Nitro-T: Training a Text-to-Image Diffusion Model from Scratch in 1 Day#

AMD is excited to release Nitro-T, a family of text-to-image diffusion models focused on highly efficient training. Our models achieve competitive scores on image generation benchmarks compared to previous models focused on efficient training while requiring less than 1 day of training from scratch on 32 AMD Instinct MI300X GPUs.
By training Nitro-T from scratch on Instinct MI300X GPUs, we highlight our hardware’s capability and scalability in handling demanding AI training workloads, offering a viable alternative in the AI hardware landscape. In line with our commitment to open source, we are releasing our model weights along with fully open-source training, dataset preprocessing, and inference code. We hope this encourages experimentation, democratizes access to generative AI tools, and helps advance further research in the field.
Overview of Nitro-T Models#
AMD previously released Nitro-1, a series of distilled diffusion models focused on fast inference. We continue our focus on efficient diffusion models by training text-to-image diffusion models from scratch in a resource-efficient manner – achieving this in less than 1 day using 32 Instinct MI300X GPUs. This results in an approximately 14x reduction in training cost compared to PixArt-α, a similar open-source Diffusion Transformer model. We achieved this efficient training through an amalgamation of several state-of-the-art methods, including smart architectural choices and systems optimizations.
Nitro-T comes in two variants: a 0.6B parameter Diffusion Transformer (DiT) model optimized for generating images at 512px, and a 1.2B parameter Multimodal Diffusion Transformer (MMDiT) optimized for high-resolution 1024px generation. These models utilize a Llama 3.2 1B model to provide text conditioning. Their training involved strategies and design choices that enable reduced patch sequence length, faster convergence, and optimized training throughput.
Key Takeaways#
Announcing Nitro-T, a family of text-to-image diffusion models developed by AMD that demonstrates efficient training from scratch in less than 1 day on 32 Instinct MI300X GPUs.
Achieved through smart architectural choices and system optimizations supported by the AMD ROCm™ software stack and the PyTorch for ROCm training Docker.
Fully open and accessible training code and model weights, lowering the barrier to entry and enabling smaller teams, independent developers, and researchers to train or fine-tune customized models tailored precisely to their needs and constraints.
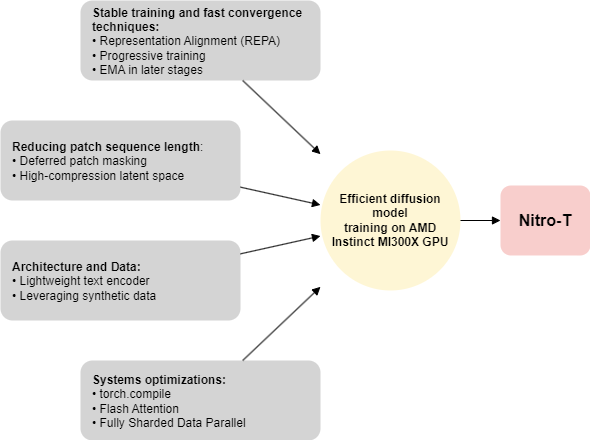
Figure 1. We achieve efficient diffusion model training through an amalgamation of several state-of-the-art methods, including smart architectural choices, training strategies, and systems optimizations#
Reducing Patch Sequence Length#
Deferred Patch Masking#
One of the major computational bottlenecks in transformer-based architectures is the self-attention mechanism, whose complexity scales quadratically with the number of input tokens. Reducing the token sequence length during training is therefore a natural way to accelerate model training.
Diffusion Transformers operate on tokens derived from image patches. Due to the spatial redundancy inherently present in images, the token sequence length can be reduced by randomly dropping or masking out tokens. However, naive token dropping can significantly degrade model performance by discarding critical information needed for learning high-level structure. To address this, we adopt the deferred masking strategy introduced by MicroDiT [1]. Instead of applying token masks upfront, this method introduces an intermediate lightweight module called the patch-mixer, composed of a few transformer blocks. The key idea is to delay the masking operation until after the patch-mixer stage, allowing the model to first aggregate and mix information across the entire image. This ensures that even when a subset of tokens is dropped, the remaining tokens still encode a global view of the input, preserving important contextual and structural signals.
We integrate the deferred masking strategy by splitting our transformer into two segments: the initial few layers serve as the patch-mixer, followed by the main model where token masking is applied. For simplicity and flexibility, we avoid architectural changes and only configure the patch-mixer via its depth. Empirically, we find that using two transformer blocks as the patch-mixer and a 50% masking ratio yields a good tradeoff between quality and training speed.
High Compression Latent Space#
A common approach for training image generation models is to encode images from pixel space into a latent representation using an autoencoder. Operating in a latent space allows models to process images more efficiently using a compressed image representation rather than raw pixels. Previous diffusion models such as Stable Diffusion XL [2], PixArt [3], and Stable Diffusion 3 [4] used autoencoders with an 8x spatial compression ratio, which empirically struck a balance between image quality and computational efficiency. Further increasing the compression ratio with conventional autoencoders results in significant deterioration of reconstruction quality. Recently Deep Compression Autoencoder (DC-AE) [5] introduced an autoencoder architecture capable of achieving much higher compression ratios of 32x or 64x without substantial loss in image quality. In our experiments, we adopted a DC-AE with a 32x compression ratio, which reduces the number of latent tokens by 93.75% compared to traditional 8x models. This substantial token reduction significantly accelerates training and also results in a model that is much faster during inference.
Stable Training and Fast Convergence Techniques#
Representation Alignment#
Representation Alignment (REPA) [6] is a recent technique to accelerate the convergence of diffusion models by guiding them toward semantically meaningful image representations. REPA introduces an auxiliary objective that encourages the intermediate features of the diffusion model to align with those produced by a strong pretrained vision model, such as DINO v2. The rationale behind this approach is that the denoising process in diffusion inherently involves learning structured image representations. By explicitly regularizing the model to match high-quality features from a pretrained encoder, REPA effectively accelerates this representational learning and leads to faster convergence.
Unlike the original method, where all patch tokens are retained throughout the training process, we apply the REPA loss only to the subset of tokens that remain unmasked. We found this to be effective as long as we align the spatial locations of the DINO feature vectors with those of the unmasked tokens.
Progressive Training From Low- To High-resolution#
To accelerate the training of our high-resolution 1024px model, we first pre-train it at 512px resolution followed by fine-tuning at high resolution. This allows the model to learn visual structure and text-image alignment at a lower computational cost. Similar to MicroDiT [1], we utilize positional embedding interpolation to smoothly transition the model from low to high resolution training. We also employ the resolution-dependent flow matching timestep shifting proposed by SD3 [4].
Most prior work, including MicroDiT [1] and SD3 [4] begin pretraining at 256px resolution before progressively increasing resolution to 512px, 1024px and beyond. In our case, due to the 32x compressed latent space of DC-AE, we found it feasible and effective to begin pretraining at 512px directly, choosing to skip the 256px stage.
MicroDiT [1] further breaks down the progressive training pipeline: at each resolution, they first pretrain with 75% patch masking ratio followed by finetuning with no patch masking. The rationale is that the unmasked finetuning recovers some of the quality loss caused by the patch masking. In our case, however, we observed little benefit to unmasked finetuning in terms of the visual quality of the generated images. Therefore, we chose to maintain patch masking throughout the training including the high-resolution finetuning phase, which significantly reduces the overall training time.
These above two choices resulted in a simplified progressive training process, consisting of just two stages as shown in Table 1.
Resolution |
Masking ratio |
Training steps |
|---|---|---|
512px |
50% |
100k |
1024px |
50% |
20k |
Table 1. Two stages of progressive training for the high-resolution model.
EMA in Later Stages#
Maintaining an Exponential Moving Average (EMA) copy of the model weights during training to smooth out the gradient updates is a commonly used technique to improve model quality. However, this introduces additional memory overhead and computational cost at each training step. Therefore, similar to MicroDiT [1], we use EMA only in the final finetuning phase.
Architecture & Data#
Lightweight Text Encoder#
Most prior text-to-image models have used text encoder models like CLIP and T5 to encode the prompt and provide conditioning to the diffusion model. Recent works have proposed using modern LLMs (like Llama or Gemma) as a better alternative. Although modern LLMs are decoder-only models, they can be used as text encoders by interpreting their final layer hidden states as text embeddings. These models have better text understanding than older models like CLIP and are cheaper at inference-time than previously-used models like T5-XXL. In our case, we adopt the lightweight Llama 3.2 1B model as our text encoder. Similar to Sana [7], we apply RMSNorm to the text embeddings in order to improve training loss stability.
DiT & MMDiT#
We trained two models: a 0.6B parameter Diffusion Transformer (DiT) model that closely follows the architecture of PixArt-α, and a 1.2B parameter Multimodal Diffusion Transformer (MMDiT) that resembles the Stable Diffusion 3 architecture. While the DiT architecture utilizes a cross-attention mechanism to incorporate text inputs, the MMDiT architecture fuses text and image tokens together to perform joint self-attention, which in theory facilitates richer interactions between textual descriptions and visual content. We trained these two variants to understand the effect of the previously mentioned efficiency techniques across different architectures and sizes.
Leveraging Synthetic Data#
As reported by previous works [3, 4, 1], involving some synthetic data in the training data mix can improve text-image alignment and accelerate convergence. Following MicroDiT [1], we assembled a dataset of ~35 million images consisting of both real and synthetic data sources as listed in Table 2. The dataset consists entirely of images that are openly available on the internet, allowing our approach to be reproduced easily.
Source |
Number of Images |
Type of Images |
Caption Type |
Generation Method |
|---|---|---|---|---|
Segment Anything 1B |
10M |
Real |
Synthetic captions via LLaVA |
Real images annotated via LLaVA |
CC12m |
7M |
Real |
Human-written captions |
Human-curated dataset |
DiffusionDB |
14M |
Synthetic |
Human-written prompts |
Stable Diffusion generated images |
JourneyDB |
4M |
Synthetic |
Human-written prompts |
Midjourney generated images |
Table 2. List of data sources that comprised our 35M training dataset. It consists of a mix of real and synthetic images and captions.
Several key insights emerged from this approach. First, we found that when training with synthetic images, the model started to generate well-structured images at earlier training iterations, although at the expense of producing images with a somewhat “cartoonish” aesthetic. Second, using the JourneyDB dataset for the high-resolution fine-tuning stage produced better text-image alignment than using the 3x larger DiffusionDB dataset, likely due to the stronger capabilities of the model used to generate it (Midjourney vs Stable Diffusion). Overall, our findings suggest that a large dataset with dense, high-information captions is a more important factor in building a good image model than the model architecture or size. At large scale, this will likely have to involve a good number of synthetic captions.
Experiments#
Implementation Details#
We perform our experiments using the PyTorch for ROCm training Docker image which provides a prebuilt optimized environment for training models on AMD Instinct MI325X and MI300X GPUs. To optimize the performance of the attention operator, we use the ROCm Flash Attention library that leverages efficient low-level kernels from Composable Kernel. We leverage graph-level optimizations using torch.compile to JIT compile the transformer module. We implemented Fully Sharded Data Parallel v2, but due to the large memory capacity of the MI300X GPU we achieved better throughput using simple Distributed Data Parallel.
We precompute the latent representations of the training images as well as the text embeddings of the prompts prior to training to avoid having to run the AE or text encoder during training, which substantially improves training throughput. Since the preprocessing cost can be amortized over multiple training runs and experiments, we do not include it in the final training cost calculation.
We trained the models using a simple flow matching objective. We intentionally did not perform extensive hyperparameter tuning over learning rate or batch size to minimize the resources used for the project.
| Parameters | TFLOPS | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | Resolution | Main network | Text Encoder | VAE | Total | Main network (single forward) | Text Encoder (single forward) | VAE | Default num steps per image | Total † | Dataset Size (M) | Training GPU hours ‡ | Inference Latency § | GenEval Overall | Human Preference Score v2 |
| Nitro-T-1.2B (ours) | 1024px | 1.26B | 1.24B | 0.31B | 2.81B | 1.36 | 0.64 | 8.37 | 20 | 64.05 | 35 | 522 | 451 | 0.47 | 28.65 |
| Nitro-T-0.6B (ours) | 512px | 0.61B | 1.24B | 0.31B | 2.16B | 0.32 | 0.64 | 2.09 | 20 | 16.30 | 35 | 440 | 338 | 0.48 | 29.6 |
| MicroDiT | 512px | 1.17B | 0.99B | 0.08B | 2.24B | 1.13 | 0.05 | 2.51 | 30 | 70.11 | 37 | 525 | 1657 | 0.46 | 27.92 |
| PixArt-α | 1024px | 0.61B | 4.76B | 0.08B | 5.46B | 6.51 | 1.12 | 10.47 | 20 | 273.08 | 25 | 7530 | 1962 | 0.48 | 30.82 |
| Sana-1.6B | 1024px | 1.60B | 2.61B | 0.31B | 4.53B | 2.97 | 1.67 | 8.37 | 20 | 130.37 | 50 | N/A | 838 | 0.69 | 28.69 |
| Stable Diffusion 3 Medium | 1024px | 2.03B | 5.58B | 0.08B | 7.69B | 8.90 | 2.51 | 10.47 | 28 | 514.14 | 1000 | N/A | 1604 | 0.68 | 30.34 |
| Stable Diffusion XL | 1024px | 2.57B | 0.82B | 0.08B | 3.47B | 6.76 | 0.06 | 10.47 | 50 | 686.68 | N/A | 1950 | 0.55 | 28.63 | |
| Stable Diffusion 1.5 | 512px | 0.86B | 0.12B | 0.08B | 1.07B | 0.80 | 0.01 | 2.51 | 50 | 82.84 | 4800 | 62496 | 564 | 0.43 | 24.44 |
| Wurstchen | 1024px | 2.05B | 1.05B | 0.02B | 3.11B | - | - | - | - | 103.63 | 1420 | 10248 | 1601 | 0.45 | 28.65 |
Table 3: Main results table comparing our Nitro-T models to popular open-weight and open-source models in terms of parameter count, inference TFLOPS, dataset size, training GPU hours, inference latency and quality metrics (GenEval and HPS) [10]. † - Total = 2 * (Main * Steps + Text encoder) + VAE ; ‡ - Normalized to MI300X ; § - Per image at batch size 1 on MI300X with torch.compile
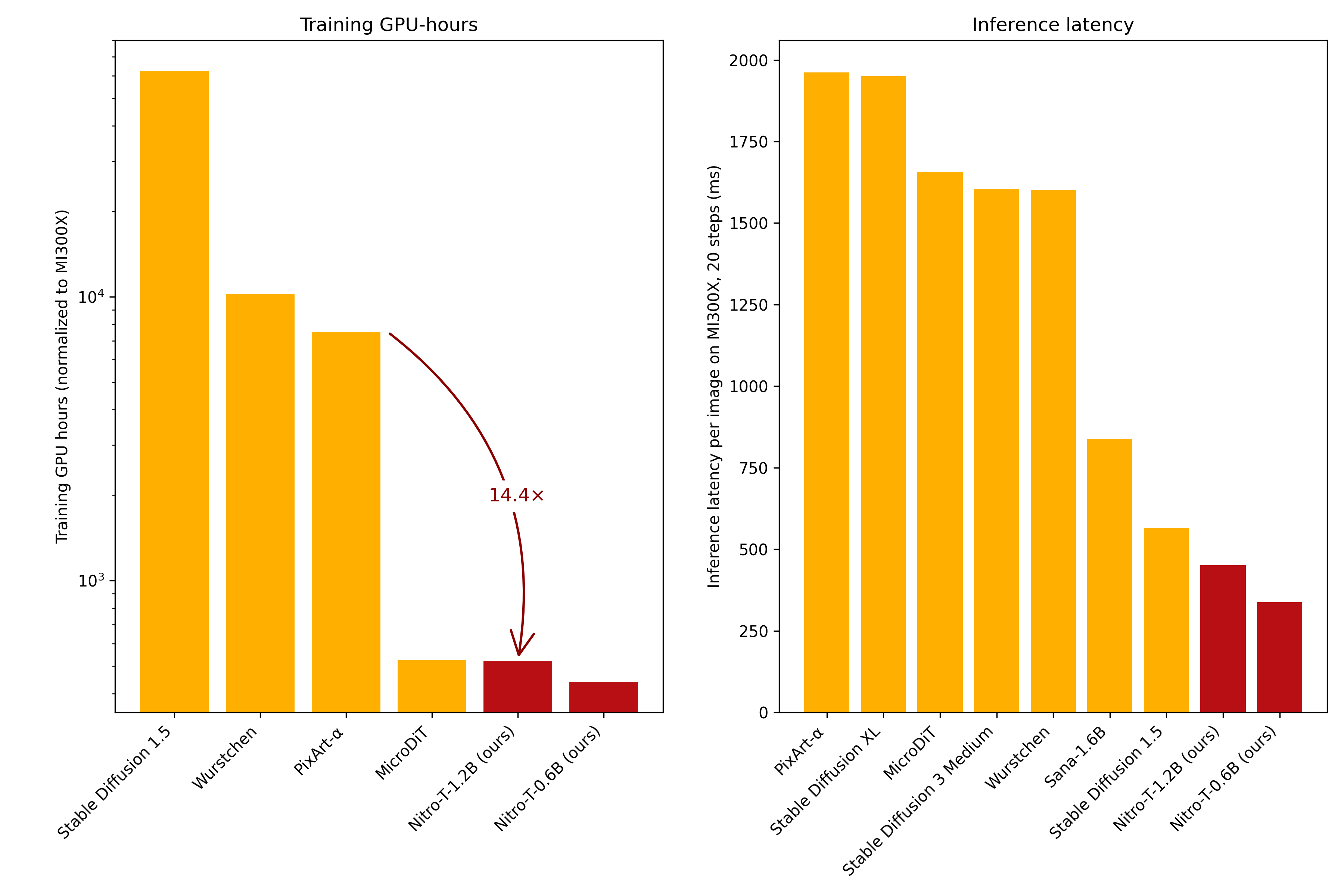
Figure 2. Our Nitro-T models require significantly fewer GPU hours to train and are also faster for inference compared to several popular open-weight and open-source models. [10]#
Training Cost#
As shown in Figure 2, we’re able to train the Nitro-T-0.6B DiT model from scratch in only 440 GPU hours by leveraging the efficient algorithms and systems optimizations described above. For context, the MicroDiT model required approximately 525 GPU hours while scoring slightly lower in image benchmarks than Nitro-T-0.6B.
Scaling up, our higher-resolution Nitro-T-1.2B MMDiT model completed training in 520 GPU hours, showcasing remarkable efficiency compared to PixArt-α, which took roughly 7500 GPU hours. Our optimized training strategy thus represents a 14.4x reduction in compute resources compared to PixArt-α.
Translating these numbers into practical training times, on a single AMD Instinct MI300X node with 8 GPUs, Nitro-T-0.6B can be trained in about 2.3 days, while the larger Nitro-T-1.2B model requires roughly 3.5 days. Leveraging four nodes, training durations drop significantly, completing in less than a single day. Notably, we observed that the MMDiT variant achieves higher throughput and demonstrates superior scalability when increasing GPU count. We attribute this improvement primarily to MMDiT’s use of joint text-image attention over DiT’s cross attention mechanism.
On a single node of InstinctTM MI300X GPUs with the PyTorch ROCm Docker image v25.5 and torch.compile, the Nitro-T-1.2B pretraining stage can achieve about 254 samples/second/GPU of end-to-end training throughput with a global batch size of 2048 without requiring the use of activation checkpointing or gradient accumulation.
Quality Metrics#
We assessed our models using two primary metrics: GenEval [8], an evaluation framework that measures compositional image properties such as object co-occurrence, spatial arrangement, count, and color fidelity using object detection and vision models; and Human Preference Score (HPS) [9], a learned scoring model trained on large-scale human preference data to predict which images are more likely to be favored by humans, offering a scalable proxy for subjective evaluation.
As shown in Table 3, on the GenEval benchmark, our models easily outperform the earlier Stable Diffusion 1.5 model, despite the latter requiring roughly 9.5x greater GPU resources for training. Moreover, our models achieve scores comparable to both MicroDiT and PixArt-α, with the latter consuming about 14x more GPU hours during training.
In terms of Human Preference Score, our models outperform MicroDiT, despite requiring similar training resources. Additionally, our models surpass recent models Sana and SDXL on this metric, whose training resource demands remain undisclosed.
Inference Cost#
Our models are not just quick to train, but also lightweight during inference, primarily due to the highly compressed latent space and relatively small text encoder. As shown in Figure 2 and Table 3, our models require fewer inference TFLOPS and have lower latency than several popular contemporary models.
Visual Samples#
Figure 3 and 4 show sample outputs generated by the model:

Figure 3. Images generated by Nitro-T-1.2B at 1024px resolution#

Figure 4. Images generated by Nitro-T-0.6B at 512px resolution#
Summary#
In this blog post, the AMD Research team shared our experience in training the Nitro-T models – a family of text-to-image diffusion models trained using a highly resource-efficient approach, achieving competitive performance with significantly reduced training times. By leveraging innovative techniques such as deferred patch masking, deep compression autoencoders, and representation alignment, together with the latest ROCm software stack on AMD Instinct MI300X GPUs, we demonstrated training these models from scratch in less than a single day. Ultimately, these advancements enable researchers to iterate faster on ideas and lower the barrier for independent developers and smaller teams to train or fine-tune models tailored precisely to their needs and constraints. By releasing our full training code and model weights, we hope our work encourages experimentation, democratizes access to generative AI tools, and helps advance further research in the field.
Resources#
Huggingface model cards:
Full training code: AMD-AIG-AIMA/Nitro-T
Related work on diffusion models by the AMD team:
Please refer to the following resources to get started with training on AMD ROCm:
Use the public PyTorch ROCm Docker images that enable optimized training performance out-of-the-box.
PyTorch Fully Sharded Data Parallel (FSDP) on AMD GPUs with ROCm — ROCm Blogs
Accelerating Large Language Models with Flash Attention on AMD GPUs — ROCm Blogs
Accelerate PyTorch Models using torch.compile on AMD GPUs with ROCm — ROCm Blogs
Contributors#
Core contributors: Akash Haridas, Tong Shen, Jingai Yu
Contributors: Dong Zhou, Dong Li, Vikram Appia, Emad Barsoum
Citation#
Feel free to cite our Nitro models:
@misc{Nitro Diffusion,
title = {Nitro-T: Efficient Training of Text-to-Image Diffusion Models from Scratch},
url = {https://huggingface.co/collections/amd/amd-nitro-diffusion-6734c32774e68a24fadbc822},
author = {Akash Haridas, Tong Shen, Jingai Yu, Dong Zhou, Dong Li, Vikram Appia, Emad Barsoum},
month = {June},
year = {2025}
}
References#
[1] Vikash Sehwag, et al. “Stretching Each Dollar: Diffusion Training from Scratch on a Micro-Budget,” in arXiv, 2024.
[2] Dustin Podell, et al. “SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis,” in arXiv, 2023.
[3] Junsong Chen, et al. “PixArt-\(alpha\): Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis,” in arXiv, 2023.
[4] Patrick Esser, et al. “Scaling Rectified Flow Transformers for High-Resolution Image Synthesis,” in arXiv, 2024.
[5] Junyu Chen, et al. “Deep Compression Autoencoder for Efficient High-Resolution Diffusion Models,” in arXiv, 2025.
[6] Sihyun Yu, et al. “Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think,” in ICLR, 2025.
[7] Enze Xie, et al. “SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers,” 2024.
[8] Dhruba Ghosh,et al. GenEval: An Object-Focused Framework for Evaluating Text-to-Image Alignment.
[9] Xiaoshi Wu,et al. Human Preference Score v2: A Solid Benchmark for Evaluating Human Preferences of Text-to-Image Synthesis.
[10] SYSTEM CONFIGURATION:
On average, a system configured with an AMD Instinct™ MI300X GPU running tests done by AMD on 05/17/2025, results may vary based on configuration, usage, software version, and optimizations.
AMD Instinct ™ MI300X platform System Model: Supermicro AS-8125GS-TNMR2 CPU: 2x AMD EPYC 9575F 64-Core Processor NUMA: 1 NUMA node per socket. NUMA auto-balancing disabled Memory: 2304 GiB (24 DIMMs x 96 GiB Micron Technology MTC40F204WS1RC48BB1 DDR5 4800 MT/s) Disk: 16,092 GiB (4x SAMSUNG MZQL23T8HCLS-00A07 3576 GiB, 2x SAMSUNG MZ1L2960HCJR-00A07 894 GiB) GPU: 8x AMD Instinct MI300X 192GB HBM3 750W Host OS: Ubuntu 22.04.4 System BIOS: 3.5 System Bios Vendor: American Megatrends International, LLC. Host GPU Driver: (amdgpu version): ROCm 6.3.4 Docker image: rocm/pytorch-training:v25.5
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.