Fine-Tuning LLMs with GRPO on AMD MI300X: Scalable RLHF with Hugging Face TRL and ROCm#

In this blog, you will learn how to implement GRPO-based RLHF on AMD MI300X using ROCm and Hugging Face TRL—streamlining alignment training while enhancing model reasoning and inference performance. Reinforcement Learning from Human Feedback (RLHF) constitutes a critical phase in the fine-tuning of large language models (LLMs) and multimodal architectures. Over time, RLHF methodologies have advanced beyond traditional techniques, progressing from Proximal Policy Optimization (PPO) to Direct Preference Optimization (DPO), and more recently, to Group Relative Policy Optimization (GRPO). RLHF aims to make LLMs’ output better aligned with human preferences. Reinforcement Learning (RL) is an important step to enhance LLM’s reasoning capabilities and for better inference/test-time scaling law. Apart from LLM, there is also DPO application in text-to-image generation.
RL is not only essential for refining generation quality—it also plays a key role in enhancing LLMs’ reasoning capabilities and optimizing performance at inference time. While traditional RLHF relies heavily on supervised fine-tuning (SFT) of reward models and actor-critic algorithms like PPO, newer methods like DPO bypass explicit reward modeling using pairwise preference data. GRPO further reduces the dependency on human-labeled datasets by eliminating the need for a value model or SFT data, instead using group-based computations to estimate advantages.
As illustrated in Figure 1, PPO training requires multiple components: a reward model, a reference model, and separate policy and value models. In contrast, GRPO streamlines this process by training only the policy model, while relying on relative scoring across multiple outputs. Though this approach demands additional generation and sampling during training, it significantly reduces the need for expensive human feedback data, making it a compelling alternative for scalable RLHF.
With the emergence of models like GPT-o1, DeepSeek-R1, and growing interest in improving inference-time reasoning through scaling, there is a renewed focus on enhancing LLM performance beyond pretraining. In this blog post, we explore GRPO fine-tuning using the AMD ROCm™ software stack with the Hugging Face trl library. You’ll learn how effective RLHF post-training can boost a model’s reasoning ability, and how to harness the power of AMD Instinct™ GPUs to achieve efficient, high-performance training and inference for your LLM workloads.
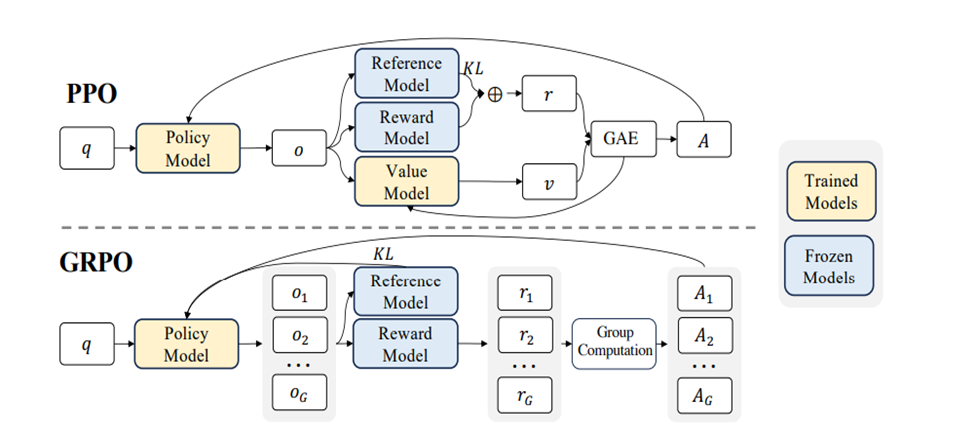
Figure1. PPO VS GPRO, the difference and common parts#
Running GRPO Fine-Tuning on AMD MI300X with ROCm + vLLM + Accelerate#
To fine-tune a large language model using Group Relative Policy Optimization (GRPO), we’ll walk through a setup that leverages AMD MI300X GPUs, ROCm, vLLM for efficient generation, and DeepSpeed with Hugging Face’s accelerate for distributed training. The target model in this example is Qwen2.5-1.5B-Instruct, and the dataset used is GSM8K (math word problems), all on a single-node, 8-GPU machine.
Prerequisite: Please have vLLM or PyTorch downloaded before these steps.
Step 1: Launch the Docker Environment#
Begin by pulling and running a ROCm-compatible Docker container. If your goal is to accelerate the generation process (which GRPO depends heavily on), it’s recommended to use the vLLM-optimized Docker image:
docker run --gpus all -it rocm/vllm:rocm6.3.1_vllm_0.8.5_20250513
vLLM version: 0.8.6.dev3+gd60b5a337.rocm631
PyTorch version: 2.7.0+gitf717b2a
Docker Command for Launching ROCm vLLM Container
```bash
NAME=my_container
DOCKER=rocm/vllm:rocm6.3.1_vllm_0.8.5_20250513
docker run -it --name $NAME \
--device /dev/kfd \
--device /dev/dri \
--privileged \
--network=host \
--group-add video \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
--shm-size=64g \
--ulimit memlock=-1 \
--ulimit stack=67108864 \
-v /home:/home \
-w /workspace \
$DOCKER \
/bin/bash
trl==0.16.1
deepspeed==0.16.4
accelerate
liger-kernel
peft
wandb
Step 2: Prepare the Training Scripts#
Set up your training script using references from:
These will guide your implementation of reward functions and training logic in a script like train_grpo.py.
Step 3: Launch vLLM for Prompt Generation#
In one terminal, start the vLLM inference server on GPU 0, which will be responsible for generating candidate responses needed for GRPO scoring:
HIP_VISIBLE_DEVICES=0 trl vllm-serve --model Qwen/Qwen2.5-1.5B-Instruct
Step 4: Start GRPO Training with Accelerate#
In a second terminal, start the actual GRPO fine-tuning process using accelerate and/or DeepSpeed (adding zero2 and zero3 DeepSpeed config_file). This will run on GPUs 1 to 7, leaving GPU 0 free for generation.
export HIP_VISIBLE_DEVICES=1,2,3,4,5,6,7
accelerate launch --multi_gpu --num-processes=7 train_grpo.py \
--model_name_or_path="Qwen/Qwen2.5-1.5B-Instruct" \
--max_steps=200 \
--train_epoch=1 \
--report_to="wandb"
Trained Model Parameters#
During training, we used Weights & Biases (wandb) to monitor key Output metrics in real-time, which enabled us to tune critical hyperparameters for the reasoning model. These adjustments help strike a better balance between bias and variance during reinforcement learning fine-tuning.
Hyperparameters for Tuning
Learning rate: The step size used by the AdamW optimizer to update the model’s parameters during training. during training optimization process to adjust model’s parameters
KL penalty coefficient: KL penalty coefficient is important to keep the output distribution of current active training LLM policy model having a similar output distribution with the reference(base) model. KL penalty coefficient helps maintain a balance between exploration (explore more new actions) and exploitation (take known actions with high rewards.).
Gradient norm clipping: Gradient norm clipping limits the L2 norm of gradients of model’s parameters during training backpropagation by setting a threshold to stabilize the training process.
During training we monitor the performance metrics outlined below to determine the performance of the model.
Performance Parameters
Soft format reward: this reward is to encourage the reasoning responses/completions of current LLM policy model with every prompt input having a specific format like “<reasoning>.*?</reasoning>\s*<answer>.*?</answer>”.
Correctness reward: This reward is to maximize the correctness responses/completions of active LLM policy model to corresponding questions.
Total reward: we include the two critical rewards mentioned above as well as other rewards like strict response format, XLM response format and completions with digital answers. All rewards have equal weights.
Result Interpretation#
Performance Parameters The subfigures on the first row of Figure 2 illustrate the progression of key reward signals during training. The train/rewards/correctness_reward_func, which represents the correctness reward, stabilizes around 0.8 to 1.0 after approximately 150 steps. The model adapts to the soft format reward more quickly, as shown by train/rewards/soft_format_reward_func, which converges by around step 50. Overall, the total reward (train/reward) steadily increases and stabilizes above 1.5
Hyperparameters for Tuning The subfigures on the second row of Figure 2 illustrate the trends related to key hyperparameters for 200 training iterations. The first plot, train/learning_rate, shows the learning rate schedule, which follows a cosine decay with a 10% warmup phase. The second plot, train/kl, monitors the KL divergence between the active policy LLM and the reference base model. This divergence increases during training and stabilizes around step 150. The third plot, train/grad_norm, represents the total gradient norm of the active policy LLM before gradient clipping is applied.
We observed an improvement of approximately 3 percentage points in exact match accuracy after applying GRPO fine-tuning evaluated with adapted reasoning prompt template. While results may vary slightly across runs or environments, the gain consistently demonstrates the effectiveness of GRPO on this reasoning-intensive task.
Model |
Flexible-extract, exact_match(zero-shot) |
|---|---|
Qwen2.5-1.5B-instruct |
38. 665 ±1.34 |
Qwen2.5-1.5B-instruct-GRPO,150-step |
42.760 ±1.363 |
Qwen2.5-1.5B-instruct-GRPO,200-step |
42.230 ±1.37 |
———————————— |
—————————————- |
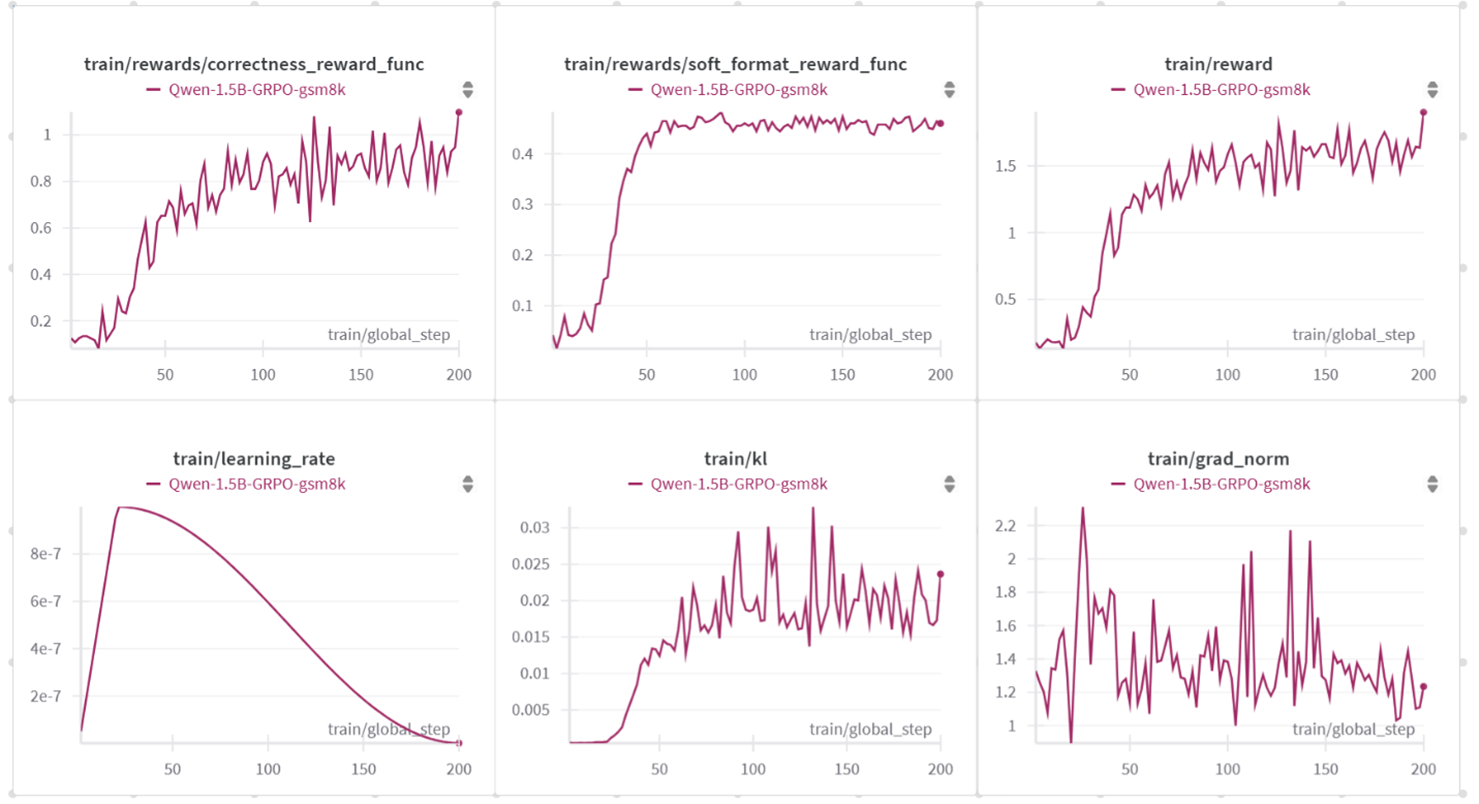
Figure 2. Wandb monitoring of training process on AMD MI300X, the first row is reward curves, second row include learning rate, KL, and gradient norm#
Summary#
In this post, we demonstrated how to perform GRPO-based fine-tuning on AMD Instinct™ MI300X GPUs using ROCm™, Hugging Face TRL, and vLLM. The walkthrough we provided covers infrastructure setup, training orchestration, and performance monitoring using a reasoning-intensive dataset (GSM8K) and a lightweight model (Qwen2.5-1.5B-Instruct). All related experiments with ROCm on MI300X were conducted using one GPU card dedicated to vLLM inference generation and the remaining seven cards for GRPO training and parameter updates. We encourage developers to further experiment with generation and fine-tuning configurations across different model sizes and tasks. To replicate the breakthrough results demonstrated in DeepSeek-R1, we also recommend exploring ROCm for large-scale model training and post-training alignment—particularly in multi-node environments with high model complexity, as detailed in the DeepSeek-R1 technical paper. In addition to the Hugging Face TRL library, the veRL Reinforcement Learning Engine with AMD-specific tutorials (AMD tutorials ) have also been recently released.
Resources#
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.