Step-Video-T2V Inference with xDiT on AMD Instinct MI300X GPUs#

The Stepfun Step-Video-T2V is a 30B parameter state-of-the-art text-to-video (T2V) model capable of generating high-quality videos of up to 204 frames. As video generation advances toward Artificial General Intelligence (AGI), such models play a key role in automating and democratizing video creation. In this blog, we introduce Step-Video-T2V with xDiT running efficiently out-of-the-box on multi-GPU systems powered by AMD Instinct™ MI300X, leveraging high-bandwidth memory and ROCm ™ for fast, scalable video generation.
Step-Video-T2V Architecture#
Step-Video-T2V incorporates three core components:
Text Encoder: Utilizes two bilingual encoders — Hunyuan-CLIP, a bidirectional encoder aligning text and visual features, and Step-LLM, a unidirectional encoder without input length restrictions to produce robust, adaptive-length text embeddings that effectively guide the latent space;
DiT with 3D Full Attention: Built on a 30-billion-parameter DiT model and employs 3D full attention to comprehensively capture spatiotemporal dependencies, enhancing video fidelity;
Video-VAE: Features a novel dual-path architecture optimized for efficient spatial-temporal compression and compresses video at 16x16 spatial and 8x temporal ratios while preserving essential visual and motion details.
User prompts are first encoded into text embeddings that guide the DiT-based diffusion process via Flow Matching to generate coherent video frames, followed by the application of Video-based Direct Preference Optimization (DPO) post-training, further improving realism and reducing visual artifacts as shown in Figure 1.
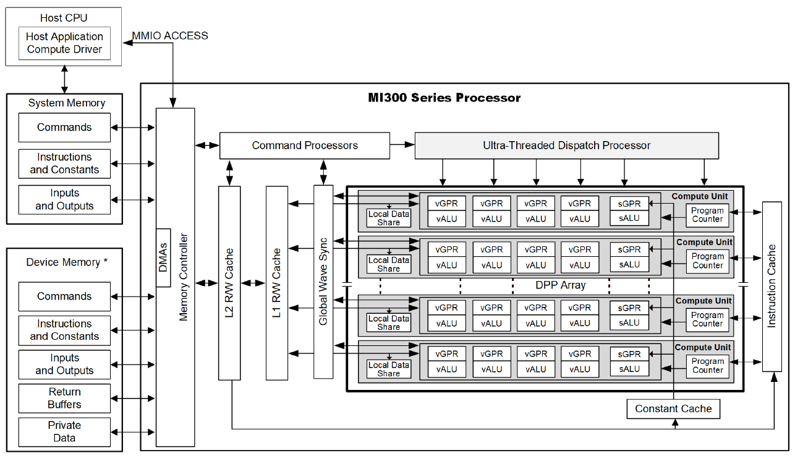
Figure 1. Architecture overview of Step-Video-T2V#
How to train a Step-Video-T2V Model#
The training pipeline employs cascading techniques: text-to-image pre-training, text-to-video pre-training, supervised fine-tuning (SFT), and direct preference optimization (DPO) as shown in Figure 2. This approach accelerates convergence and effectively utilizes diverse video datasets.
Text-to-Image (T2I) pre-training: The model is first trained on large-scale image-text pairs to build a strong understanding of visual concepts and spatial relationships.
Text-to-Video/Image (T2VI) Joint Pre-training: this phase includes low-resolution video pre-training (192p) which focuses on learning motion dynamics and high-resolution pre-training (540p) which enhances the model’s ability to capture fine visual details.
Text-to-Video (T2V) supervised fine-tuning: The model is fine-tuned using high-quality video-caption pairs to reduce artifacts and align style.
Direct preference optimization (DPO) training: Human preferences are used to guide the model’s output refinement. A reward model is also introduced for dynamic feedback during training.
Figure 2 : Pipeline of incorporating human feedback#
Run Step-Video-T2V Out-of-Box on MI300X GPUs#
We have modified the Step-Video-T2V repository code, specifically adjusting the text encoder and VAE decoder components based on DiffSynth-Studio repository, to ensure it is compatible with ROCm for multi-GPU inference development.
Prerequisites#
Before running Step-Video-T2V, ensure all necessary dependencies and packages are correctly installed. Below are detailed steps to set up the environment, install essential libraries, and prepare your system for deployment.
Step 1: Create a conda environment#
conda create -n stepvideo python=3.10
conda activate stepvideo
Step 2: Install PyTorch#
pip install torch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 --index-url https://download.pytorch.org/whl/rocm6.2
Step 3: Install Flash-Attention with Triton Backend#
pip install triton==3.2.0
git clone https://github.com/Dao-AILab/flash-attention
export FLASH_ATTENTION_TRITON_AMD_ENABLE="TRUE"
cd flash-attention
python setup.py install
Step 4: Install xfuser#
git clone https://github.com/xdit-project/xDiT
cd xDiT
pip install -e .
Step 5: Install Step-Video-T2V#
git clone -b rocm https://github.com/Vivicai1005/Step-Video-T2V.git
cd Step-Video-T2V
pip install -e .
Running Multi-GPU Parallel Inference on AMD Instinct GPUs#
Step-Video-T2V separates GPU workloads for optimal performance: the DiT module runs independently from text encoder embedding and VAE decoding, requiring dedicated GPUs for API services.
# Launch text encoder and VAE APIs
python api/call_remote_server.py --model_dir where_you_download_dir &
parallel=4 # Adjust according to GPU availability (e.g., parallel=8)
url='127.0.0.1'
model_dir=where_you_download_dir
tp_degree=2
ulysses_degree=2
# Ensure tp_degree * ulysses_degree equals parallel
torchrun --nproc_per_node $parallel run_parallel.py \
--model_dir $model_dir \
--vae_url $url \
--caption_url $url \
--ulysses_degree $ulysses_degree \
--tensor_parallel_degree $tp_degree \
--prompt "一名宇航员在月球上发现一块石碑,上面印有‘stepfun’字样,闪闪发光" \
--infer_steps 50 \
--cfg_scale 9.0 \
--time_shift 13.0
Summary#
Step-Video-T2V is a state-of-the-art video generation model. In this blog, we demonstrated how to run Step-Video-T2V efficiently on AMD Instinct™ MI300X GPUs using ROCm™, leveraging optimized components and multi-GPU parallelism. Through targeted code adaptations, we have enabled Step-Video-T2V to run efficiently on AMD GPUs, supporting multi-GPU inference. These modifications, inspired by DiffSynth-Studio, are part of our ongoing efforts to enhance video generation capabilities while maintaining strong compatibility with the AMD AI ecosystem and related frameworks.
Further Reading#
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.