Kimi-K2-Instruct: Enhanced Out-of-the-Box Performance on AMD Instinct MI355 Series GPUs#

Learn how to boost AI inference performance with the Kimi-K2-Instruct model on AMD Instinct MI355 Series GPUs. This blog highlights benchmark results against B200 GPUs, focusing on faster time to first token (TTFT), lower latency, and higher throughput. You’ll also see how MI355X Series GPUs excel in high-concurrency workloads thanks to their larger memory capacity. By the end you’ll know how to evaluate and deploy MI355X GPUs with SGLang to scale demanding applications efficiently.
AMD Instinct MI355 Series GPUs Architecture#
Built on the 4th Gen AMD CDNA™ architecture and purpose-built for AI, the AMD Instinct™ MI355X GPUs feature 288GB of HBM3E memory and deliver up to 8TB/s of memory bandwidth. With expanded support for FP6 and FP4 datatypes, they offer enhanced computational flexibility for a wide range of AI and HPC workloads. Paired with the AMD ROCm™ software stack, MI355X GPUs provide strong out-of-the-box performance, improved developer efficiency, and seamless integration with popular AI frameworks, high-performance math libraries, and a broad ecosystem of AI and HPC tools.
Kimi-K2-Instruct Serving Benchmark#
For Kimi-K2-Instruct inference serving, AMD Instinct MI355 Series GPUs deliver competitive performance compared to B200 GPUs across several key metrics, including time to first token (TTFT), end-to-end latency (E2E), and total token throughput. The B200 benchmarks were conducted using SGLang with both FlashInfer and Triton attention backend on a single-node system with 8 B200 GPUs. In comparison, the MI355X benchmarks were performed using SGLang with the Triton backend on a single-node system with 8 MI355X GPUs.
Figures 1 through 3 collectively highlight the performance advantages of MI355X GPUs over B200 GPUs across key inference metrics under varying concurrency levels.
Figure 1 shows the Mean Time to First Token (TTFT, ms) with lower values indicating better performance. MI355X GPUs achieve significantly lower TTFT at high concurrency, delivering over three times better performance than B200 GPUs. This advantage is largely due to the MI355X’s larger memory capacity (288G compared to 180GB of the B200), enabling efficient handling of high-concurrency scenarios without substantial delays.
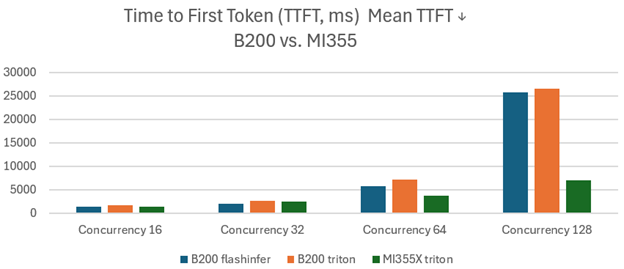
Figure 1. Kimi-K2-Instruct Mean TTFT (ms) on MI355 vs. B200 with SGLang#
Figure 2 illustrates the Mean End-to-End Latency (E2E, ms), another critical latency metric where lower latency represents better performance. Here again, MI355 GPUs outperform B200 GPUs at higher concurrency levels, confirming their efficiency in managing and reducing latency during parallel processing.
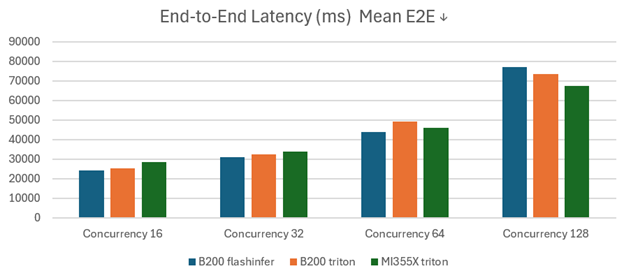
Figure 2. Kimi-K2-Instruct Mean E2E (ms) on MI355 vs. B200 with SGLang#
Figure 3 presents the comparison of Total Token Throughput (tokens per second, tok/s) and shows that the MI355X GPUs demonstrate a better throughput than B200 GPUs as concurrency increases, underscoring their strength in handling highly parallel workloads.
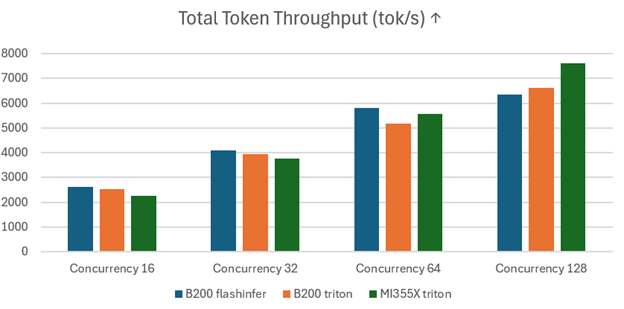
Figure 3. Kimi-K2-Instruct Total Token Throughput (tok/s) on MI355 vs. B200 with SGLang#
Reproducing the Benchmark#
You can now reproduce the performance benchmark on your own system by following the steps below.
AMD Instinct MI355X GPUs with SGLang#
Set the relevant environment variables and launch the AMD SGLang container.
docker pull lmsysorg/sglang:v0.4.9.post2-rocm700-mi35x
export MODEL_DIR=< Kimi-K2-Instruct saved_path>
docker run -it \
--ipc=host \
--network=host \
--privileged \
--shm-size 32G \
--cap-add=CAP_SYS_ADMIN \
--device=/dev/kfd \
--device=/dev/dri \
--group-add video \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
--security-opt apparmor=unconfined \
-v $MODEL_DIR:/model \
lmsysorg/sglang:v0.4.9.post2-rocm700-mi35x
Start serving the model with SGLang
# for the gfx950 architecture, set the kpack parameter to 1 in the triton attention kernel.
cd /sgl-workspace/sglang
wget https://raw.githubusercontent.com/Vivicai1005/triton_feature/main/feature.patch
git apply feature.patch
# start serving with triton backend
python3 -m sglang.launch_server --model moonshotai/Kimi-K2-Instruct --trust-remote-code --tp 8
Run the SGLang benchmark serving script with the given parameters.
CON="16 32 64 128"
ISL=3200
OSL=800
for con in $CON; do
PROMPTS=$(($con * 5))
python3 -m sglang.bench_serving \
--dataset-name random \
--random-input-len $ISL \
--random-output-len $OSL \
--num-prompt $PROMPTS \
--random-range-ratio 1.0 \
--max-concurrency $con
done
NVIDIA B200 GPUs with SGLang#
Set the relevant environment variables and launch the Nvidia SGLang container.
docker pull lmsysorg/sglang:v0.4.9.post3-cu128-b200
docker run -it \
--gpus all \
--shm-size 32g \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--env "HF_TOKEN=<secret>" \
--ipc=host \
lmsysorg/sglang:v0.4.9.post3-cu128-b200
Start the SGLang server
# start serving with flashinfer backend
python3 -m sglang.launch_server --model moonshotai/Kimi-K2-Instruct --trust-remote-code --tp 8 --host 0.0.0.0 --port 30000
# start serving with triton backend
python3 -m sglang.launch_server --model moonshotai/Kimi-K2-Instruct --attention-backend triton --trust-remote-code --tp 8 --host 0.0.0.0 --port 30000
Run the SGLang benchmark serving script with the given parameters
CON="16 32 64 128"
ISL=3200
OSL=800
for con in $CON; do
PROMPTS=$(($con * 5))
python3 -m sglang.bench_serving \
--dataset-name random \
--random-input-len $ISL \
--random-output-len $OSL \
--num-prompt $PROMPTS \
--random-range-ratio 1.0 \
--max-concurrency $con
done
Summary#
When serving the Kimi-K2-Instruct model with SGLang, AMD Instinct MI355 Series GPUs deliver strong out-of-the-box performance in key metrics, particularly excelling in high-concurrency scenarios. Their superior memory capacity plays a major role in this advantage, making them especially well-suited for demanding workloads that require both high throughput and low latency.
Evaluate and deploy MI355X GPUs for your SGLang-based Kimi-K2-Instruct serving workloads to maximize both throughput and concurrency efficiency. Their larger memory capacity makes them ideal for scaling demanding applications that require both speed and responsiveness.
Additional Resources#
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.