AMD Advances Enterprise AI Through OPEA Integration#

AMD is excited to support Open Platform for Enterprise AI (OPEA) to simplify and accelerate enterprise AI adoption. With the enablement of OPEA GenAI framework on AMD ROCm™ software stack, businesses and developers can now create scalable, efficient GenAI applications on AMD data center GPUs. Enterprises today face significant challenges when deploying AI at scale, including the complexity of integrating GenAI models, managing GPU resources, ensuring security, and maintaining workflow flexibility. AMD and OPEA aim to address these challenges and streamline AI adoption. This blog will explore the significance of this collaboration, AMD’s contribution to the OPEA project, and demonstrate how to deploy a code translation OPEA GenAI use case on the AMD Instinct™ MI300X GPU.
OPEA: A Solution to AI Deployment Challenges#
OPEA is an open, scalable framework designed to help businesses streamline and scale their AI deployments. As a member of OPEA’s technical steering committee, AMD collaborates with industry leaders to enable composable GenAI solutions. OPEA provides essential building blocks for AI applications, including pre-built workflows, evaluation tools, and key system components such as embedding models and vector databases.
Built on a cloud-native, microservices-based architecture, OPEA allows seamless integration across both public and private cloud environments using API-driven workflows. With over 50 ecosystem partners supporting the full GenAI lifecycle, businesses gain the flexibility to select the best tools for their needs. OPEA simplifies GenAI adoption by providing.
Pre-built Reference Workflows – Deployment-ready blueprints that accelerate AI adoption.
Enterprise-Grade Security – Air-gapped deployment support for secure environments.
Workload Orchestration & GPU Management – Easily plug in tools like Prometheus and Grafana to ensure efficient resource utilization and monitoring.
Flexibility & Customization – Unlike rigid, one-size-fits-all solutions, OPEA’s blueprints are designed to be customized, allowing businesses to tailor deployments to their security, compliance, and access control (RBAC) needs.
Accessing and Customizing OPEA for Your Business -While OPEA’s reference workflows provide a strong starting point, they are not intended for direct production deployment due to variations in compliance and security requirements across organizations. However, these blueprints are easily adaptable. By leveraging OPEA, enterprises can efficiently deploy GenAI solutions while maintaining flexibility, security, and scalability.
AMD is excited that AMD Instinct™ GPUs are now officially part of the hardware portfolio supporting OPEA since OPEA v1.1. Below is a table of GenAI examples with their associated deployment guide.
| GenAIExample | What does it do | Deployment Guide |
|---|---|---|
| ChatQnA | chatbot application based on RAG architecture | deployment instructions |
| FaqGen | generate natural sounding F&Qs from various document sources | deployment instructions |
| DocSum | creates summaries of different types of text | deployment instructions |
| CodeTrans | converts code between different programming languages | deployment instructions |
| CodeGen | code generation | deployment instructions |
| VisualQnA | answering open-ended questions based on an image | deployment instructions |
| AudioQnA | performing Q&A on audio files, and generates spoken responses | deployment instructions |
| AgentQnA | multi-agent system for Q&A apps | deployment instructions |
| MultiModalQnA | extract multimodal info from video files based on user questions | deployment instructions |
| Translation | language translation | deployment instructions |
Getting Started with OPEA#
In this section, we will walk through the deployment of a code translation (CodeTrans) use case (see Figure 1 for an overview).
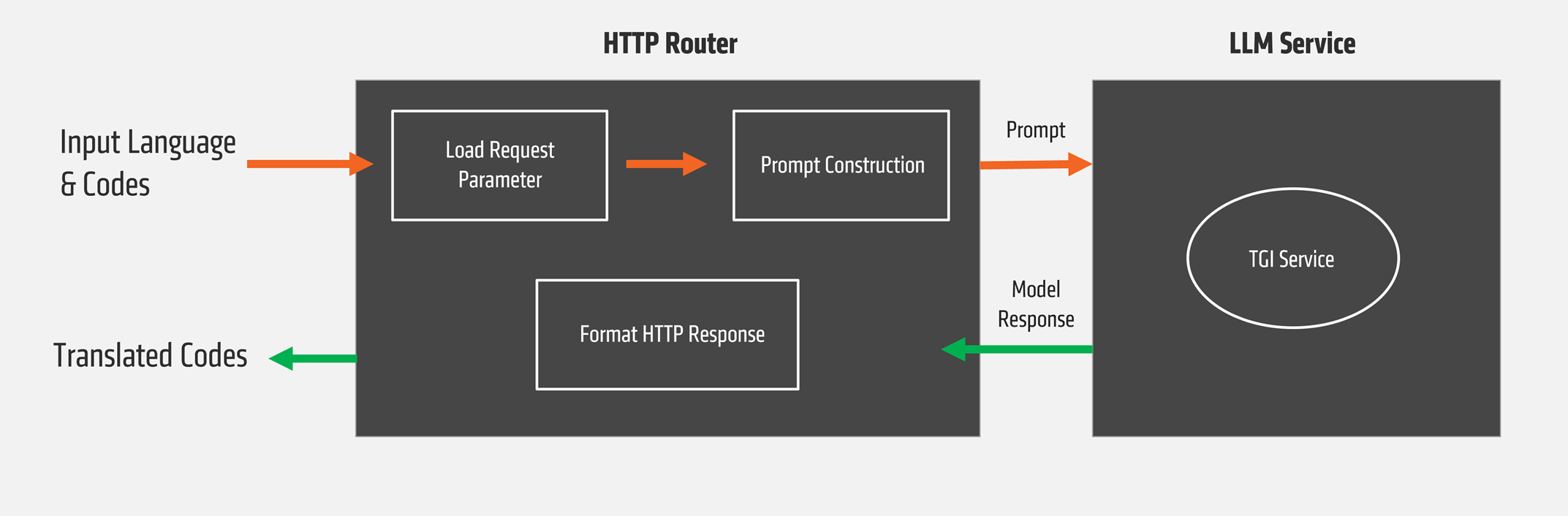
Figure 1: CodeTrans use case architecture.#
On a high-level, a user provides the source language, target language, and the code snippet to be translated, either through the front-end UI or via a direct API call. The request is then routed to the CodeTrans Gateway, which orchestrates communication with the LLM microservice and manages tasks such as prompt construction and response handling. The large language model then processes the code snippet, analyzing its syntax and semantics before generating an equivalent version in the target language. Finally, the gateway formats the model’s output and delivers the translated code back to the user, either as an API response or displayed within the GUI.
Follow the steps below to build and deploy CodeTrans application on AMD ROCm™ GPU.
Create Working Directory#
mkdir ~/opea-codetrans
cd opea-codetrans
Pulling Images from Docker Hub (recommended)#
It is recommended to use Docker images that were previously compiled and published on the Docker Hub. To do that, you need to declare the TAG variable and go straight to the application deployment, i.e. “Update set_env.sh File”.
# Declare the TAG variable
# For example, tag ‘1.1’ is used
export TAG=1.1
If TAG is not set, -latest is used as default. Alternatively, you can build the docker images following the subsequent steps.
Building Docker Images#
git clone https://github.com/opea-project/GenAIComps.git && cd GenAIComps && git checkout v1.1
docker build -t opea/llm-tgi:latest --build-arg http_proxy=$http_proxy -f comps/llms/text-generation/tgi/Dockerfile .
cd ../
git clone https://github.com/opea-project/GenAIExamples.git && cd GenAIExamples && git checkout v1.1
cd CodeTrans
Update Dockerfile#
Open the file Dockerfile and replace the following line:
RUN git clone https://github.com/opea-project/GenAIComps.git
with:
RUN git clone https://github.com/opea-project/GenAIComps.git && cd GenAIComps && git checkout v1.1 && cd ../
Save and close Dockerfile. In command-line, run the following commands, including the ‘.’ at the end of the command
docker build -t opea/codetrans:1.1 --build-arg http_proxy=$http_proxy -f Dockerfile .
Build the UI Docker Image#
cd ./ui
docker build -t opea/codetrans-ui:1.1 --build-arg http_proxy=$http_proxy -f ./docker/Dockerfile .
cd ~/opea-codetrans/GenAIComps
docker build -t opea/nginx:latest --build-arg http_proxy=$http_proxy -f comps/nginx/Dockerfile .
Let’s update the values of a few important environment variables, then we will be ready to deploy the workload. Change directory to where set_env.sh is.
cd ~/opea-codetrans/GenAIExamples/CodeTrans/docker_compose/amd/gpu/rocm
Update set_env.sh File#
#Replace hostname_or_ip to your hostname or external IP address
export HOST_IP=hostname_or_ip
#Replace hf_token value to your Huggingface API token
export CODETRANS_HUGGINGFACEHUB_API_TOKEN='hf_token'
#Replace external_ip value to your hostname or IP address
export CODETRANS_FRONTEND_SERVICE_IP=external_ip
#Replace internal_ip value to your hostname or ip address
export CODETRANS_BACKEND_SERVICE_IP=internal_ip
#If your external IP address differs from internal IP address replace value ${HOST_IP} to your external IP address or hostname
export CODETRANS_BACKEND_SERVICE_URL="http://${HOST_IP}:${CODETRANS_BACKEND_SERVICE_PORT}/v1/codetrans"
Run the shell script.
set_env.sh
GPU Allocation#
Depending on the size of the workload, you can specify which ROCm GPU device(s) to use in Docker compose file. Open compose.yaml file (which pass all GPUs to the container) and edit the tgi-service section:
devices:
- /dev/kfd:/dev/kfd
- /dev/dri:/dev/dri
to, for example just using the GPU0 of the 8xMI300X Server:
devices:
- /dev/kfd:/dev/kfd
- /dev/dri/renderD128:/dev/dri/renderD128
Please get more usage about restricting the access of AMD GPU from:
GPU isolation techniques Accessing GPUs in containers Restricting GPU access
Now, we are ready to deploy the CodeTrans example!
docker compose up -d --force-recreate
Confirm All Services are Running#
TGI service
docker logs codetrans-tgi-service -f
The TGI service is deployed successfully if there is a message in the log output:
INFO text_generation_router::server: router/src/server.rs:2210:Connected
Run the following command:
curl http://${HOST_IP}:${CODETRANS_TGI_SERVICE_PORT}/generate \
-X POST\
-d' {"inputs":"###System:Please translate the following Golang codes into Python codes.###
Original codes:'\'''\'''\''Golang\npackage main\n\nimport\"fmt\"\nfunc main(){\n
fmt.Println(\"Hello,World!\");\n'\'''\'''\''###Translated codes:","parameters":
{"max_new_tokens":100,"do_sample": true}}'\
-H' Content-Type:application/json'
The check is considered successful if the response output contains the expression
"print(\"Hello, World!\")"
LLM service#
curl http://${HOST_IP}:${CODETRANS_LLM_SERVICE_PORT}/v1/chat/completions \
-X POST\
-d' {"query":"###System:Please translate the following Golang codes into Python codes.###
Original codes:'\'''\'''\''Golang\npackage main\n\nimport\"fmt\"\nfunc main(){\n
fmt.Println(\"Hello,World!\");\n'\'''\'''\''### Translated codes:"}'\
-H' Content-Type: application/json'
The check is considered successful if the response output contains the expression
"data:[DONE]"
CodeTrans Megaservice(backend)#
curl http://${HOST_IP}:${CODETRANS_BACKEND_SERVICE_PORT}/v1/codetrans \
-H "Content-Type:application/json"\
-d' {"language_from":"Golang","language_to":"Python","source_code":"package main\n\nimport
\"fmt\"\nfunc main(){\nfmt.Println(\"Hello, World!\");\n}"}'
The check is considered successful if the response output contains the expression
"data:[DONE]"
OPEA GUI ACCESS#
You can access the GUI by the [Public IP]:PORT in browser:
Figure 2 shows a classic example of how CodeTras application helps in converting code written in one programming language “Python” to another programming language “GO” while maintaining the functionality.
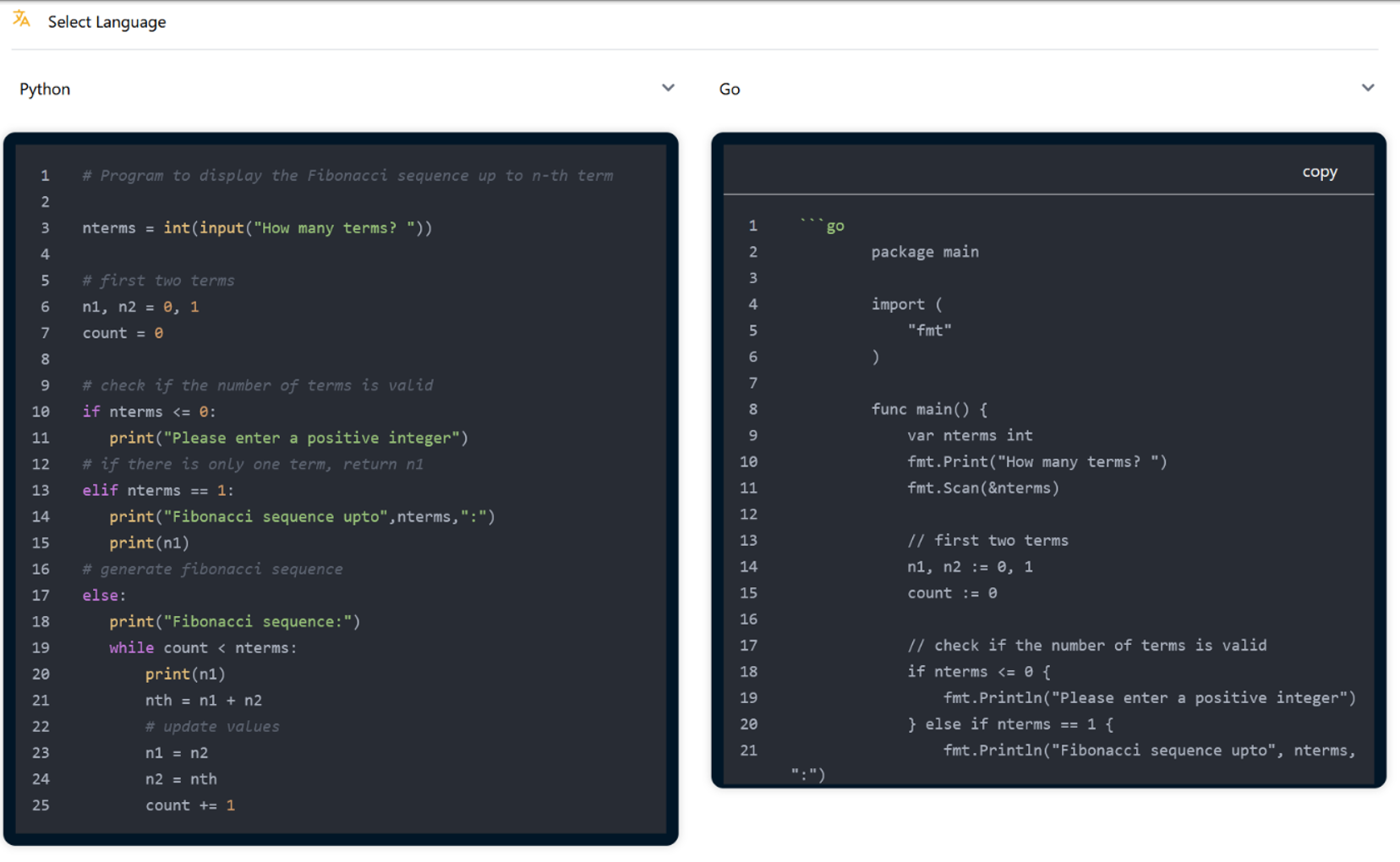
Figure 2: Example of programming language translation from Python to GO.#
Summary#
Built on an open ecosystem and cloud-native architecture, OPEA supports seamless multi-cloud deployments, API-driven workflows, and containerized pipelines. With a focus on cost efficiency, observability, and air-gapped deployment, it empowers enterprises to optimize performance without compromising security. AMD is deeply committed to the open-source community, actively contributing to key Linux Foundation projects that drive innovation across cloud, virtualization, AI, edge computing and data center. Through these efforts, AMD enhances ecosystem interoperability, optimizes software for its hardware, and fosters innovation across the broader open-source ecosystem. As the AI landscape evolves, OPEA on AMD will help organizations build adaptable, efficient, and future-ready solutions.
Additional Resources#
We encourage AI developers and enthusiasts to check the below resources section to learn more about OPEA on ROCmTM:
-Getting Started with OPEA — OPEA™ 1.2 documentation
-OPEA [Open Platform for Enterprise AI]
You can reach us at OPEAInquiry@amd.com for any OPEA related questions. We are here to help!
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.