Democratizing AI Compute with AMD Using SkyPilot#

Democratizing AI compute means making advanced infrastructure and tools accessible to everyone—empowering startups, researchers, and developers to train, deploy, and scale AI models without being constrained by proprietary systems or vendor lock-in. The AMD open AI ecosystem, built on AMD ROCm™ Software, pre-built optimized Docker images, and AMD Developer Cloud, provides the foundation for this vision.
Complementing this, we integrate with SkyPilot – an open-source, multi-cloud AI orchestration framework that enables developers to run LLMs, batch jobs, and distributed training seamlessly across clouds and Kubernetes clusters. With SkyPilot, migrating CUDA based AI workloads from NVIDIA to AMD GPU infrastructure across neoclouds—a new class of GPU-first cloud providers purpose-built for AI and HPC—requires minimal setup. This brings us closer to a truly open and democratized AI future.
Together, AMD and SkyPilot form a transparent, end-to-end AI stack — from open-source models and frameworks to low-level GPU acceleration — built by developers, for developers. This integration empowers AI engineers, researchers, and infrastructure teams to efficiently deploy and scale AI workloads across diverse environments, optimizing cost, performance, and scalability without vendor lock-in.
In this blog, we’ll show how to:
Launch AMD Instinct™ GPUs on AMD Developer Cloud and set up the Kubernetes with the AMD ROCm™ GPU operator.
Integrate SkyPilot for seamless orchestration with the AMD open AI ecosystem across neoclouds with BYOk8s and cloud-managed k8s.
Migrate workloads from NVIDIA to AMD GPU ecosystem with minimal configuration changes- often as simple as modifying two lines in the SkyPilot
YAMLfile.Enable workload mobility across heterogeneous AI neocloud environments to optimize cost, scalability, and availability.
Run workloads such as training models with PRIMUS, reinforcement learning using PyTorch, and inference serving using
vllm.
Multi-cloud + Multi-GPUs: The Challenge#
Scaling AI workloads introduces complexity. Training and inference jobs often demand:
Dynamic scaling to handle peak workloads.
Rapid GPU upgrades as new architectures emerge.
High availability across regions and vendors.
While the neoclouds or CSPs make GPU access easier, relying on a single vendor introduces:
Cost inefficiencies due to fluctuating supply and regional pricing.
Limited availability during peak demand.
Vendor lock-in prevents broader ecosystem utilization.
To achieve true flexibility, AI workloads must run across on-prem and neocloud infrastructure—with consistent performance and developer experience. However, each cloud introduces its own quirks and operational differences. As a result, engineers spend more time troubleshooting infrastructure instead of focusing on model optimization, faster convergence, and rapid deployment, slowing innovation and time-to-market.
The solution: a unified, multi-cloud and multi-vendor strategy that delivers scalability, resilience, and cost efficiency across AI workloads.
Enter SkyPilot#
SkyPilot is an open-source multi-cloud orchestration framework that abstracts infrastructure complexity. It allows developers to run LLMs, batch jobs, and distributed training across clouds and Kubernetes clusters using a single CLI and YAML file.
Key capabilities include:
Simplicity First: Define workloads in a single YAML file — SkyPilot handles resource, networking, and storage orchestration behind the scenes (see “AI on Kubernetes Without the Pain”).
Infrastructure-agnostic orchestration: Deploy workloads seamlessly across on-prem, cloud, and hybrid GPU clusters.
Cost-aware scheduling: Balance performance and cost across available infrastructure.
Developer-friendly interface: A single CLI and YAML workflow covers distributed training and batch jobs execution with minimal overheads.
Seamless portability: Move jobs between clusters without rewriting scripts; SkyPilot handles rerouting automatically.
Fault-tolerant execution: Built-in retry mechanisms ensure robust job execution.
AMD GPU support: SkyPilot now supports AMD Instinct GPUs.
By bridging multi-cloud orchestration and heterogeneous GPU environments, SkyPilot streamlines AI infrastructure management and accelerates deployment across open ecosystems.
AMD AI Ecosystem + SkyPilot#
The AMD open AI ecosystem spans from open-source models to low-level GPU functions and is enhanced by the AMD ROCm 7.0 enterprise-grade cluster management tools, enabling seamless orchestration, monitoring, and deployment of AI workloads across distributed GPU environments.
Integrating with SkyPilot provides:
Unified multi-cloud orchestration: Treat multiple Kubernetes clusters across clouds as a single compute fabric.
End-to-end visibility and control: Manage all compute resources across on-prem, cloud, or hybrid infrastructure.
Scalability and accessibility: Lower barriers for developers to build, train, and deploy models efficiently.

Figure 1: AMD open AI ecosystem + SkyPilot for multi-cloud orchestration.#
Figure 1 illustrates the integrated architecture of SkyPilot with the AMD AI ecosystem across Instinct enabled GPU clouds, serving as a visual guide to walk through the steps of deploying AI workloads.
Together, AMD and SkyPilot allow developers to run AI workloads on AMD Instinct GPUs using pre-built ROCm-optimized Docker images and even migrate CUDA-based NVIDIA workloads to AMD environments—effortlessly and transparently.
Getting Started with AMD Developer Cloud and SkyPilot#
This section provides a simplified walkthrough for launching AMD GPU resources on AMD Developer Cloud, configuring Kubernetes with the ROCm™ GPU Operator, and integrating SkyPilot for multi-cloud orchestration.
Launch AMD Instinct GPU and Configure Kubernetes
Begin by launching your AMD GPU virtual machines (VMs) on AMD Developer Cloud. For this setup, we use the configuration shown in Table 1 below:
Component |
Configuration |
|---|---|
Hardware |
8x AMD Instinct MI300X GPU VM |
Orchestrator |
1x AMD Instinct MI300X GPU VM (can also be CPU VM, desktop) |
Software |
k3s, Helm 3, SkyPilot |
GPU Operator |
AMD ROCm GPU operator v1.3.0 |
Table 1: Configuration used on AMD Developer Cloud
Use the onboarding guide for step-by-step instructions to launch and access the GPU VMs on the AMD Developer Cloud.
Once your GPU VMs are ready, follow the steps outlined below:
Install prerequisites and log in as a user with root privileges (see Appendix 1).
Set up Kubernetes:
For a lightweight option, use
k3s(refer to Appendix 2).Alternatively, bring your own Kubernetes (
BYOk8s) or choose a supported cloud-managed K8s service.
Deploy AMD GPU operator:
Install
helmfor Kubernetes management.Deploy the
amd-gpu-operatorto expose the GPU labels (amd.com/gpu)Refer to Appendix 3 for detailed instructions.
Install and Configure SkyPilot
Follow the instructions to install and label nodes for SkyPilot by referring to Appendix 4. Verify your setup:
sky check kubernetes
sky show-gpus --infra k8s
These commands validate SkyPilot’s connection to your Kubernetes cluster and automatically detect available AMD Instinct™ GPUs, as illustrated in Figure 2.

Figure 2: Sample Output - SkyPilot detecting AMD Instinct™ GPUs#
Run Sample Workloads on AMD GPUs
SkyPilot provides quick-start examples in skypilot/examples/amd with prebuilt ROCm-optimized Docker images and YAML examples for validating your setup and running real-world AI workloads on AMD Instinct GPUs.
a. Inference Serving with vLLM
vLLM provides efficient, high-throughput inference for large models, and pairs seamlessly with AMD Instinct MI300x GPUs. With 192GB of HBM3 memory, MI300x GPUs can host models like Mixtral 8x22B entirely in memory, eliminating the need for tensor or pipeline parallelism.
Deploy vLLM on AMD GPUs using SkyPilot with a single YAML configuration:
name: amd-vllm-inference
resources:
cloud: kubernetes
image_id: rocm/vllm:latest
accelerators: MI300:1
cpus: 16
memory: 64+
ports: 8000
envs:
HUGGINGFACE_HUB_CACHE: /workspace
VLLM_V1_USE_PREFILL_DECODE_ATTENTION: 1
MODEL_NAME: <model-name>
secrets:
HF_TOKEN: null # pass with '--secret HF_TOKEN'
setup: |
echo "AMD ROCm vLLM INFERENCE"
run: |
echo "Starting Inference Serving with vLLM on 1xAMD GPU"
vllm serve --model="<model-name>"
SkyPilot
YAMLfiles are simpler than traditional Kubernetes configurations (see SkyPilot vs vanilla-k8s YAML).
By abstracting infrastructure complexity, SkyPilot streamlines deployment. Users only need to define key resources-such as cloud, docker image_id, accelerators—along with the workflow steps under run.
Launch the inference serving job using:
sky launch -c <amd-inference-server> amd-vllm-inference.yaml --secret HF_TOKEN=<YOUR_HF_TOKEN_ID>
Query the vLLM service endpoint in a separate terminal by ssh <amd-inference-server> using the sample query below:
Sample Query
curl http://0.0.0.0:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "<model-name>",
"prompt": "Write a note on AMD ROCm",
"max_tokens": 128,
"top_p": 0.95,
"top_k": 20,
"temperature": 0.8
}'
This setup is ideal for developers seeking cost-effective, single-GPU deployments without sacrificing model size or responsiveness. Scaling to multi-GPU setups or larger models is as simple as updating the YAML file without requiring any additional steps.
Training a model with AMD PRIMUS
PRIMUS is the AMD modular and scalable training framework optimized for LLMs, optimized for AMD Instinct GPUs. It supports both single and multi-node distributed training with backend-agnostic support via Megatron-Core.
Training a model typically involves the following steps (see blogpost):
Set up the environment by pulling and launching the Docker container
Log in to the container, configure settings, and download datasets
Set the
HF_TOKENenvironment variable to access Hugging Face tokenizersRun sample training examples
With SkyPilot, all this can be achieved using a single YAML file, as shown below:
name: amd-rocm-primus
envs:
EXP: examples/megatron/configs/mixtral_8x7B_v0.1-pretrain.yaml
secrets:
HF_TOKEN: null # pass with '--secret HF_TOKEN'
resources:
cloud: kubernetes
image_id: docker:rocm/megatron-lm:v25.7_py310
accelerators: MI300:8
cpus: 128
memory: 512+
setup: |
echo "AMD PRIMUS TRAINING"
run: |
echo " rocm-smi smoke test:"
rocm-smi
# amd dockers can use their own conda environment
conda deactivate
cd /workspace/Primus
pip install -r requirements.txt
bash ./examples/run_pretrain.sh
rocm-smi
To launch PRIMUS with SkyPilot:
sky launch -c <amd-clusters> amd_primus.yaml --secret HF_TOKEN=<YOUR_HF_TOKEN_ID>
SkyPilot automatically provisions the required GPUs, pulls the ROCm-enabled PRIMUS docker image, installs dependencies, and runs pre-training tasks – all through a unified interface.
Once workloads are successfully launched on AMD GPUs with SkyPilot, the next step is learning how to transition existing AI workflows from NVIDIA infrastructure to AMD.
Seamless Migration From NVIDIA to AMD#
Many organizations operate heterogeneous GPU environments to reduce vendor lock-in and optimize cost, performance, and availability. However, migrating workloads between NVIDIA and AMD GPUs can be challenging due to differences in software stacks, drivers, and orchestration tools. SkyPilot simplifies this process by providing a unified, infrastructure-agnostic orchestration layer that allows developers to migrate CUDA-based NVIDIA workloads to AMD GPUs with minimal changes, often just a few lines in the YAML specification—while preserving performance and scalability across multi-cloud environments.
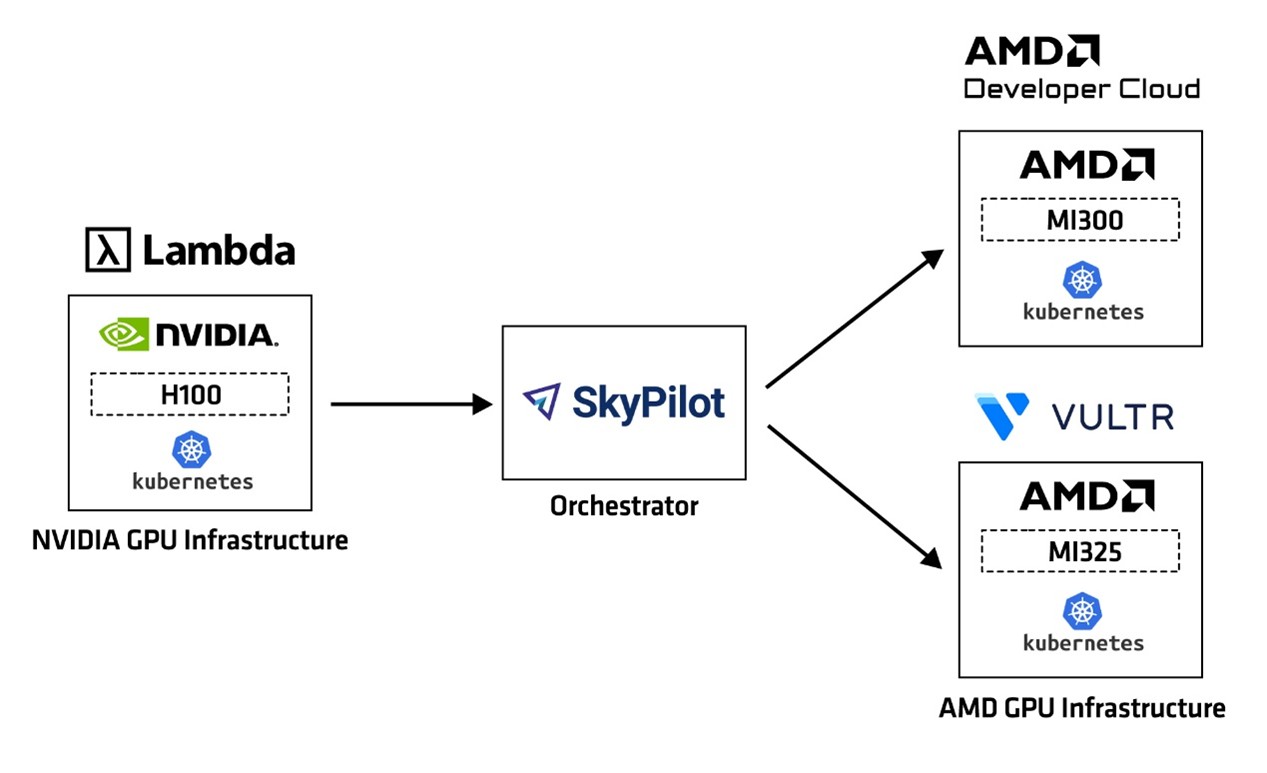
Figure 3: Testing Infrastructure: NVIDIA to AMD GPU infrastructure migration across neoclouds using SkyPilot#
Figure 3 illustrates a multi-cloud testing infrastructure spanning emerging AI neoclouds with the configuration details in Table 2. The testing infrastructure is designed to serve as a blueprint to demonstrate the ease of migration of workloads from NVIDIA to AMD GPUs using SkyPilot with minimal overhead.
Component |
NVIDIA H100 GPU Infrastructure |
AMD MI300X GPU Infrastructure |
AMD MI325X GPU Infrastructure |
|---|---|---|---|
AI Cloud |
|||
Hardware |
4×H100 GPU VM |
8×MI300X GPU VM |
32×MI325X GPU VM |
Software |
BYOk8s (k3s), Helm 3, NVIDIA GPU operator |
BYOk8s (k3s), Helm 3, AMD GPU operator |
Managed k8s |
Table 2: Multi-cloud Testing Infrastructure
Configuring Multi-cloud Kubernetes Access#
To configure a multi-cloud Kubernetes environment for seamless AI workload orchestration using SkyPilot, follow these steps:
SkyPilot Orchestrator Machine
This is the orchestration machine which needs access to all other k8s clusters across clouds. Could be any compute machine with CPUs.
Install
kubectlandSkyPilotand ensure all prerequisites are met (see Appendix 1).
AMD Instinct MI300X GPU Cluster (AMD Developer Cloud)
Provision the MI300X cluster (see setup guide)
Copy the
kubeconfigto the orchestrator node:
scp <usr>@<amd-devcloud-k8s-ip-address>:</path/to/kubeconfig> $HOME/.kube/amd-mi300-devcloud-kubeconfig
sed -i "s/127.0.0.1/$<amd-devcloud-k8s-ip-address>/g" $HOME/.kube/amd-mi300-devcloud-kubeconfig
NVIDIA H100 GPU Cluster (Lambda cloud)
Follow the tutorial to set up the Lambda account, configure firewall settings, and install prerequisites on the orchestrator node.
Use the following scripts to deploy the NVIDIA k8s cluster with
4xH100on Lambda cloud, and generate a copy of the kubeconfig file at$HOME/.kube/nvidia-h100-lambda-kubeconfig
bash launch_k8s_lambda.sh
AMD MI325X GPU Infrastructure (Vultr cloud)
Use the managed kubernetes service (
kubeconfigprovided)Alternatively, set up a BYOk8s environment (see Appendix 2).
Copy the
kubeconfigfiles into the orchestrator node to enable multi-cluster orchestration.
Merge Kubernetes Contexts for Multi-Cluster Access
Combine all kubeconfig files into one consolidated $HOME/.kube/config (see SkyPilot multi-cluster set-up guide).
amd-mi300-devcloud-kubeconfig (AMD MI300 on AMD Developer Cloud)amd-mi325-vultr-kubeconfig (AMD MI325 on Vultr Cloud)nvidia-h100-lambda-kubeconfig (NVIDIA H100 on Lambda Cloud)Consolidated sample kubeconfig
apiVersion: v1 clusters: - cluster: certificate-authority-data: ... server: https://<amd-devcloud-k8s-mi300-ip-address>:6443 name: amd-devcloud - cluster: certificate-authority-data: ... server: https://<amd-vultrcloud-k8s-mi325-ip-address>:6443 name: cluster.local - cluster: insecure-skip-tls-verify: true server: https://<nvidia-lambda-k8s-h100-ip-address>:6443 name: default contexts: - context: cluster: amd-devcloud user: amd-devcloud name: amd-devcloud-k8s-mi300 - context: cluster: cluster.local user: kubernetes-admin name: amd-vultrcloud-k8s-mi325 - context: cluster: default user: default name: nvidia-lambdacloud-k8s-h100 current-context: amd-vultrcloud-k8s-mi325 kind: Config preferences: {} users: - name: amd-devcloud user: client-certificate-data: ... client-key-data: ... - name: default user: client-certificate-data: ... client-key-data: ... - name: kubernetes-admin user: client-certificate-data: ... client-key-data: ...
Set the
KUBECONFIGenvironment variable
export KUBECONFIG=$HOME/.kube/config
Enable Multi-Cluster Access in SkyPilot
To allow SkyPilot to orchestrate across multiple Kubernetes clusters, update the configuration file at $HOME/.sky/config.yaml by adding the following:
kubernetes:
allowed_contexts:
- amd-vultrcloud-k8s-mi325
- amd-devcloud-k8s-mi300
- nvidia-lambdacloud-k8s-h100
Validate multi-cluster access
sky check k8s
sky show-gpus --infra k8s
Figure 4 shows a sample SkyPilot output listing the expected GPU type and quantity for each Kubernetes context.

Figure 4: Example validation output for multicloud testing setup#
With the multi-cloud Kubernetes configuration complete, the next step is to validate workload migration from NVIDIA to AMD infrastructure across neoclouds through a simple demo
Demo: Migrating PyTorch Reinforcement Learning Workload#
To demonstrate the migration from NVIDIA to AMD GPU infrastructure, we use a standard PyTorch Reinforcement Learning example using a single SkyPilot YAML file.
name: migration-pytorch-rl
resources:
cloud: kubernetes
image_id: <docker-image>
accelerators: <accelerator-type>:<no. of accelerators>
cpus: 96
memory: 128+
setup: |
echo "Reinforcement Learning example derived from https://github.com/pytorch/examples"
sleep 5
run: |
conda deactivate
git clone https://github.com/pytorch/examples.git
cd examples/reinforcement_learning
pip install -r requirements.txt
sleep 5
echo "Running reinforce example..."
python3 reinforce.py
echo "Running actor_critic example..."
python3 actor_critic.py
echo "Reinforcement Learning completed successfully."
This single YAML replaces multiple complex Kubernetes manifests—covering resource allocation, container setup, and service definitions—and can be reused across heterogeneous platforms with minimal changes.
To run the workflow on NVIDIA Infrastructure, simply update the YAML spec by specifying the NVIDIA docker image-image_id: nvcr.io/nvidia/pytorch:25.08-py3 and number of H100 accelerators to use-accelerators: H100:1.
Then, launch the job and provision the cluster directly from the SkyPilot orchestrator using:
sky launch -c <cluster-name> migration-pytorch-rl.yaml
Running on AMD Infrastructure#
Simply update the image to an AMD ROCm-compatible Docker container- image_id: docker:rocm/pytorch:latest. SkyPilot automatically selects the appropriate cloud and provisions the required GPUs based on the accelerator type specified - here, MI300 or MI325.
Refer to Appendix 5 for feature set comparisons and cross-compatible container platforms for workload migration between NVIDIA and AMD.
Watch how SkyPilot makes multi-cloud migration seamless!
This demo shows how workloads running on NVIDIA GPUs can be effortlessly migrated to AMD Instinct GPUs across neocloud environments—and even upgraded across different AMD GPU tiers—by updating just a few lines in the SkyPilot YAML file.
By abstracting environment-specific complexities, SkyPilot automatically discovers available GPUs, provisions resources, and launches jobs—streamlining deployment across heterogeneous infrastructure. This enables AI developers to migrate workloads across multi-cloud environments with minimal changes and reduced operational overhead, without worrying about infrastructure complexities.
Summary#
As AI adoption accelerates, democratizing access to high-performance compute is critical. Proprietary stacks and single-cloud reliance often lead to cost inefficiencies and vendor lock-in, limiting scalability and innovation.
The AMD Open AI Ecosystem, built on the ROCm software stack, and open-source frameworks, enables developers to run AI workloads—from training to inference—on AMD Instinct GPUs across on-prem, hyperscalers, and emerging neoclouds.
SkyPilot, an open-source multi-cloud orchestration framework, complements this vision by simplifying deployment of LLMs, batch jobs, and distributed training across heterogeneous environments. With automatic GPU discovery and seamless migration from NVIDIA to AMD (just two config changes), SkyPilot makes multi-cloud AI practical and cost-effective.
The AMD + SkyPilot integration unlocks a simple-yet-powerful platform—built by developers, for developers—that empowers developers to train, deploy, and migrate workloads effortlessly across GPU architectures and cloud providers—all through a unified interface. This integration accelerates innovation, lowers barriers to entry, and redefines AI infrastructure at scale.
We invite the developer community to try the SkyPilot + AMD integration, explore the quick-start examples, and share feedback to help shape the next generation of open AI infrastructure.
Get started today:
Visit SkyPilot GitHub
Explore AMD Developer Cloud for ROCm-optimized GPU instances
Join the AMD Discord community to connect with fellow AMD developers.
Contact us directly at ai_innovations@amd.com to share feedback, get hands-on support, and explore collaboration opportunities.
Appendix 1. Prerequisites#
Before getting started, it is recommended to check for the pre-requisites outlined below.
By default, the AMD Developer Cloud logs you as root. It is recommended to add a user, e.g.,
amd-userwith root privileges.
a. Instructions to add a user with root privileges
# login as root
$ ssh root@<Public IP Address>
$ adduser amd-user
# create passwordless login
$ visudo /etc/sudoers
# add the following line to /etc/sudoers
amd-user ALL=(ALL:ALL) NOPASSWD:ALL
You may need to restart the ssh service and log in as amd-user.
b. Ensure the following packages are installed before proceeding:
sudo apt-get update
sudo apt-get install pip
sudo apt-get install snapd
sudo apt-get install socat
sudo apt-get install netcat-traditional
sudo apt-get install -y apt-transport-https ca-certificates curl gpg
TCP ports 6443, 443, 8000 need to be open for traffic. You can use
sudo ufw allow <port-no>/tcpto open the ports.
c. Install conda environment
curl -O https://repo.anaconda.com/archive/Anaconda3-2025.06-0-Linux-x86_64.sh
bash Anaconda3-2025.06-0-Linux-x86_64.sh
source ~/.bashrc
source ~/anaconda3/etc/profile.d/conda.sh
source ~/.bashrc
conda -V
Appendix 2. BYOk8s setup with k3s#
For k3s installation, follow the instructions outlined in k3s installation guide or use the sample installation steps shown below:
a. K3s installation procedure
curl -sfL https://get.k3s.io | sh –
# verify status of installation
systemctl status k3s
# create sym-link - k3s yaml with $HOME/.kube/config
mkdir -p $HOME/.kube
ln -s /etc/rancher/k3s/k3s.yaml $HOME/.kube/config
sudo chmod 755 $HOME/.kube/config
export KUBECONFIG=$HOME/.kube/config
# enable k3s service
sudo systemctl enable k3s
SkyPilot expects the k8s config file at
$HOME/.kube/config.
Optionally, you may have to remove other accelerator runtime.
kubectl delete runtimeclasses.node.k8s.io nvidia nvidia-experimental
If using a separate orchestrator machine for k8s, install kubectl and the kubeconfig should point to the public ip-address of the k8s cluster:
# install kubectl on the orchestrator machine
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
sudo install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl
# copy remote kubeconfig to $HOME/.kube/config
scp amd-usr@<k8s-ip-address>:/etc/rancher/k3s/k3s.yaml $HOME/.kube/config
#point to public-ip-address
sed -i "s/127.0.0.1/$<k8s-ip-address>/g" $HOME/.kube/config
export KUBECONFIG=$HOME/.kube/config
b. Verify the k8s status:
kubectl get nodes
Appendix 3. AMD GPU Operator Installation#
Here we use amd-gpu-operator v1.3.0, please refer to ROCm amd-gpu-operator Github for latest updates and installation procedure.
Install Helm
curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash
Install cert-manager
helm repo add jetstack https://charts.jetstack.io --force-update
helm install cert-manager jetstack/cert-manager \
--namespace cert-manager \
--create-namespace \
--version v1.15.1 \
--set crds.enabled=true
Add AMD GPU operator Helm repo
helm repo add rocm https://rocm.github.io/gpu-operator
helm repo update
Install AMD GPU operator
helm install amd-gpu-operator rocm/gpu-operator-charts \
--namespace kube-amd-gpu --create-namespace \
--version=v1.3.0 \
--set-json 'deviceConfig.spec.selector={"feature.node.kubernetes.io/amd-gpu":null,"feature.node.kubernetes.io/amd-vgpu":"true"}'
Please note: Different clouds/clusters expose GPUs through different interfaces. The AMD Developer Cloud exposes the GPUs as vGPUs, therefore "feature.node.kubernetes.io/amd-vgpu" is set as "true".
For the AMD Developer Cloud setup in Table 1, this should expose
amd.com/gpulabel with the required GPU count (e.g.,8).
Verify amd-gpu-operator installation
kubectl get all --namespace kube-amd-gpu
Check for AMD GPU Labels
kubectl get nodes -o json | jq '.items[] | {name: .metadata.name, labels: .metadata.labels}' | grep -e "amd.com/gpu"
Check Node Capacity
kubectl get nodes -o json | jq '.items[] | {name: .metadata.name, capacity: .status.capacity}'
Appendix 4. Install SkyPilot and Label Nodes#
SkyPilot now supports AMD Instinct GPUs (refer: link).
a. SkyPilot installation instructions:
Install SkyPilot by following the official procedure guide.
Alternatively, follow the step-by-step instructions:
conda create -y -n <amd-user> python=3.10 conda activate amd-user # install skypilot and choose the infrastructure pip install ''skypilot[kubernetes]''
b. Labeling of nodes for SkyPilot:
Switch to the correct context in-case there are more than one:
kubectl config use-context <context-name>
# find the nodes to be labelled
kubectl get nodes
For the AMD Developer Cloud, we use the MI300 accelerator, so the node is labeled as skypilot.co/accelerator=mi300. Similarly, for the Vultr k8s cluster using MI325 GPUs, nodes are labeled as skypilot.co/accelerator=mi325.
SkyPilot expects accelerators or nodes to be labeled using the following convention:
skypilot.co/accelerator=<accelerator-name>
Use the following command to label the respective nodes:
kubectl label node <node-name> skypilot.co/accelerator=<accelerator-name>
Verify labels for skypilot.co/accelerator:
kubectl get nodes -o json | jq '.items[] | {name: .metadata.name, labels: .metadata.labels}' | grep -e "skypilot.co/accelerator"
Appendix 5. NVIDIA to AMD Migration Guide#
The table below is adapted from the NVIDIA to AMD migration guide.
Table 3: Feature Comparison: NVIDIA Docker vs AMD Container Toolkit
Feature |
NVIDIA Docker |
AMD Container Toolkit |
|---|---|---|
GPU Enumeration |
|
|
Container Runtime |
|
|
Environment Variable |
|
|
Framework Images |
NVIDIA-specific images optimized for CUDA. |
ROCm-optimized images designed for AMD GPUs. |
TensorFlow Support |
CUDA TensorFlow – Supports TensorFlow operations on NVIDIA GPUs. |
ROCm TensorFlow – Optimized TensorFlow builds for AMD GPUs. |
PyTorch Support |
CUDA PyTorch – Optimized for NVIDIA architectures. |
ROCm PyTorch – Optimized for AMD Instinct architectures. |
Configuration Toolkit |
|
|
Default Docker Runtime |
|
|
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.