel infrastructure. This infrastructure is built upon a variety of underlying technologies, including Triton, CK (Composable Kernel), ASM (Assembly), and HIP (Heterogeneous Interface for Portability).
Comprehensive Kernel Support: The AITER kernel ecosystem efficiently supports diverse computational tasks such as inference workloads, training kernels, GEMM (General Matrix Multiplication) operations, and communication kernels. Such comprehensive kernel support ensures that users can confidently handle complex and resource-intensive AI tasks.
Customizable and Optimizable Kernel Ecosystem: With its rich kernel environment, AITER allows developers to perform customized optimizations tailored specifically to their applications. This flexibility helps developers to bypass or overcome architectural limitations, resulting in significantly enhanced performance and adaptability.
Seamless Integration with AMD ROCm: At its core, AITER leverages AMD’s ROCm, ensuring efficient bridging between optimized kernels and AMD GPUs. This integration unlocks the full potential and peak performance of AMD GPUs, delivering optimal efficiency across a wide range of AI workloads.
By combining user-friendly interfaces, extensive kernel capabilities, and robust GPU integration, AITER empowers developers to achieve maximum efficiency and performance in their AI applications.
Performance Gains with AITER#
By leveraging AITER’s advanced optimizations, users can experience significant performance improvements across various AI operations:
AITER block-scale GEMM: Achieves up to 2x performance boost [2], substantially accelerating general matrix multiplication tasks.
AITER block-scale fused MoE: Delivers up to 3x performance boost [3], optimizing the efficiency of Mixture of Experts (MoE) operations.
AITER MLA for decode: Provides an impressive up to 17x performance boost[4], dramatically enhancing decoding efficiency.
AITER MHA for prefill: Realizes up to 14x performance boost[5], significantly improving Multi-Head Attention (MHA) performance during prefill stages.
Note: As of this blog’s publication, AITER currently provides a performance boost for DeepSeek models on Instinct GPUs via the vLLM and SGLang frameworks. Support for additional state-of-the-art models is currently under active development and will be added in future vLLM and SGLang Docker releases.
AITER’s Integration in vLLM/SGLang for DeepSeek V3/R1#
The integration of AITER into vLLM/SGLang for the DeepSeek v3/r1 model has led to remarkable improvements in total token throughput (tokens per second, tok/s). Before AITER’s integration, the throughput stood at 6484.76 tok/s. After incorporating AITER’s optimizations, throughput dramatically increased to 13704.36 tok/s, marking more than a 2x improvement[6] in processing speed as shown in Figure 2 below.
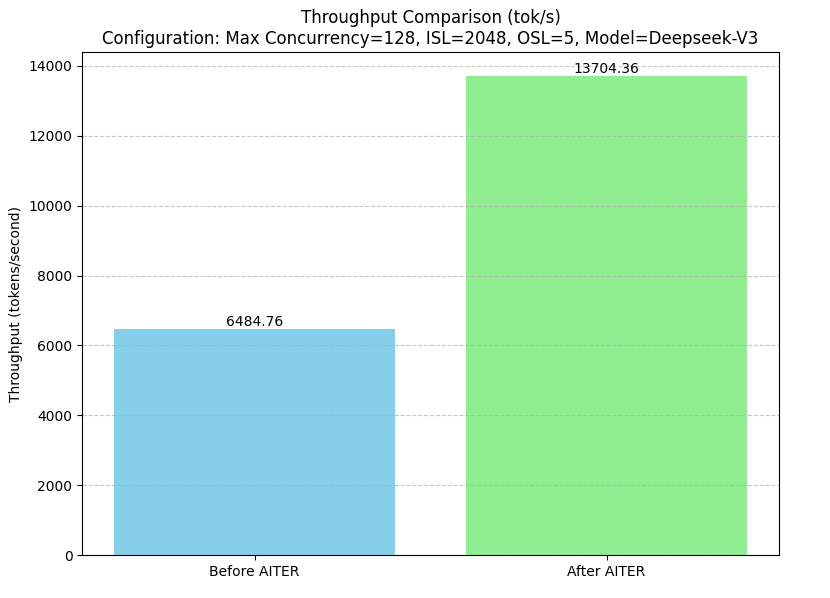
Figure 2.Throughput Comparison: Before and After Integrating AITER in SGLang on DeepSeek Models on AMD Instinct™ MI300X.#
Running Deepseek with AITER#
using vLLM
VLLM_SEED=42 VLLM_MLA_DISABLE=0 VLLM_USE_TRITON_FLASH_ATTN=0 \
VLLM_USE_ROCM_FP8_FLASH_ATTN=0 VLLM_FP8_PADDING=1 VLLM_USE_AITER_MOE=1 \
VLLM_USE_AITER_BLOCK_GEMM=1 VLLM_USE_AITER_MLA=0 vllm serve \
"deepseek-ai/DeepSeek-V3" \
--host 0.0.0.0 \
--port 8000 \
--api-key abc-123 \
--tensor-parallel-size 8 \
--trust-remote-code \
--seed 42
using SGLang
CK_BLOCK_GEMM=1 SGLANG_ROCM_AITER_BLOCK_MOE=1 RCCL_MSCCL_ENABLE=0 \
DEBUG_HIP_BLOCK_SYN=1024 GPU_FORCE_BLIT_COPY_SIZE=64 \
python3 -m sglang.launch_server --model "deepseek-ai/DeepSeek-V3" \
--tp 8 --trust-remote-code
Getting Started with AITER#
To begin working with AITER, follow these simple installation steps:
Clone the repository:
git clone https://github.com/ROCm/aiter.git
cd AITER
Under the AITER root directory, run the following command to install the library in development mode:
python3 setup.py develop
Implementing a Simple Linear Layer Using AITER#
Let’s demonstrate how you can implement a simple replica of PyTorch’s linear layer using AITER’s tgemm function.
from aiter.tuned_gemm import tgemm
import torch
class LinearLayer(torch.nn.Module):
def __init__(self, in_features, out_features):
super(LinearLayer, self).__init__()
self.weight = torch.nn.Parameter(torch.randn(out_features, in_features).cuda())
self.bias = torch.nn.Parameter(torch.randn(out_features).cuda())
def forward(self, input):
input = input.cuda()
return tgemm.mm(input, self.weight, self.bias, None, None)
# Define input size and layer size
in_features = 128
out_features = 64
batch_size = 32
# Create custom AITER linear layer
layer = LinearLayer(in_features, out_features).cuda()
input_tensor = torch.randn(batch_size, in_features).cuda()
# Get output from AITER linear layer
output_aiter = layer(input_tensor)
# Create PyTorch linear layer with same weights and bias
pytorch_layer = torch.nn.Linear(in_features, out_features).cuda()
pytorch_layer.weight = torch.nn.Parameter(layer.weight.clone())
pytorch_layer.bias = torch.nn.Parameter(layer.bias.clone())
# Get output from PyTorch linear layer
output_pytorch = pytorch_layer(input_tensor)
# Compare outputs
print("Output difference (max absolute error):", torch.max(torch.abs(output_aiter - output_pytorch)))
print("Output difference (mean absolute error):", torch.mean(torch.abs(output_aiter - output_pytorch)))
It can be very simple using AITER in daily workload, some of the other low level kernel APIs are mentioned as below which can be used to integrate in your architecture.
Kernel |
API |
|---|---|
MHA (Flash Attention) |
|
LayerNorm |
|
LayerNormFusedResidualAdd |
|
RoPE forward |
|
RoPE backward |
|
RMSNorm |
|
MLA Decode |
|
AITER is not just limited to the above mentioned APIs, there are a lot of features available as mentioned in the below table and a lot are coming very soon.
Feature |
Type (F=Forward, B=Backward) |
Details |
|---|---|---|
Prefill Attention |
F/B |
Fav3 FWD FP16/BF16 |
Decode Attention |
F |
Paged Attention FP16/BF16 |
Fused-Moe |
F |
Moe-Sorting kernel and tiling solution |
Low Precision Gemm |
F |
FP8 per-token/channel Gemm |
Distributed Gemm |
F/B |
Distributed GEMM |
Normalization and Fusion |
F |
Layernorm+quant/shortcut |
Custom Comm. |
F |
AR/AG fused with normalization |
Conv2d/2d |
F/B |
FP16/BF16 fwd/bwd/wrw |
Summary#
In this blog we introduced AMD’s AI Tensor Engine for ROCm (AITER), our centralized high performance AI operators repository, designed to significantly accelerate AI workloads on AMD GPUs. AITER has already demonstrated its value by substantially accelerating AI workloads and significantly improving efficiency and performance. AMD remains committed to continuous innovation, with numerous further enhancements and optimization efforts currently underway. The roadmap includes even greater advancements, which promise to set new standards in AI computation. Stay tuned as AMD continues to push the boundaries of performance, ensuring machine learning engineers can consistently achieve faster, more efficient, and more powerful AI solutions.
Updated on 24 March 2025
A note around the current scope of AITER was added under the Performance Gains with AITER section.
Additional Resources#
AITER Github: ROCm/aiter
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.