AITER-Enabled MLA Layer Inference on AMD Instinct MI300X GPUs#

For developers pushing LLM inference to its limits, efficiency and speed are non-negotiable. DeepSeek-V3’s Multi-head Latent Attention (MLA) layer rethinks traditional attention to cut memory bandwidth pressure while maintaining accuracy. Combined with the matrix absorbed optimization and AMD’s AI Tensor Engine for ROCm (AITER), this can deliver up to 2X faster inference on AMD Instinct™ MI300X GPUs compared to non-AITER runs.
In this blog, we’ll explain how MLA works, walk through the matrix absorption optimization, and show code-level steps to reproduce these performance gains.
Overview of MHA and MLA Layer Architecture#
Multi-head attention (aka. MHA) layer projects input hidden states into queries (q_proj), keys (k_proj), and values (v_proj), applies rotary positional embeddings (RoPE) to queries/keys, and updates the KV cache for efficient inference. The attention outputs from multiple heads are combined via o_proj to produce the result. This parallelized design captures diverse contextual relationships as shown in Figure 1. This design is powerful but can be memory-bandwidth heavy and less efficient for large-scale GPU inference.
Figure 1. MHA layer structure#
The MLA layer rethinks MHA by introducing low-rank projections and a two-path architecture to improve efficiency. Let’s split the MLA architecture into two paths as shown in Figure 2, one is the query path, the other is the key-value path.
1. Query Path:
Projections: Input hidden states are split and processed through two low-rank projections (
q_proj_downandq_proj_up), decomposing the query into a smaller latent space.Non-Positional (
q_nope) & RoPE: The projected query is divided into two components:Non-positional (
q_nope): Standard attention head features.Rotary Positional Embedding (RoPE) (
q_rope): Adds position-awareness via rotation.
Concatenation:
q_nopeandq_ropeare combined to form the final query.
2. Key-Value Path:
Projections: Similar to the query path, KV states undergo low-rank projection (kv_proj_down).
RoPE for Keys: Keys receive positional encoding via RoPE (k_rope).
KV Cache Update: The projected keys/values are concatenated and stored in a KV Cache buffer space
Up-Projection: Cached KV states are later up-projected (kv_proj_up) for attention computation.
Once the q and kv are ready, we can invoke attention and output projection:
Multi-Head Attention (MHA): Uses the fused query (Q) and up-projected KV states to compute attention scores. You might wonder why MHA is still present—this will be clarified in the “MLA Layer with Matrix Absorbed” section, where equivalent transformations are applied for improved performance.
Output Projection (o_proj): A final linear layer that aggregates head outputs into the hidden dimension.
Figure 2. MLA layer structure#
The MLA layer rethinks MHA by introducing low-rank projections and a two-path architecture to improve efficiency:
Multi-Query Shared Projections: MLA layer shares key-value (KV) projections across attention heads, significantly reducing memory bandwidth pressure—a critical bottleneck in GPU-accelerated inference. This design is especially advantageous for minimizing redundant memory reads/writes.
Latent Low-Rank Adaptation (LoRA): By decomposing query/key/value projections into low-rank matrices (e.g., via q_lora_rank and kv_lora_rank), MLA reduces parameter counts without sacrificing expressiveness. Coupled with Rotary Positional Embedding (RoPE), it maintains positional awareness while enabling hardware-friendly fused operations.
These innovations make MLA particularly suited for deployment on AMD Instict MI300X GPUs, where optimized kernels (e.g., via aiter’s tuned gemm and mla_decode_fwd) can exploit matrix cores and high-bandwidth memory.
MLA Layer with Matrix Absorbed#
Having an MLA layer alone isn’t enough—we need an optimized MLA layer, specifically the MLA layer with matrix absorbed mentioned earlier. As shown in Figure 3, we followed the SGLang implementation, which illustrates the architecture of this optimized MLA layer. This design allows us to execute MQA (multi-query attention) instead of MHA (multi-head attention), and AMD’s AI Tensor Engine for ROCm (AITER) includes an optimized kernel specifically for this MQA setup.
The key changes are splitting the kv_proj_up weight into two parts, as shown on the left side of figure 3: one is Wuk, which is absorbed into q_nope (the output of q_proj_up), the other is Wuv, which is absorbed into the attention output.
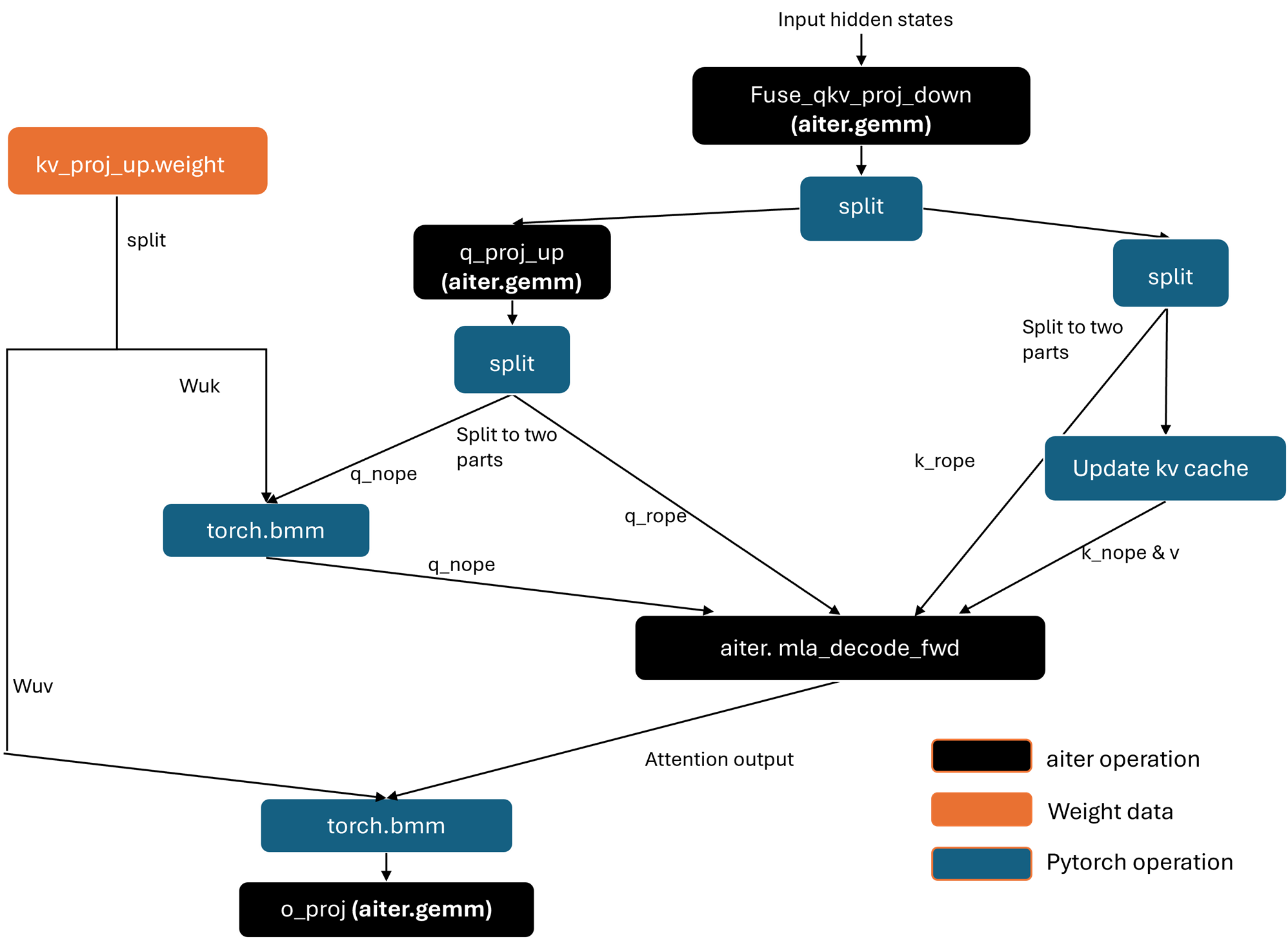
Figure 3. MLA layer with matrix absorbed#
Boosting MLA layer with matrix absorbed by AITER#
In this section, we will show how to build MLA layer with matrix absorbed boosted by the AITER library, you can follow our code snippets to reproduce it step-by-step.
Prerequisites#
Ensure that you have the following setup:
Linux: see the supported Linux distributions.
ROCm 6.3+: see the installation instructions.
MI300X GPUs: Configure the scripts and hyperparameters
Create a ROCm PyTorch docker container:
docker run -it --rm \
--network=host \
--device=/dev/kfd \
--device=/dev/dri \
--group-add=video \
--ipc=host \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
--shm-size 8G \
-v $(pwd):/workspace \
-w /workspace \
rocm/pytorch:latest
Manually install AITER by:
```shell
git clone --recursive https://github.com/ROCm/aiter.git
cd aiter
python3 setup.py develop
export PYTHONPATH=$PYTHONPATH:/workspace/aiter```
Note: There are many cutting-edge features that you can enjoy. If you are running in your own environment, don’t forget to set the PYTHONPATH accordingly.
Step 1: Import Dependent Packages#
We need to import dependent packages and set up the device properly.
import torch
from torch import nn
from dataclasses import dataclass
from aiter.tuned_gemm import tgemm
from aiter.mla import mla_decode_fwd
device = "cuda" if torch.cuda.is_available() else "cpu"
Step 2: Define Configurations#
We need to define the parameters as mentioned below:
Parameter |
Description |
|---|---|
|
Number of input sequences processed in a single forward pass. |
|
Length of the query sequence for the current step. |
|
Total length of the context (past + present tokens). |
|
LoRA down-projection dimension for the query projection ( |
|
LoRA down-projection dimension for the key/value projections ( |
|
Dimension size of Q/K features without positional encoding. |
|
Dimension size of Q/K features using RoPE (Rotary Positional Embedding). |
|
Head dimension size for value projections ( |
|
Maximum sequence length supported for applying RoPE. |
|
Data type for input and output tensors (e.g., |
@dataclass
class Config:
bs: int
sq: int
sk: int
hidden_size: int
num_attention_heads: int
q_lora_rank: int
kv_lora_rank: int
qk_nope_head_dim: int
qk_rope_head_dim: int
v_head_dim: int
max_position_embeddings: int
torch_dtype: torch.dtype
Step 3: Define Customized Linear#
We now need to customize the linear layers using AITER, which will be used to compute all linear modules in the MLA layer:
class CustomizedLinear(nn.Module):
def __init__(self, input_size, output_size, dtype=None):
super(CustomizedLinear, self).__init__()
self.weight = torch.randn((output_size, input_size), dtype=dtype, device=device)
def forward(self, x):
return tgemm.mm(x, self.weight)
Step 4: Define KVCache#
The KVCache class stores KV data and updates it during each decode iteration, as shown below:
class KVCache(nn.Module):
def __init__(self, kv_cache_shape: tuple, **kwargs) -> None:
super().__init__(**kwargs)
self.register_buffer('data', torch.zeros(kv_cache_shape, dtype=torch.bfloat16))
self.seq_len = 0
def get_data(self) -> torch.Tensor:
return self.data
def forward(self, c_kv: torch.Tensor) -> torch.Tensor:
assert self.seq_len + c_kv.size(1) <= self.data.size(1), "KV Cache Exceeded"
self.data = self.data.to(c_kv.dtype)
self.data[
:, self.seq_len : self.seq_len + c_kv.size(1), :
] = c_kv
self.seq_len += c_kv.size(1)
return self.data, self.data[:, :self.seq_len], self.seq_len
Step 5: Define DeepSeek MLA Layer With Matrix Absorbed#
Up to this point, we’re ready to define the DeepSeek MLA Layer class with matrix absorbed. In the implementation, we initialize the variables and linear modules using our AITER-customized linear layers. Additionally, several indices and index pointers are defined at the end of the code snippet—these will be explained in detail later.
class DeepseekAttention(nn.Module):
def __init__(self, config: Config):
super().__init__()
q_head_dim = config.qk_nope_head_dim + config.qk_rope_head_dim
self.hidden_size = config.hidden_size
self.num_heads = config.num_attention_heads
self.q_lora_rank = config.q_lora_rank
self.kv_lora_rank = config.kv_lora_rank
self.qk_rope_head_dim = config.qk_rope_head_dim
self.qk_nope_head_dim = config.qk_nope_head_dim
self.q_head_dim = q_head_dim
self.v_head_dim = config.v_head_dim
self.torch_dtype = config.torch_dtype
self.q_a_proj = CustomizedLinear(config.hidden_size, config.q_lora_rank, dtype=config.torch_dtype)
self.q_b_proj = CustomizedLinear(config.q_lora_rank, config.num_attention_heads * q_head_dim, dtype=config.torch_dtype)
self.kv_a_proj_with_mqa = CustomizedLinear(config.hidden_size, config.kv_lora_rank + config.qk_rope_head_dim, dtype=config.torch_dtype)
self.kv_b_proj = CustomizedLinear(config.kv_lora_rank, config.num_attention_heads * (config.qk_nope_head_dim + config.v_head_dim), dtype=config.torch_dtype)
self.o_proj = CustomizedLinear(config.num_attention_heads * config.v_head_dim, config.hidden_size, dtype=config.torch_dtype)
self.bs = config.bs
self.sk = config.sk
self.sq = config.sq
self.qo_indptr = torch.zeros(self.bs + 1, dtype=torch.int, device=device)
self.kv_indptr = torch.zeros(self.bs + 1, dtype=torch.int, device=device)
self.seq_lens_qo = torch.empty(self.bs, dtype=torch.int, device=device).fill_(1)
self.seq_lens_kv = torch.empty(self.bs, dtype=torch.int, device=device).fill_(self.sk)
self.kv_last_page_lens = torch.ones(self.bs, dtype=torch.int, device=device)
self.kv_indptr[1 : self.bs + 1] = torch.cumsum(self.seq_lens_kv, dim=0)
self.kv_indices = torch.randint(0, 2097152, (self.kv_indptr[-1].item(),), dtype=torch.int, device=device)
self.qo_indptr[1 : self.bs + 1] = torch.cumsum(self.seq_lens_qo, dim=0)
Below is a detailed explanation of the last six variables:
qo_indptr: A torch.Tensor pointer that marks the start address of each query and output sequence. Its shape requirement is [batch_size + 1]. When sequence lengths vary across a batch, qo_indptr records the offsets, ensuring that each sequence is correctly accessed.
kv_indptr: A torch.Tensor pointer that marks the start address of each context/Key-Value (KV) sequence. Its shape requirement is [batch_size + 1]. Since query and answer sequence lengths can differ across a batch, kv_indptr records these offsets to correctly access the KV sequences corresponding to each query.
seq_lens_qo: A torch.Tensor representing the sequence length of each query. In this case, the value is 1 for all sequences.
seq_lens_kv: A torch.Tensor representing the context length for each query. Here, it is set to self.sk for all sequences.
kv_indices: A torch.Tensor containing the concrete start indices of each KV sequence. Its shape requirement is [kv_indptr[-1]].
kv_last_page_lens: A torch.Tensor representing the last page size of each sequence. Its shape requirement is [batch_size].
The RoPE logic is inside DeepseekAttention class, this is a common part, so we skip it.
class DeepseekAttention(nn.Module):
def __init__(self, config: Config):
......
def rotate_half(self, x: torch.Tensor) -> torch.Tensor:
x1, x2 = x.chunk(2, dim=-1)
return torch.cat((-x2, x1), dim=-1)
def apply_rotary_emb(self, x: torch.Tensor, theta: torch.Tensor, start_pos: int = 0) -> torch.Tensor:
seq_len = x.size(-3)
seq_idx = torch.arange(start_pos, start_pos + seq_len, device=x.device)
idx_theta = torch.einsum('s,d->sd', seq_idx, theta)
idx_theta2 = torch.cat([idx_theta, idx_theta], dim=-1)
cos = idx_theta2.cos().to(torch.bfloat16).unsqueeze(1)
sin = idx_theta2.sin().to(torch.bfloat16).unsqueeze(1)
return x * cos + self.rotate_half(x) * sin
We can now begin constructing the MLA layer with matrix absorption. The computation logic for the MLA layer has been divided into six sub-steps, in line with the “MLA layer with matrix absorbed” section.
First, handle q down and up projection then split into rope part and non-rope part.
Second, handle kv down and up projection and update the result into kv cache.
Third, invoke RoPE operation for q and k.
Fourth, split kv up projection weight into two parts and absorb first part into q nope part, then combine q nope part and q rope part into one total q_input tensor.
Fifth, invoke the mla decode attention kernel using AITER library and get the result into out_asm variable.
Finally, apply the second part of kv up projection weight absorbed for attention output and invoke output projection linear to get the output of attention module.
class DeepseekAttention(nn.Module):
......
def forward(self, hidden_states_q: torch.Tensor, hidden_states_kv: KVCache):
### step1: handle q down and up projection
bsz, q_len, _ = hidden_states_q.size()
q = self.q_b_proj(self.q_a_proj(hidden_states_q))
q = q.view(bsz, q_len, self.num_heads, self.q_head_dim)#.transpose(1, 2)
q_nope, q_pe = torch.split(
q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1
)
## step2: handle kv down projection and update kv cache
kv = self.kv_a_proj_with_mqa(hidden_states_q)
total_kv, kv, kv_len = hidden_states_kv(kv)
_, k_rope = torch.split(kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1)
total_kv = total_kv.view(16384*128, kv.shape[-1]).unsqueeze(1).unsqueeze(1)
## step3: invoke q rope and k rope
q_pe = self.apply_rotary_emb(q_pe, theta, start_pos=kv_len - 1)
k_rope = self.apply_rotary_emb(k_rope.unsqueeze(2), theta)
## step4: split up projection weight into two parts and absorb first part into q nope
kv_b_proj = self.kv_b_proj.weight.view(self.num_heads, -1, self.kv_lora_rank)
q_absorb = kv_b_proj[:, :self.qk_nope_head_dim,:]
out_absorb = kv_b_proj[:, self.qk_nope_head_dim:, :]#128 128 512
q_nope = q_nope.view(bsz*q_len, self.num_heads, self.qk_nope_head_dim)
q_nope = torch.bmm(q_nope.transpose(0,1), q_absorb) #[128,2,512]
q_input = torch.empty(bsz*q_len, self.num_heads, self.kv_lora_rank + self.qk_rope_head_dim, dtype=torch.bfloat16, device=device)
q_input[..., : self.kv_lora_rank] = q_nope.transpose(0, 1)
q_input[..., self.kv_lora_rank:] = q_pe.view(bsz*q_len, self.num_heads, self.qk_rope_head_dim)
## step5: invoke mla decode attention kernel using AITER
out_asm = torch.empty((self.bs*self.sq, self.num_heads, self.kv_lora_rank), dtype=self.torch_dtype, device=device).fill_(-1)
mla_decode_fwd(
q_input,
total_kv,
out_asm,
self.qo_indptr,
self.kv_indptr,
self.kv_indices,
self.kv_last_page_lens,
1,
sm_scale= 1.0 / (self.q_head_dim**0.5),
)
## step6: apply absorb for attention output and invoke output projection linear
attn_output = torch.bmm(out_asm.transpose(0, 1), out_absorb.mT).view(bsz, -1)
attn_output = self.o_proj(attn_output)
return attn_output
Step 6: Generate Input Data and Execution#
We are now ready to generate input data and pass it into the DeepSeekAttention class, so you can experience the performance acceleration of the MLA layer powered by the AITER library.
def generate_input(bs, sq, sk, hidden_size, seed):
config = Config(
bs=bs,
sq=sq,
sk=sk,
hidden_size=hidden_size,
num_attention_heads=128,
q_lora_rank=1536,
kv_lora_rank=512,
qk_nope_head_dim=128,
qk_rope_head_dim=64,
v_head_dim=128,
max_position_embeddings=8192,
torch_dtype=torch.bfloat16
)
gen = torch.Generator(device=device)
gen.manual_seed(seed)
x = torch.randn((bs, sq, hidden_size), dtype=torch.bfloat16, generator=gen, device=device)
kv_cache = KVCache((config.bs, 16384, config.kv_lora_rank + config.qk_rope_head_dim)).to(device)
x_kv = torch.randn((config.bs, config.sk, 576), dtype=torch.bfloat16, generator=gen, device=device)
kv_cache(x_kv)
return config, x, kv_cache
def mla(data):
config, x, kv_cache = data
model = DeepseekAttention(config)
import time
for _ in range(10):
output = model(x, kv_cache)
sum = 0
for i in range(30):
torch.cuda.synchronize()
start = time.perf_counter()
output = model(x, kv_cache)
torch.cuda.synchronize()
end = time.perf_counter()
sum += end -start
torch.cuda.synchronize()
avg = sum / 30
print("time is ", avg)
return output
Performance Benchmarking#
We conducted experiments on the MLA layer with matrix absorption, both with and without the AITER library, across different batch sizes and context lengths.
For batch sizes of 1, 64, 128, 256, and 512 with a fixed context length of 1024, as shown in Figure 4, the MLA layer using AITER consistently outperforms the version without AITER, delivering competitive absolute elapsed times. The speedup is also notable, Figure 5 shows that as the batch size increases, AITER provides significant acceleration, reaching up to 1.47X.
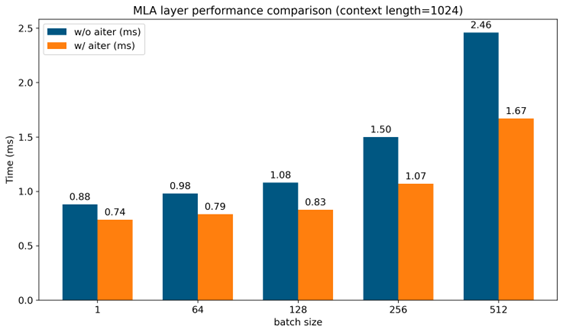
Figure 4. Performance comparison with AITER vs. without AITER under various batch sizes [1]#
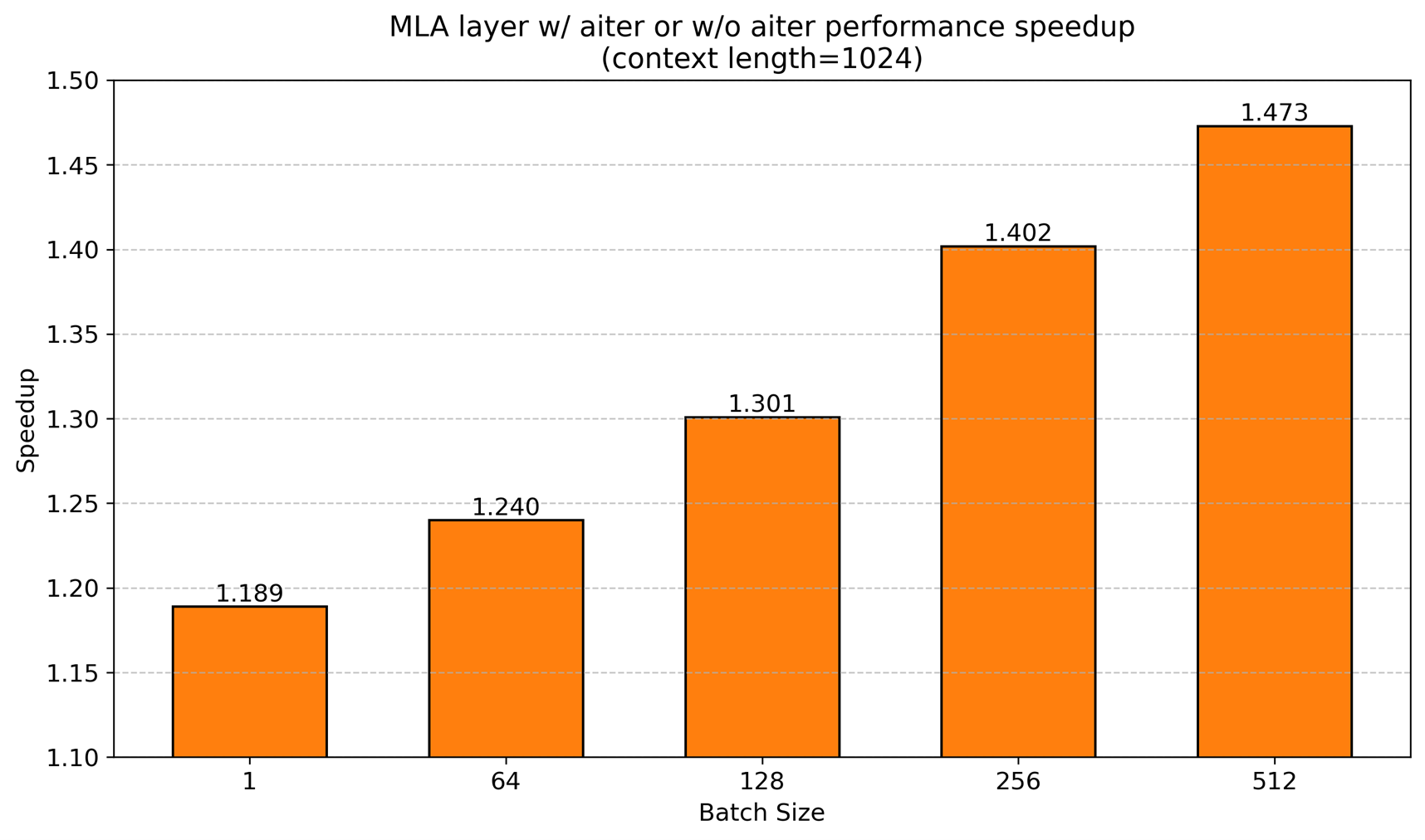
Figure 5. Performance speedup with AITER vs. without AITER under various batch sizes [2]#
For a fixed batch size of 128 and context lengths of 1024, 2048, 4096, 6144, and 8192, the MLA layer with matrix absorption using AITER also delivers competitive absolute elapsed times compared to runs without AITER, as shown in Figure 6.
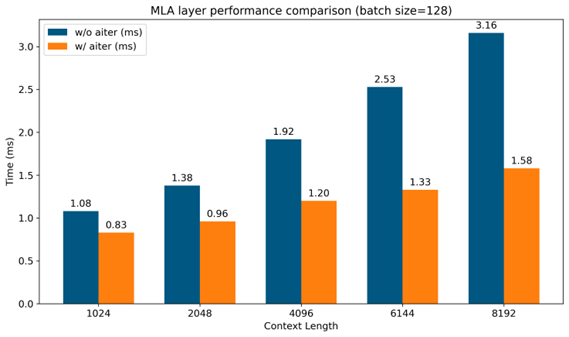
Figure 6. Performance comparison with AITER vs. without AITER under various length [3]#
The speedup ratio is even higher, as shown in Figure 7: as context length increases, AITER delivers stronger acceleration, up to 2x:
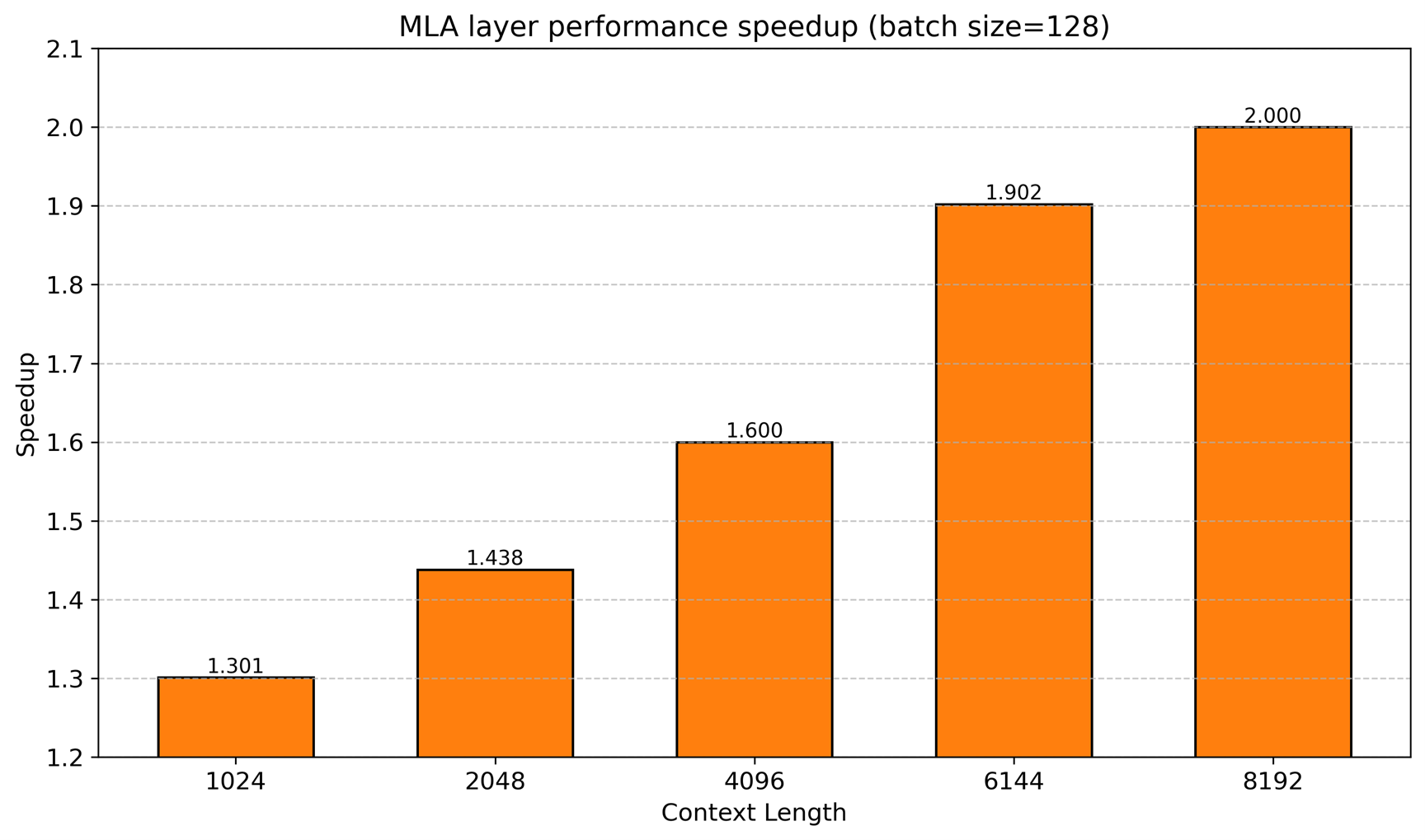
Figure 7. Performance speedup with AITER vs. without AITER under various length [1]#
Summary#
DeepSeek-V3’s Multi-head Latent Attention (MLA) layer, with low-rank projections, shared KV paths, and rotary embeddings, efficiently reduces memory bandwidth while maintaining model accuracy. Leveraging AMD’s AI Tensor Engine for ROCm (AITER) with matrix absorption delivers up to 2× faster inference on AMD Instinct™ GPUs, unlocking their full potential for LLM workloads. Developers can use these optimizations to accelerate their own models, experiment with high-performance inference, and contribute insights to further improve the ecosystem.
Stay tuned for more features and optimizations in upcoming releases!
References#
Configuration Details#
Hardware: AMD Instinct™ MI300X GPUs. Software: AITER v0.1.4, ROCm v6.4.0, PyTorch v2.6.0. Input configuration: batch size = [1,64,128,256,512], context length = 1024
Hardware: AMD Instinct™ MI300X GPUs. Software: AITER v0.1.4, ROCm v6.4.0, PyTorch v2.6.0. Input configuration: batch size = [1,64,128,256,512], context length = 1024
Hardware: AMD Instinct™ MI300X GPUs. Software: AITER v0.1.4, ROCm v6.4.0, PyTorch v2.6.0. Input configuration: batch size = 128, context length = [1024,2048, 4096, 6144,8192]
Hardware: AMD Instinct™ MI300X GPUs. Software: AITER v0.1.4, ROCm v6.4.0, PyTorch v2.6.0. Input configuration: batch size = 128, context length = [1024,2048, 4096, 6144,8192]
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.