Efficient LLM Serving with MTP: DeepSeek V3 and SGLang on AMD Instinct GPUs#

Speculative decoding has become a key technique for accelerating large language model inference. Its effectiveness, however, relies heavily on creating the right balance between speed and accuracy in the draft model. Recent advances in Multi-Token Prediction (MTP) integrate seamlessly with speculative decoding, enabling the draft model to be more lightweight and consistent with the base model—ultimately making inference both faster and more effective.
This blog will show you how to leverage ROCm on AMD Instinct™ GPUs to fully exploit MTP and speculative decoding and accelerate LLM serving at scale. We will first delve into the module architecture and the core concepts behind MTP, followed by performance improvements achieved by enabling MTP in DeepSeek V3 during inference serving. We then dive into detailed step-by-step instructions for reproducing our benchmark results. In the final section, we provide a brief overview of the software and hardware stacks that underpin these results.
Key Highlights#
SGLang open-source serving and Multi Token Prediction (MTP) on AMD GPUs unlock faster and more efficient inference performance.
Enabling MTP in DeepSeek V3 inference serving achieves a 1.25–2.11x [1] speedup on the Random dataset and a 1.36–1.80x [2] speedup on the ShareGPT dataset using SGLang on AMD GPUs.
What is DeepSeek MTP?#
Multi-Token Prediction (MTP) was initially introduced in DeepSeek V3/R1 to enhance the training performance. It transforms the implicit causal chain between sequential tokens into an explicit form, improving the accuracy of the predicted tokens and enhancing the alignment of intermediate embeddings with the causal chain. Due to its design and module architecture, MTP can naturally be employed in the speculative decoding module during inference. Its strength in predicting future tokens, while maintaining close alignment with the base model’s predictive distribution, makes it a natural choice as the draft model in speculative decoding. We employ a single MTP module, referred to as NextN, as the draft model for speculative decoding. For speculative decoding, we adopt a commonly used approach, EAGLE.
Architecture of the MTP (NextN) Module#
During the training of DeepSeek V3/R1, MTP consists of multiple sequential modules. However, in inference, we employ only a single MTP module, referred to as NextN. The architecture of NextN is illustrated in Figure 1. It comprises four main components: an embedding layer, a linear projection matrix, a Transformer block, and an output head as shown in Figure 1.
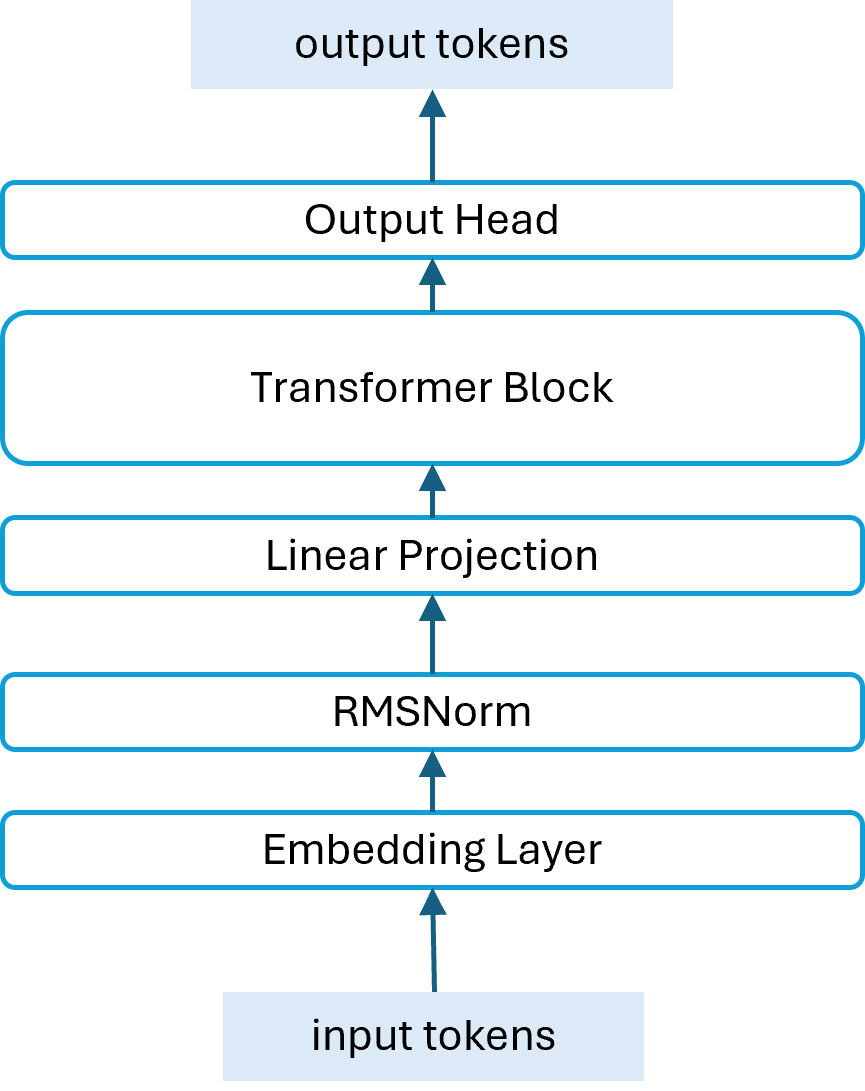
Figure 1. Architecture of NextN.#
Workflow#
When enabling MTP for DeepSeek V3 inference with SGLang, we specify the speculative decoding algorithm as EAGLE by including the option –speculative-algo=NEXTN or EAGLE in the serving launch command. EAGLE, introduced in early 2024, is an advanced variant of speculative decoding. As previously discussed, MTP can function as a speculative decoding draft model to accelerate DeepSeek V3 inference. However, it must operate within a speculative decoding algorithm. In our setup, EAGLE serves as the foundational workflow for this integration.
In speculative decoding, EAGLE consists of two phases: drafting and verification. In the drafting phase, EAGLE constructs a tree in which each node represents a draft token. The NextN module is leveraged to predict multiple draft tokens at each forward pass. Once the draft tree is built, candidate future tokens are extracted sequentially by traversing the tree.
In the verification phase, the base model computes the prediction probabilities of all draft tokens in a single forward pass. Draft tokens are retained if their predictions align with the base model; otherwise, they are discarded.
Analysis#
Due to its ability to predict future tokens, MTP can be naturally applied to speculative decoding in DeepSeek V3/R1 inference. At the same time, since the MTP weights are trained jointly with the base model, they meet the requirement in speculative decoding that the predictive distributions of the base model and the draft model must be consistent, which also saves extra training resources.
NextN, consisting of a single MTP module, is significantly more lightweight compared to the base model, DeepSeek V3/R1. Using such a small model in speculative decoding significantly improves the inference efficiency. In the following section, we provide detailed instructions for reproducing the performance gains posted in this blog.
Performance Gain of DeepSeek V3#
We use DeepSeek V3 as the base model and its NextN module as the draft model for speculative decoding. Both model weights are downloaded from HuggingFace. We leverage SGLang as the LLM serving engine. In this section we provide you with more details on the steps required to reproduce the experimental results.
Random Dataset#
We first conducted the performance benchmark on a random dataset. As shown in Table 1, there is a 1.25-2.11x speedup when enabling MTP in DeepSeek V3 inference serving. In this experiment, the max concurrency levels were set to 1, 2, 4, 8, 16, 32 and 64. We observe that the speedup ratio decreases as the max concurrency increases.
Figure 2 illustrates the performance comparison between DeepSeek V3 with and without MTP enabled. The x-axis represents end-to-end latency, and the y-axis represents total throughput. The results show that enabling MTP effectively reduces end-to-end latency while improving overall throughput.
Table 1. End-to-end latency comparison serving DeepSeek V3 without and with MTP enabled on random dataset, running on 8 AMD MI300X accelerators, with different max concurrencies as 1, 2, 4, 8, 16, 32 and 64. There is a 2.11x speedup when max concurrency is set as 1.
Max Concurrency |
Without MTP |
With MTP |
Speedup Ratio |
|---|---|---|---|
1 |
17348.25 |
8229.37 |
2.11 |
2 |
17162.29 |
8408.02 |
2.04 |
4 |
17948.30 |
9736.64 |
1.84 |
8 |
19919.06 |
11742.82 |
1.70 |
16 |
23708.94 |
15483.11 |
1.53 |
32 |
30868.39 |
21399.39 |
1.44 |
64 |
43848.20 |
35074.26 |
1.25 |
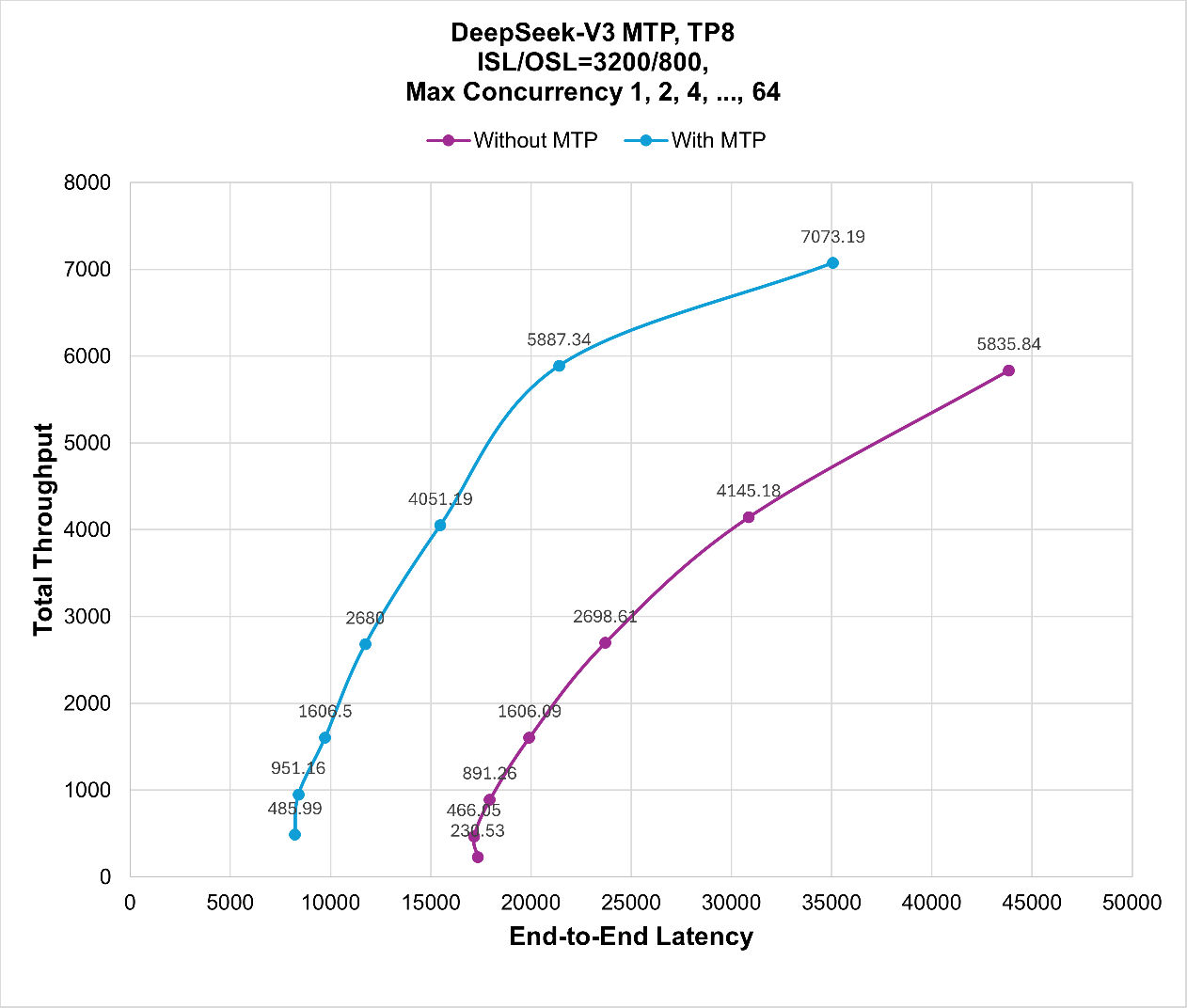
Figure 2. Performance comparison with MTP disabled and enabled in DeepSeek V3 serving with total throughput versus end-to-end latency on Random dataset. [1]#
ShareGPT#
We extended the performance benchmark to a real dataset, ShareGPT, which consists of real-world dialogues. As shown in Table 2, enabling MTP in DeepSeek V3 inference serving achieves a 1.36–1.80x speedup. Similar to the gains observed on the random dataset, the speedup ratio decreases as the maximum concurrency increases.
Figure 3 illustrates the performance of DeepSeek V3 inference serving in terms of total throughput and end-to-end latency. With MTP enabled, inference requires less time and achieves higher throughput compared to serving DeepSeek V3 without MTP.
Table 2. End-to-end latency comparison serving DeepSeek V3 without and with MTP enabled on ShareGPT dataset, running on 8 AMD MI300X accelerators, with different max concurrencies as 4, 8, 16, 32 and 64.
Max Concurrency |
Without MTP |
With MTP |
Speedup Ratio |
|---|---|---|---|
4 |
3981.91 |
2215.44 |
1.80 |
8 |
5007.75 |
2854.36 |
1.75 |
16 |
6255.86 |
3947.93 |
1.58 |
32 |
7571.25 |
5023.23 |
1.51 |
64 |
11900.36 |
8763.65 |
1.36 |
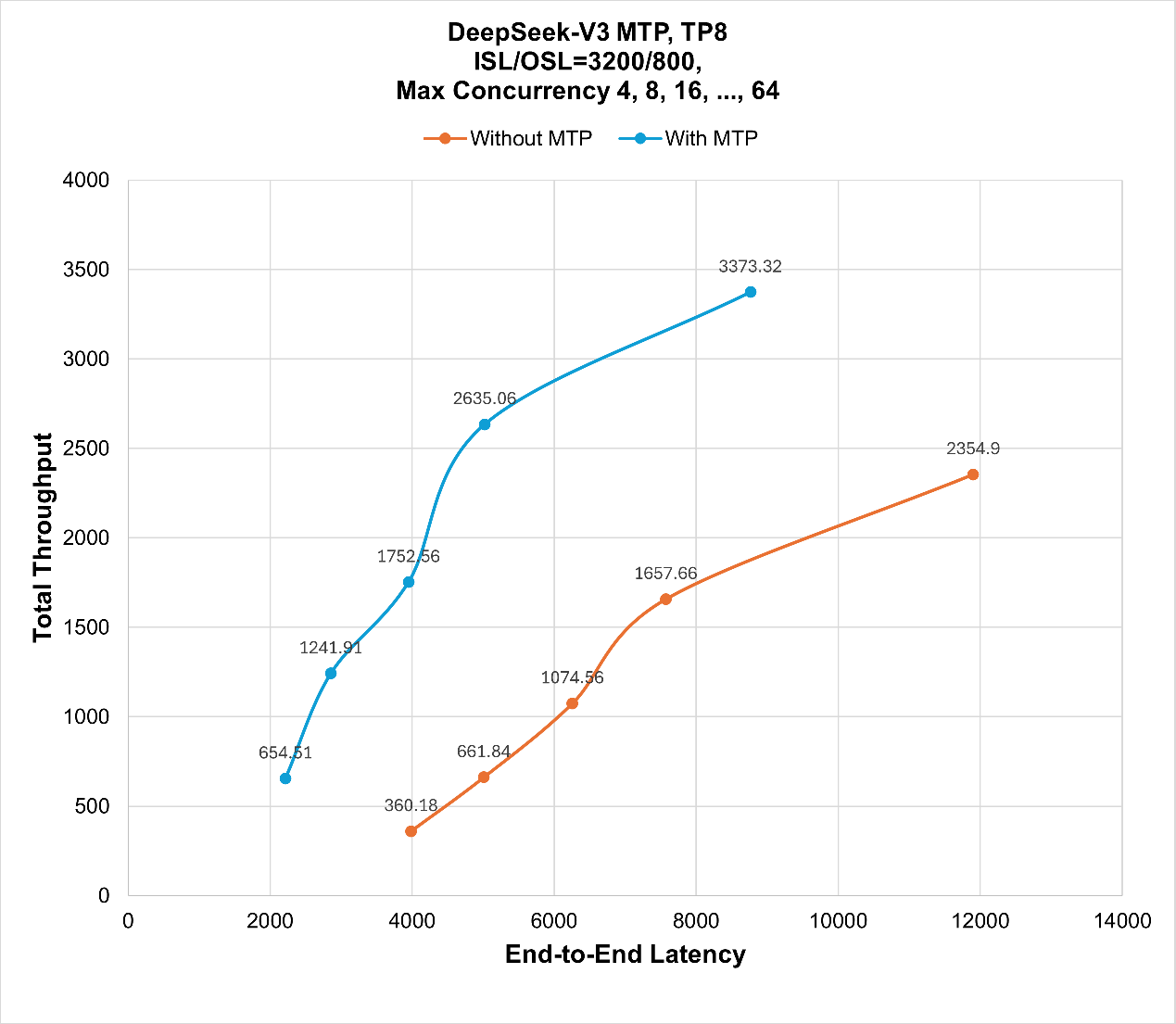
Figure 3. Performance comparison of disabling and enabling MTP for DeepSeek V3 serving with total throughput versus end-to-end latency on ShareGPT dataset. [2]#
How to Reproduce the Performance Benchmark#
With a few simple steps, you can run performance benchmarks on AMD Instinct GPUs using SGLang.
Launch the Docker Environment#
In this post, we leverage the official SGLang docker image: lmsysorg/sglang:v0.5.0rc0-rocm630-mi30x. Launch a docker container using the command as below, mounting your local working directory using ‘-v’.
docker run -d -it --ipc=host --network=host --privileged \
--cap-add=CAP_SYS_ADMIN --device=/dev/kfd --device=/dev/dri --device=/dev/mem \
--group-add render --cap-add=SYS_PTRACE --security-opt seccomp=unconfined \
--shm-size=192g \
--name sglang_mtp \
-v /home/models/:/models -v /home/:/work \
lmsysorg/sglang:v0.5.0rc0-rocm630-mi30x
Download the Model Weights#
Please navigate to the directory where you can save the downloaded model weights. In our case, it’s the directory “/models“. Use the commands below:
# Download DeepSeek R1 weight
huggingface-cli download --resume-download \
--local-dir-use-symlinks False \
deepseek-ai/DeepSeek-R1 \
--local-dir DeepSeek-R1
# Download NextN (MTP) weight
huggingface-cli download --resume-download \
--local-dir-use-symlinks False \
lmsys/DeepSeek-R1-NextN \
--local-dir DeepSeek-R1-NextN
Launch the Server#
In this post, we adopt DeepSeek-V3 and its MTP module, DeepSeek-V3-NextN as the base model and the draft model in the speculative decoding settings.
# Enable MTP
python3 -m sglang.launch_server \
--model-path /models/DeepSeek-V3/ \
--attention-backend aiter \
--port 8000 \
--host 0.0.0.0 \
--trust-remote-code \
--tp-size 8 \
--enable-metrics \
--mem-fraction-static 0.85 \
--chunked-prefill-size 131072 \
--speculative-algorithm NEXTN \
--speculative-draft-model-path /models/DeepSeek-V3-NextN/ \
--speculative-num-steps 2 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 3 \
--speculative-accept-threshold-single=0.001
# Baseline
python3 -m sglang.launch_server \
--model-path /models/DeepSeek-V3/ \
--attention-backend aiter \
--port 8000 \
--host 0.0.0.0 \
--trust-remote-code \
--tp-size 8 \
--enable-metrics \
--mem-fraction-static 0.85 \
--chunked-prefill-size 131072
Below is a summary of the parameters used in the command and their respective functions:
–speculative-draft-model-path: Path to the draft model’s weights. This can be a local directory or a Hugging Face repository ID.
–speculative-num-steps: Specifies the number of decoding steps to sample from the draft model during speculative decoding.
–speculative-eagle-topk: Defines the number of top tokens sampled from the draft model at each step in the Eagle algorithm.
–speculative-num-draft-tokens: Sets the number of tokens to be sampled from the draft model in speculative decoding.
–speculative-algorithm: Specifies the speculative decoding algorithm to use. Options include {EAGLE, EAGLE3, NEXTN}.
–speculative-accept-threshold-single: Sets the confidence threshold for accepting each draft token during speculative decoding.
–mem-fraction-static: Defines the fraction of total memory allocated for static use (such as model weights and the KV cache pool). Reduce this value if out-of-memory errors occur.
Set the Client#
# client command for MTP enabled benchmark
python3 -m sglang.bench_serving --backend sglang \
--dataset-name random --num-prompt 300 \
--request-rate 1 \
--random-input 3200 --random-output 800 \
--sglang_mtp_3200_800
# client command for baseline benchmark
python3 -m sglang.bench_serving --backend sglang \
--dataset-name random --num-prompt 300 \
--request-rate 1 \
--random-input 3200 --random-output 800 \
--sglang_base_3200_800
Summary#
In this blog, we explored how Multi-Token Prediction (MTP) enhances speculative decoding to accelerate large language model inference. By leveraging open-source SGLang serving on AMD Instinct GPUs, we enabled MTP within DeepSeek V3, achieving significant speedups in real-world benchmarks. Follow our step-by-step guide, run the benchmarks yourself, and see how MTP accelerates inference in your own workloads. Together, these results highlight how the AMD hardware–software ecosystem and DeepSeek’s MTP architecture work hand in hand to deliver faster, more efficient LLM inference at scale.
We plan to extend our exploration to evaluate whether DeepSeek V3 with MTP can achieve further acceleration. For example, in the verification phase of speculative decoding, different strategies can be applied to improve the acceptance rate of draft tokens, such as token-by-token verification. We may also adopt different sampling strategies, including speculative sampling and typical sampling, to further boost the inference efficiency. In addition, tuning MTP-related hyperparameters could enhance its overall effectiveness in driving efficiency gains.
Endnotes#
[1] Configuration Details
End-to-end latency indicates the total time taken for a user sending a request and getting a response back, and we use milliseconds per request as its unit. All the experiments were conducted on 8 AMD MI300X GPUs, with ROCm 6.3.1 and SGLang v0.5.0rc0 installed in the system environment.
[2] Configuration Details
Data measured on 18/08/2025. End-to-end latency indicates the total time taken from when a user sends a request to when they receive a response. We use milliseconds per request as its unit. All the experiments were conducted on 8 AMD MI300X GPUs, with ROCm 6.3.1 and SGLang v0.5.0rc0 installed in the system environment.
System Configuration
AMD MI300X GPUs System Model: Supermicro AS-8125GS-TNMR2 CPU: 2x AMD EPYC 9654 96-Core Processor NUMA: 2 NUMA node per socket. NUMA auto-balancing disabled Memory: 3072 GiB (32 DIMMs x 96 GiB Micron Technology DDR5 4800 MT/s) Disk: 70TiB GPU: 8x AMD MI300X 192GB Host OS: Ubuntu 22.04.4 System BIOS: 3.2 System Bios Vendor: American Megatrends International, LLC. Host GPU Driver: ROCm 6.3.1
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.