Developers Blogs#

Introducing ROCm™ AMD Infinity Context: A Purpose-Built KV Cache Tier for Distributed Inference
Explore ROCm AMD Infinity Context (AIC), AMD's open KV cache tier built on AMD Infinity Storage for distributed LLM inference.

Scaling MiniMax-M3 Inference with Distributed Serving and Operator Co-Design on AMD Instinct MI355X GPUs
Optimize MiniMax-M3 inference on AMD Instinct™ MI355X GPUs with ATOM online quantization, AITER sparse attention, FP8 KV cache, and EAGLE3.

Building a High-Performance Video Inference Pipeline with ROCm Libraries Using C/C++
Learn how to build a powerful, GPU-accelerated video analytics pipeline with ROCm, combining rocDecode for fast hardware video decoding and MIGraphX for efficient AI-powered analysis and inference.

Understanding Attention Algorithms and Their Backends for Image and Video Generation
Practical guide to attention backends in ComfyUI on AMD describing how to optimize performance, memory, and stability with the right configuration.

GEAK V3: Agent-Driven, Repository-Level GPU Kernel Optimization across HIP, Triton, and FlyDSL on AMD GPUs
Explore GEAK v3: agent-driven, repository-level GPU kernel optimization across HIP, Triton, and FlyDSL on AMD Instinct™ GPUs.

Triton-Based Optimization of Video Sparse Attention on ROCm
Optimize video sparse attention on ROCm with GEAK and linear global context for faster, more stable video generation on AMD GPUs.

Towards Feature Complete Triton Support in JAX-Triton
Learn what new features were added to JAX-Triton and how that could help you write or reuse more efficient and readable GPU kernels in JAX.
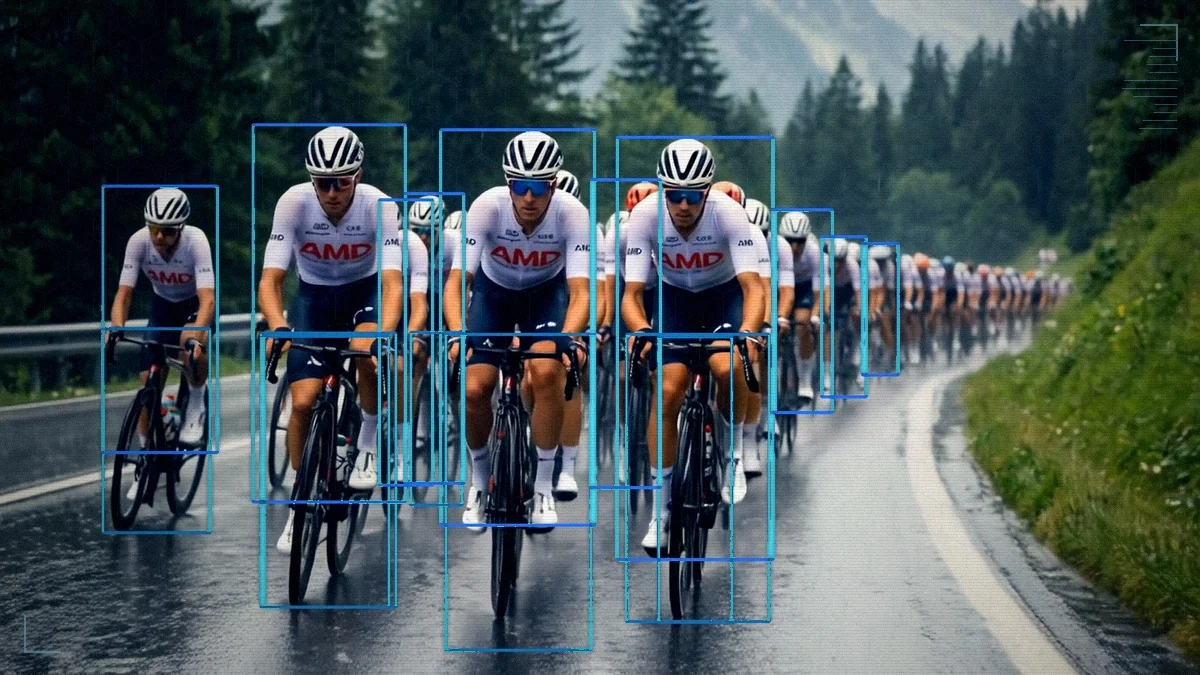
Building a GPU-Resident YOLO26 Object Detection Pipeline on the AMD Radeon™ AI PRO R9700 GPU
Build a GPU-resident object detection pipeline on AMD GPUs with rocDecode, DLPack, and MIGraphX. Frames stay in VRAM end to end.

SPIR-V on ROCm: A Portable IR for AMD GPUs
Learn how SPIR-V brings compile-once, specialize-on-device portability to AMD GPUs — with a reproducible HIP benchmark, trade-off analysis, and quick-start guide.

Performance Profiling on AMD GPUs – Part 5: Profiling-Driven Kernel Optimization with an AI Code-Assist Tool
Ready to slash HIP kernel runtimes? See how ROCm profiling + an AI code-assist agent delivered a 28.3× speedup on AMD Instinct MI250.

LogsLop: A Tiny Summarization Tool for Enormous Log Files
LogsLop deduplicates repetitive log lines so humans and LLMs can find failures in enormous log files.

RDC and RocProfiler Compared to DCGM for Commonly Used Metrics
Learn how CLI commands and Python code help you evaluate app performance without a profiler, with examples explaining what each metric means.

ROCm 7.14: TheRock Goes Production and Expands AMD's AI Software Platform
Explore what's new in ROCm 7.14: TheRock goes production, expanded hardware support, stronger AI frameworks, and enhanced profiling tools.

ROCm 7.13: Expanding Hardware, Tools, and Reach
Explore what's new in the ROCm 7.13 release, featuring expanded hardware support, GPU virtualization, enhanced developer tooling, and TheRock's modular packaging.

Building Robotics Applications with Ryzen AI and ROS 2
This blog post gives a walkthrough of how to deploy a robotics application on the AI PC integrated with ROS - the robot operating system. We showcase Ryzen AI CVML Library to do perception tasks like depth estimation and develop a custom ROS 2 node which allows easy integration with the ROS ecosystem and standard components.

Continuing the Momentum: Refining ROCm For The Next Wave Of AI and HPC
ROCm 7.1 builds on 7.0’s AI and HPC advances with faster performance, stronger reliability, and streamlined tools for developers and system builders.
Stay informed
- Subscribe to our RSS feed (Requires an RSS reader available as browser plugins.)
- Signup for the ROCm newsletter
- View our blog statistics