Unleashing AMD Instinct™ MI300X GPUs for LLM Serving: Disaggregating Prefill & Decode with SGLang#

LLM inference pipelines are hitting a scalability wall as prefill and decode phases compete for the same compute, causing latency spikes and underutilized resources. DistServe tackles this by disaggregating prefill and decode computation across separate GPUs—eliminating interference, decoupling resource planning, and unlocking new levels of optimization for both time-to-first-token (TTFT) and time-per-output-token (TPOT).
In this blog, you will learn how to leverage the popular fast serving framework SGLang to disaggregate prefill and decode phases. Whether your goal is lower latency or higher throughput, this method can help you achieve your service level objectives (SLOs).
What is Prefill Decode Disaggregation?#
Modern LLM inference is typically divided into two distinct phases: the prefill phase and the decode phase. The prefill phase is compute-bound, involving heavy computation to process the entire input sequence and populate the key-value (KV) cache. In contrast, the decode phase is memory-bound, as it generates tokens sequentially by attending to the stored KV cache.
Traditionally, both phases are executed on the same set of resources, which leads to resource contention and performance interference. As model sizes scale dramatically—from 1 billion to 1 trillion parameters, this unified approach introduces higher latency and lower throughput.
The intuitive solution is to scale horizontally by adding more nodes to handle the increased memory and compute demands. However, this brings a new challenge: it becomes increasingly difficult to meet strict Service Level Objectives (SLOs) such as latency and reliability, especially under variable workloads.
What are SLOs and Goodput?#
Service Level Objectives (SLOs) are a key element of service level agreement (SLA) between a service provider and a customer which defines specific measurable characteristics of the SLA such as availability, throughput, frequency, response time, or quality. Goodput represents the number of completed requests per second that adheres to SLOs. Goodput is throughput achieved while maintaining target levels of TTFT and TPOT.
Goodput represents the number of completed requests per second, maintaining SLOs. It reflects the request throughput under measurable SLOs (TTFT or TPOT requirements), hence both cost and service quality.
Why Do We Need to Disaggregate the Prefill and the Decode Phases?#
Disaggregating the prefill and decode phases in large language model (LLM) inference provides several clear advantages:
1. Resource Utilization: Separating the two phases allows independent execution, preventing contention between the compute-heavy prefill phase and the memory-heavy decode phase. This improves overall system efficiency and predictability.
2. Cost Effectiveness: Each phase has different hardware requirements—prefill benefits from high-throughput compute instances (e.g., GPUs with large compute capability), while decode demands low-latency, memory-optimized instances. Disaggregation allows each phase to run on the most cost-effective and performance-appropriate hardware, optimizing infrastructure usage and cost.
3. Improve Goodput: With disaggregation, prefill and decode workloads can adopt different scaling and parallelism strategies. For example, prefill can use tensor or pipeline parallelism to accelerate batched processing, while decode can scale out across multiple lightweight instances for faster token generation. This separation is especially valuable for meeting stringent service-level objectives (SLOs) such as low latency and high throughput under dynamic workloads.
How Do We Disaggregate Them?#
SGLang takes many factors into account when designing its disaggregating functions.
Dynamic Connection: A pair of prefill and decode server connections is established for each request. This approach allows us to easily scale the prefill and decode server pools up or down as needed.
Non-blocking Transfer: Send and receive operations are non-blocking and run in a background thread. This ensures that the original scheduler event loop continues to operate uninterrupted while data transfer occurs in the background.
Heterogeneous Parallelism: The design supports varying tensor parallelism (TP) for key-value (KV) transfers, enabling specialized optimizations on both the prefill and decode sides.
RDMA-Based Transfer: We leverage queue pairs in RDMA to establish connections and utilize scatter-gather elements (SGE) in RDMA to transfer non-contiguous memory chunks efficiently. In the SGLang codebase, we can control the behavior of how SGLang disaggregates the prefill and decode through server arguments as shown in Table 1.
Variable |
Description |
Default |
|---|---|---|
–disaggregation-mode |
Only used for PD disaggregation. |
null |
–disaggregation-transfer-backend |
The backend for disaggregation transfer. Default is |
mooncake |
–disaggregation-ib-device |
The InfiniBand devices for disaggregation transfer, accepts single device (e.g., |
null |
–disaggregation-bootstrap-port |
Bootstrap server port on the prefill server. Default is |
8998 |
–disaggregation-decode-tp |
Decode |
null |
–disaggregation-decode-pp |
Decode |
null |
–disaggregation-prefill-pp |
Prefill |
1 |
Table 1. SGLang server typical arguments
When working with AMD Instinct™ MI300X GPU environments, mooncake is device-agnostic, making it the preferred KV cache transfer engine in this blog. A high-performance RDMA NIC is required for KV cache transfer. This can be set manually (using ibstat to list available NICs) or left to auto-detection.
Here are additional fine-grained environment arguments for end-users. In this blog, we keep them as default as shown in Table 2.
Variable |
Description |
Default |
|---|---|---|
SGLANG_DISAGGREGATION_THREAD_POOL_SIZE |
Controls the total number of worker threads for KVCache transfer operations per TP rank. |
A dynamic value calculated by |
SGLANG_DISAGGREGATION_QUEUE_SIZE |
Sets the number of parallel transfer queues. KVCache transfer requests from multiple decode instances will be sharded into these queues so that they can share the threads and the transfer bandwidth at the same time. If it is set to 1, then requests are transferred one by one according to FCFS strategy. |
4 |
SGLANG_DISAGGREGATION_BOOTSTRAP_TIMEOUT |
Timeout (seconds) for receiving destination KV indices during request initialization. |
300 |
SGLANG_DISAGGREGATION_HEARTBEAT_INTERVAL |
Interval (seconds) between health checks to prefill bootstrap servers. |
5.0 |
SGLANG_DISAGGREGATION_HEARTBEAT_MAX_FAILURE |
Consecutive heartbeat failures before marking prefill server offline. |
2 |
SGLANG_DISAGGREGATION_WAITING_TIMEOUT |
Timeout (seconds) for receiving KV Cache after request initialization. |
300 |
Table 2. Further fine-grained disaggregation control environment arguments
How to Benchmark Disaggregated Inference?#
Let’s dive into the benchmark part. We recommend users choose a pre-built Docker image.
docker pull lmsysorg/SGLang:v0.4.7.post1-rocm630
For the prefill node, use the following code snippet to launch prefill.
ssh -i /home/amd/.ssh/id_rsa {serverp_ip} \
docker run --rm -d --network {network_name} --ipc host --name {serverp_name} \
--privileged --cap-add=CAP_SYS_ADMIN --device=/dev/kfd --device=/dev/dri --device=/dev/mem \
--group-add render --cap-add=SYS_PTRACE --security-opt seccomp=unconfined \
-e HUGGINGFACE_HUB_CACHE=/models -e MODELSCOPE_CACHE=/models \
-v /home/amd/models:/models \
{image_name} \
python3 -m SGLang.launch_server \
--model {model_name} \
--trust-remote-code \
--stream-output \
--host {serverp_ip} \
--port {pport} \
--mem-fraction-static 0.9 \
--disable-radix-cache \
--tp-size {tp_size} \
--base-gpu-id 0 \
--quantization fp8 \
--disaggregation-mode prefill \
--disaggregation-ib-device rdma0,rdma1,rdma2,rdma3,rdma4,rdma5,rdma6,rdma7
For the decode node, use the following code snippet instead.
ssh -i /home/amd/.ssh/id_rsa {serverd1_ip} \
docker run --rm -d --network {network_name} --ipc host --name {serverd1_name} \
--privileged --cap-add=CAP_SYS_ADMIN --device=/dev/kfd --device=/dev/dri --device=/dev/mem \
--group-add render --cap-add=SYS_PTRACE --security-opt seccomp=unconfined \
-e HUGGINGFACE_HUB_CACHE=/models -e MODELSCOPE_CACHE=/models \
-v /home/amd/models:/models \
-v /home/amd/.inductor_cache/:/tmp/torchinductor_root/ \
{image_name} \
python3 -m SGLang.launch_server \
--model {model_name} \
--trust-remote-code \
--stream-output \
--host {serverd1_ip} \
--port {d1port} \
--mem-fraction-static 0.9 \
--disable-radix-cache \
--tp-size {tp_size} \
--base-gpu-id 0 \
--enable-torch-compile \
--quantization fp8 \
--disaggregation-mode decode \
--disaggregation-ib-device rdma0,rdma1,rdma2,rdma3,rdma4,rdma5,rdma6,rdma7
Next, we need a mini load balance web proxy to help route the user request to the correct prefill node. SGLang provides a typical mini load balance implementation.
ssh -i /home/amd/.ssh/id_rsa {serverlb_ip} \
docker run --rm -d --network {network_name} --ipc host --name {serverlb_name} \
--privileged --cap-add=CAP_SYS_ADMIN --device=/dev/kfd --device=/dev/dri --device=/dev/mem \
--group-add render --cap-add=SYS_PTRACE --security-opt seccomp=unconfined \
-e HUGGINGFACE_HUB_CACHE=/models -e MODELSCOPE_CACHE=/models \
-v /home/amd/models:/models \
{image_name} \
python -m SGLang.srt.disaggregation.mini_lb --prefill http://{serverp_ip}:{pport} --decode http://{serverd1_ip}:{d1port} --host {serverlb_ip} --port {lbport}
That’s it. We can now send requests through the serving script to measure the disaggregation performance of 1 prefill instance and 1 decode instance (AKA 1P1D).
Note that SGLang inherits the bench serving script from vLLM. However, the vLLM side has more functionality support. In this blog, we select the vLLM bench to serve as a benchmark.
Pull the vLLM-related image.
docker pull rocm/vllm-dev:nightly_main_20250706
Launch the benchmark client for serving.
ssh -i /home/amd/.ssh/id_rsa {serverlb_ip} \
docker run --rm -t --network {network_name} --name bmk-client \
--privileged --cap-add=CAP_SYS_ADMIN --device=/dev/kfd --device=/dev/dri --device=/dev/mem \
--group-add render --cap-add=SYS_PTRACE --security-opt seccomp=unconfined \
-e HUGGINGFACE_HUB_CACHE=/models -e MODELSCOPE_CACHE=/models \
-v /home/amd/models:/models --workdir /app/vllm-upstream/benchmarks \
{client_image_name} \
python benchmark_serving.py \
--backend SGLang \
--base-url "http://{serverlb_ip}:{lbport}" \
--model {model_name} \
--percentile-metrics "ttft,tpot,itl,e2el" \
--metric-percentiles {metric_percentiles} \
--request-rate {request_rate} \
--ignore-eos \
--max-concurrency {max_concurrency} \
--dataset-name random \
--random-input-len {input_len} \
--random-output-len {output_len} \
--random-range-ratio {range_ratio} \
--num-prompts $(( {max_concurrency} * 2 )) \
--goodput {goodput_metric} \
--save-result --result-dir "{resultpath}" --result-filename "{result_filename}.json"
For the benchmark metrics, we define two scenarios: one is for the chatbot with input_len=3200, output_len=800, and concurrency=128; and another for heavy decode with input_len=1024, output_len=2048, and concurrency=128. In the next section, we will show readers how to observe performance gain by leveraging disaggregation.
Benefits of Disaggregating on the AMD Instinct MI300X GPU#
Chatbot Benchmark#
For the chatbot scenario, Figure 1 below illustrates that 1P1D can serve under 7.1X tighter SLO for 95% of requests. Moreover Figure 2 illustrates that 1P1D can serve under 13.2X tighter SLO for 99% of requests under SLO constraints = 25ms.
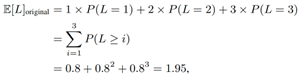
Figure 1. Llam3.3 70B ISL3200/OSL800/Con128 P95 ITL comparison between Colocate and Disaggregation (1P1D) on MI300X GPUs [1]#
Figure 2. Llam3.3 70B ISL3200/OSL800/Con128 P99 ITL comparison between Colocate and Disaggregation (1P1D) on MI300X GPUs [1]#
Heavy decode#
For the heavy decode scenario, Figure 3 illustrates that 1P1D can serve under 1.3X tighter SLO for 95% requests, Figure 4 illustrates that 1P1D can serve under 6.1X tighter SLO for 99% requests under SLO constraints = 25ms.
Figure 3. Llama 3.3 70B ISL1024/OSL2048/Con128 P95 ITL comparison between Colocate and Disaggregation (1P1D) on MI300X GPUs [1]#
Figure 4. Llama 3.3 70B ISL3200/OSL800/Con128 P99 ITL comparison between Colocate and Disaggregation (1P1D) on MI300X GPUs [1]#
Figure 5. Llama 3.3 70B ISL3200/OSL800/Con128 goodput comparison between Colocate and Disaggregation (1P1D) on MI300X GPUs [1]#
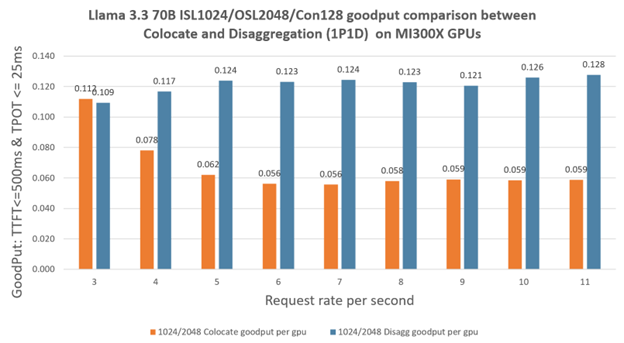
Figure 6. Llama 3.3 70B ISL1024/OSL2048/Con128 goodput comparison between Colocate and Disaggregation (1P1D) on MI300X GPUs [1]#
DistServe also introduces Goodput, the number of completed requests per second that adheres to SLOs (TTFT and TPOT requirements), and shows it is a much better metric, because it captures request throughput under SLO attainment – hence both cost and service quality. Here we define goodput to be those completed requests with TTFT <=1000ms or 500ms accordingly and TPOT <=25 ms. Then we use –goodput {goodput_metric} to collect the performance data. We normalized the goodput to be per GPU. As observed in Figure 5 and Figure 6, disaggregation brings huge benefits under the condition of the same number of requests. For a Chatbot 3200in/800out scenario, 1P1D can serve up to 6.9X more goodput requests, which fall within the SLO constraint of TTFT<=1000ms and TPOT<=25ms. For a heavy decode 1024in/2048out scenario, 1P1D can serve up to 2.23X more goodput requests, which fall within the SLO constraint of TTFT<=500ms and TPOT<=25ms.
Summary#
To recap, this blog walked you through the mechanics and advantages of prefill-decode disaggregation using SGLang, highlighting how it improves LLM serving efficiency on MI300X GPUs. Whether you’re optimizing cost or service quality, this approach helps you build more scalable, latency-aware LLM inference systems. Stay tuned as we explore advanced ROCm scheduling strategies and performance tuning techniques tailored for disaggregated inference on MI300X.
Additional Resources#
For more information and updates, check out:
Configuration Details#
[1] AMD Instinct™ MI300X GPU platform System Model: Supermicro AS-8125GS-TNMR2 CPU:2x AMD EPYC™ 9654 96-Core Processor NUMA:2 NUMA node per socket. NUMA auto-balancing disabled/ Memory: 2304 GiB (24 DIMMs x 96 GiB Micron Technology MTC40F204WS1RC48BB1 DDR5 4800 MT/s) Disk:16,092 GiB (4x SAMSUNG MZQL23T8HCLS-00A07 3576 GiB, 2x SAMSUNG MZ1L2960HCJR-00A07 894 GiB) GPU:8x AMD Instinct MI300X 192GB HBM3 750W Host OS: Ubuntu 22.04.4 System BIOS: 3.2 System Bios Vendor: American Megatrends International, LLC. Host GPU Driver: (amdgpu version): ROCm 6.3.1
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.