Unlock Peak Performance on AMD GPUs with Triton Kernel Optimizations#

Triton is a domain-specific programming language designed to simplify GPU programming for high-performance tasks, particularly in AI applications. It provides an open-source environment that enables users to write high-level Triton code with greater productivity compared to Nvidia CUDA or AMD HIP. The Triton compiler translates Triton code into optimized GPUs instructions, effectively compiling tensor operations into low-level GPU code. It achieves high efficiency through multiple optimizations passes and leverages the underlying architecture of the GPU. To optimize GPU performance, it is important to have a solid understanding of the Triton compiler and the role it plays in kernel performance. In this blog, we will deep dive into the AMD Triton compiler, introduce Triton kernel compilation, and provide insights on how to create an efficient Triton kernel code.
AMD Triton Compilation Flow#
Triton compiler includes 3 key modules, Frontend, Optimizer, and Backend machine code generation, as shown in Figure 1:
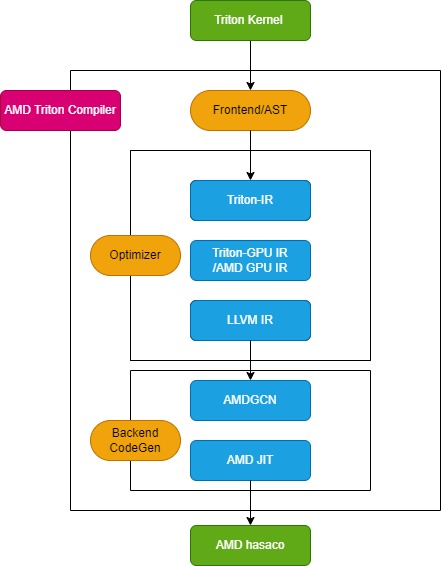
Figure 1. Triton Complier Block Diagram#
Frontend module walks the abstract syntax tree (AST) of python Triton kernel function, which includes the @triton.jit decorator to create the Triton Intermediate Representation (Triton-IR). The Optimizer module applies multiple optimizations and converts the Triton-IR into Triton-GPU IR (Triton-TTGIR) and then LLVM-IR. At this stage, optimization includes two core components: layout and passes, which are hardware dependent.
When generating Triton GPU IR, the hardware compute capability is included along with layout. Layout represents memory optimizations details on how the tensors are distributed to cores and warps for AMD GPUs on wavefronts. Currently, Triton supports multiple layouts like blocked (each warp owns a contiguous portion of the tensor), slice (restructures and distributes a tensor along a dimension), dot_op (optimized layout for block matrix product), shared (indicates GPU shared memory, amd_mfma (for AMD MFMA matrix core), amd_wmma (for AMD WMMA matrix core), and linear layout (to unify layouts within and across backends).
Various optimization passes are applied to the IRs. These optimizations include loop unrolling, memory access optimizations, constant folding, CSE, etc. to improve the performance of the generated codes. Optimization passes can be divided into 3 categories:
MLIR general optimization passes, like CSE, DCE, Inlining, etc.
GPU specific optimization passes, like Pipeline, Prefetch, Matmul accelerate, Coalesce, etc.
Vender specific GPU optimization passes, for example Nvidia provides TMA, Async Dot, etc. AMD provides OptimizeLDSUsage, BlockPingpong, etc.
The final stages of the Triton compilation process lower LLVM-IR to a device specific binary, which is done by backend machine code generation modules. Triton leverages LLVM to perform further optimizations and facilitate the generation of machine code. On AMD platforms, the AMD LLVM compiler module first translates the LLVM-IR to AMDGCN assembly codes then AMDGCN codes compile into a hsaco binary, which uses AMD JIT compiler.
AMD Triton Compilation Flow Example#
Let’s walk the triton compilation flow implementation on AMD GPUs using an example of Vector Add
Frontend module of AMD Triton Compiler
In the frontend module codes of Triton compiler, the Trition Kernel function converts into Triton-IR. In this example, Triton kernel function is add_kernel, which is marked by @triton.jit decorator. JIT decorator function first checks the TRITON_INTERPRET environment variable , if True, InterpretedFunction will be invoked, which is used to run Triton kernel in Interpreter mode; otherwise, it will run into JITFunction, where we will compile and run Triton kernel on real device.
The kernel compilation entry point is Triton compile function, which is invoked with the target device and compilation options information. It will create the kernel cache manager, launch the compilation pipeline, and populate the kernel meta data. It also loads the backend specific dialects, e.g. TritonAMDGPUDialect on the AMD platform, and backend specific LLVM modules to handle LLVM-IR compilation. When all are ready, it will invoke ast_to_ttir function to generate Triton-IR file of this kernel.
Optimizer module of AMD Triton Compiler
i. Triton-IR optimization
On AMD platforms, Triton-IR optimization passes are defined in make_ttir function.The optimization passes at this stage are hardware independent, like inline optimization, CSE(Common subexpression elimination), Canonicalization, DCE(Dead code elimination), LICM(Loop Invariant Code Motion), and Loop Unrolling.
ii. Triton-GPU IR optimization
On AMD platforms, Triton-IR optimization passes are defined in make_ttgir function , and are designed for GPU platform to boost its performance. Based on AMD GPU hardware features and kernel optimization experience, AMD also developed some AMD GPU specific optimization passes for this stage, which are listed in table 1, below.
TTGIR AMD Specific Optimization Pass |
Description |
|---|---|
AMD GPU accelerate Matmul |
Optimize the input/output layout of `dot` instruction to make them compatible AMD matrix cores |
AMD GPU Optimize Epilogue |
Store accumulators directly without going through SMEM in epilogue. |
AMD GPU Stream Pipeline |
Pipeline global loads through registers to shared memory while computing on previous tile |
AMD GPU insert instruction sched hints |
Insert instruction scheduling hints after the dot ops in the main loop |
AMD GPU Reorder Instructions |
This pass reorder instructions, so as to (1) decrease register pressure (e.g., by moving conversions from shared memory before their first use) and (2) promote LLVM instruction order more friendly to AMDGCN assembly generation. |
AMD GPU Block Ping pong |
This pass reorder instructions to interleave instructions from two warps on the same SIMD unit. We call this a ping-pong scheduling pattern, where two warps run concurrently in the synchronized fashion. |
AMD GPU Canonicalize Pointers |
Canonicalize pointers means to rewrite pointers passed to load/store operation as a `<basePtr, offset>` pair. |
AMD GPU Convert To Buffer Ops |
This pass converts memory and atomic operations (e.g., tt.load/tt.store/tt.atomic_rmw) to amdgpu buffer operations, if possible |
Table 1. AMD GPU-IR specific optimization
These optimization passes first convert Triton-IR to Triton-GPU IR. At this step, layout information is added into the IR. In this example, the tensors are represented as a #blocked layout.
If we try another Triton Matrix Multiplication example, the shared memory access is introduced by the above optimization passes to boost performance, which is a popular optimization solution for Matrix Multiplication, and amd_mfma layout is also used, which is designed for AMD MFMA accelerator.
iii. LLVM-IR optimization
On AMD platform, optimization passes are defined in make_llir function. This function includes two components: IR level optimization and AMD GPU LLVM compiler configuration. For IR-level optimization, AMD GPU specific optimization passes are included, like LDS/shared memory related optimization, and LLVM-IR level generic optimization, as shown in table 2.
LLVM-IR AMD Specific Optimization Pass |
Description |
|---|---|
Decompose Unsupported AMD Conversions |
Decompose conversions that are not supported by AMD GPU during the step of converting TritonGPU-IR to LLVM-IR. |
Optimize AMD lds/shared memory usage |
Minimize LDS usage: find operations with peak LDS consumption , and then try to transform candidate operations to fit them into LDS |
AMD GPU Lower Instruction Sched Hints |
Lower instruction scheduling hints to LLVM intrinsics |
AMD GPU Convert Builtin Func To LLVM |
Convert the Builtin Functions to LLVM |
Table 2. LLVM-IR AMD Specific Optimization Pass
For AMD GPU LLVM compiler configuration, the LLVM target library and context are initialized, sets various control constants on the LLVM module, sets calling convention for AMD GPU HIP kernels, configures some AMD GPU LLVM-IR attributes, like amdgpu-flat-work-group-size, amdgpu-waves-per-eu and denormal-fp-math-f32, and finally run LLVM optimization with level OPTIMIZE_O3
Machine Code Generation
This stage includes two steps: AMDGCN assembly generation and AMD hsaco ELF file generation. The first step is implemented in make_amdgcn function, which invoked LLVM translateLLVMIRToASM function with the input parameter “amdgcn-amd-amdhsa” to generate AMD assembly. The 2nd step is implemented in make_hsaco function, which use AMD backend assemble_amdgcn function and ROCm linker module to generate AMD hsaco ELF binary file, which can run on AMD GPUs.
Triton Optimization#
Based on the Triton compiler’s optimization passes, developers can improve kernel performance through several approaches:
Auto-tuning kernel configurations using the Triton autotune decorator, which explores different launch configurations to identify the most efficient one for a given workload.
Enhancing GPU resource utilization, such as applying the Split-K algorithm for GEMM operations to increase parallelism and balance compute load across the GPU.
Analyzing Triton-IRs and final ISA assembly to understand how the compiler transforms high-level code into optimized low-level instructions. Developers can trace and dump IRs at different stages (Triton-IR, TTGIR, LLVM-IR) to check whether key optimization passes have been applied as expected, especially AMD-specific ones.
When debugging the performance bottleneck, developers check whether the Triton optimization passes generated the expected IRs and ISA assembly by dumping and tracing the IRs, especially for these AMD specific optimization passes. For some cases, some modifications of kernel codes can help compiler passes work more efficiently and have better optimization results. In other cases, if developers would like to have better performance beyond the default compiler options/passes, developers may need to add more optimization passes for better performance. AMD welcomes contributions to the Triton ecosystem. For example, to address a Local Data Share (LDS) bandwidth limitation in a Mixture-of-Experts (MoE) kernel, a new compilation option - “bypass LDS” - was proposed as a model-specific optimization for AMD GPUs. Details on this can be found here.
Summary#
By dumping and comparing the IRs of Vector Add sample, we have walked through the entire Triton Kernel compilation process. AMD has developed a series of GPU specific optimization passes for OpenAI Triton infrastructure, significantly boosting Triton kernel performance on AMD GPUs. The details of Triton-IR lowering and corresponding optimization passes are fundamental and crucial for developers seeking to deeply understand the internals of the Triton compiler and to fine-tune kernel performance on AMD hardware. To take full advantage of Triton on AMD, explore the available optimization passes, experiment with your own kernel transformations, and contribute enhancements back to our open-source community. We hope that this blog will encourage you to tune, test, and contribute to Triton on AMD and help us shape the future of AI acceleration.
Additional Resources#
Developing Triton Kernels on AMD GPUs https://rocm.blogs.amd.com/artificial-intelligence/triton/README.html
Supercharging JAX with Triton Kernels on AMD GPUs https://rocm.blogs.amd.com/artificial-intelligence/jax-triton/README.html
AMD specific optimization passes and layouts: triton-lang/triton
Optimizing Triton kernal https://rocm.docs.amd.com/en/latest/how-to/rocm-for-ai/inference-optimization/optimizing-triton-kernel.html
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.