vLLM V1 Meets AMD Instinct GPUs: A New Era for LLM Inference Performance#

vLLM has been a successful LLM inference and serving engine that excels at providing innovative features to users and developers. Earlier this year, the vLLM community introduced a major upgrade of its core engine and architecture to vLLM V1 (V1), which enhances the flexibility and scalability of the engine while retaining its core features. For simplicity, we’ll refer to vLLM V0 as “v0” and vLLM V1 as “V1” throughout this post. To align with the vLLM community’s continuous innovation, the AMD ROCm™ software team and open-source ROCm developers have enabled the fully optimized vLLM V1 engine on AMD GPUs.
In this blog, we explore key improvements introduced in vLLM V1 for AMD GPUs, as well as the main benefits users can expect from migrating to this new version.
Overview of Architectural Improvements in vLLM V1#
The new V1 engine has multiple improvements that include:
Optimized execution loop and API server
a. The asynchronous process of the V1’s scheduler effectively separates CPU-intensive operations, such as token/de-tokenization and image preprocessing, from the GPU-intensive model inference process in a non-blocking manner as shown in Figure 1.
b. This feature enables higher compute utilization, especially for multimodal LLM performance, which heavily relies on the CPU for preprocessing.
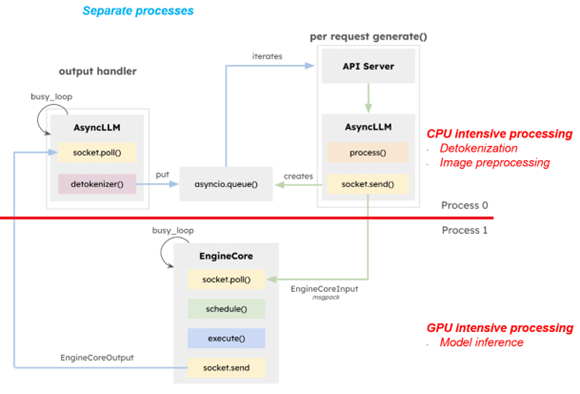
Figure 1. Separate CPU & GPU intensive workloads in different processes in vLLM V1[1]#
Simplified scheduler with chunked-prefill and prefix-caching enabled
a. By managing token allocations in a fixed budget without distinguishing prefill-only and decode-only phases, the simpler V1 scheduler easily incorporates advanced scheduling features.
b. Advanced features, such as chunked-prefill and prefix-caching, are enabled by default, and users benefit from shorter prompt token response latency. Figure 2 below illustrates the implementation of chunked-prefill with a fixed 10 token budget, where the scheduler allocates tokens at runtime.
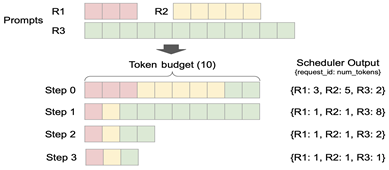
Figure 2. Chunked-prefill & decoding token processing in a fixed token budget in vLLM V1[1]#
ROCm Software Support for vLLM V1#
The official ROCm vLLM Docker images now enable V1 as the default configuration. However, users can choose to run in V0 by overriding the environment variable VLLM_USE_V1=0 before launching a vLLM serving engine.
Below are key features of V1 that ROCm software supports. In V1, many high-performance features are enabled by default, eliminating the need for manual configuration by users.
FEATURE |
STATUS |
ADDITIONAL SETTING |
|---|---|---|
V1 |
Optimized |
- Default on |
Prefix-caching |
Optimized |
- Default on |
Chunked-prefill |
Optimized |
- Default on |
FP8 KV cache |
Optimized |
- Default off |
Table 1. Key vLLM V1 features and ROCm support status
Multimodal and Online Serving Enhancements in vLLM v1#
1. Multimedia Performance Improvements#
Multimodal language models, such as Qwen2-VL-7B-Instruct, enable powerful new AI applications across visual question answering and multi-turn image-text dialogue.
With the introduction of a new scheduler in V1, users can expect improved latency for multimodal LLMs across a wide range of QPS (Queries Per Second).
In V0, requests were assumed to be fully prefilled, and multimodal embeddings (which are continuous features) could not be easily broken down due to the full-attention mechanisms of encoders. To address this limitation, V1 introduced an encoder cache and an encoder-aware scheduler. Multimodal embeddings are now generated by the encoder and stored directly in this GPU-based cache, which reduces CPU overhead.
These architectural changes lead to performance benefits in V1. In online serving scenarios, V1 demonstrates lower end-to-end latency across different request rates compared to V0, as shown in Figure 3, below. These results demonstrate that V1 efficiently handles continuous multimodal embeddings and complex input preprocessing.
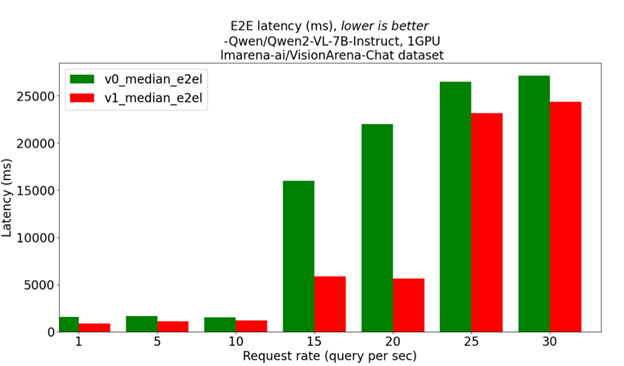
Figure 3 vLLM V1 and V0 latency on multimodal LLM under different request rates[2]#
2. Online serving TTFT improvements#
In the legacy vLLM V0 engine without chunked-prefill, users have consistently observed high time to first token (TTFT) values in online serving mode as shown in Figure 4. This is because decoding starts only after prefill tokens are processed due to an inflexible scheduling dependency between input tokens (measured as input sequence length, ISL) and output tokens (measured as output sequence length, OSL) in V0.
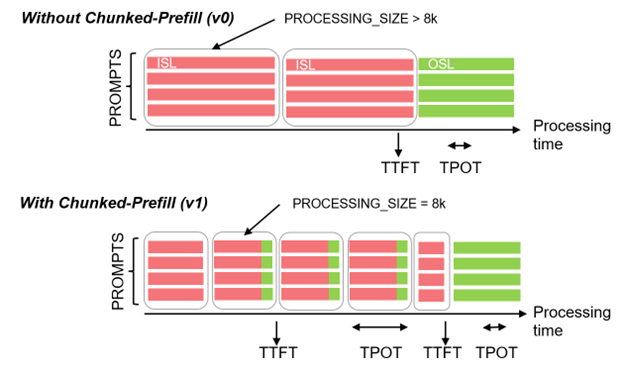
Figure 4 Chunked-prefill of the vLLM V1 and TTFT & TPOT distribution#
In contrast, in V1 with chunked-prefill, output tokens are processed in parallel with input tokens, so that in general users will receive much shorter first tokens than without chunked-prefill in V1. Note that users can also manually turn on chunked-prefill in the V0 engine but we recommend using V1 and its default settings because V1 also includes many advanced optimizations, such as torch.compile, on top of the chunked-prefill.
Each green dot represents the TTFT of an individual prompt, while the red line indicates the median TTFT across all prompts. With the legacy pre-fill in v0 as shown in Figure 5a, every request clusters tightly around ~0.33 s TTFT, whereas the chunked-prefill scheduler in v1 presented in Figure 5b drops the median to ~0.25s, but at the cost of a wider spread (occasional 0.30 s+ outliers) as chunk scheduling introduces more variability across prompts as shown in Figures 5a and 5b
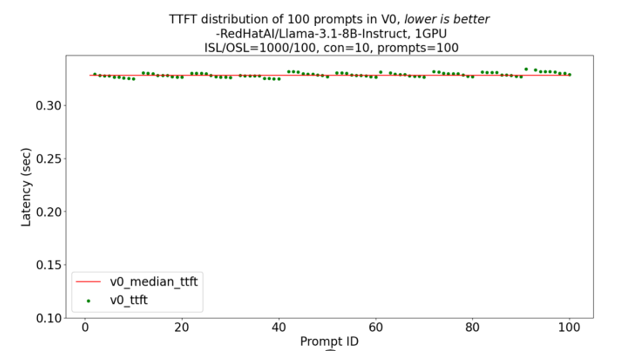
Figure 5a TTFT distribution of 100 prompts in V0[3]#
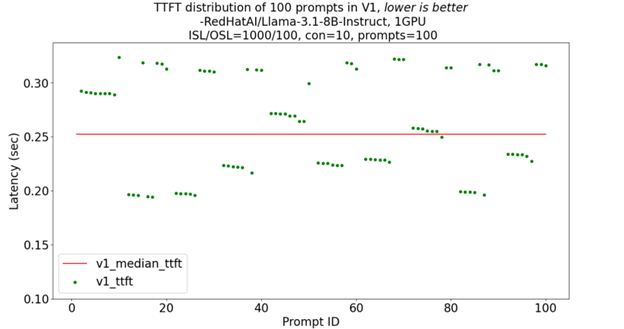
Figure 5b TTFT distribution of 100 prompts in V1[3]#
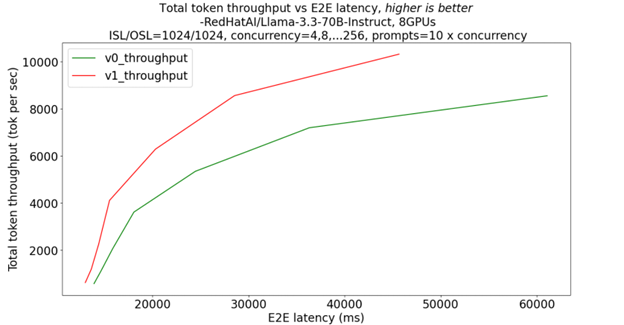
Figure 6a Total token throughput vs e2e latency in V0 and V1[4]#
Across all tested concurrency levels, the new scheduler in v1 (red) delivers roughly 25 to 35% more total-token throughput than v0 (green) for the same end-to-end latency. This is evidence that v1’s chunked-prefill and improved batching scale far more efficiently on the 70 B model across 8 GPUs as shown in Figure 6a.
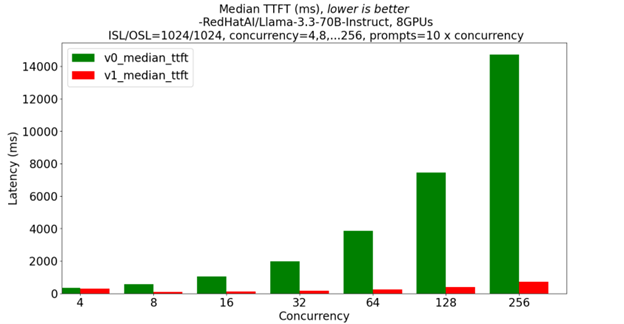
Figure 6b Median TTFT in V0 and V1[4]#
As concurrency scales from 4 to 256 in Figure 6b above , v0’s median TTFT ranges from a few hundred milliseconds to roughly 14 seconds, while v1 stays below ~400 ms. This highlights v1’s chunked-prefill scheduler, outperforming v0 by more than an order of magnitude.
3. Step-by-Step Guide: Benchmarking vLLM V1#
To reproduce the performance of V1, please use these commands. Thanks to the Red Hat AI team, we leveraged their clone models in the Hugging Face repository, allowing users to access models without requiring additional permission.
vLLM docker launch command: common for V0 and V1#
#In the host machine
docker run -it \
--device /dev/dri \
--device /dev/kfd \
--network host \
--ipc host \
--group-add video \
--security-opt seccomp=unconfined \
-v $(pwd):/workspace \
-w /workspace \
rocm/vllm-dev:nightly_0624_rc2_0624_rc2_20250620
vLLM V0 default server launch command#
# Inside the container: vLLM V0 running in background with “&”
VLLM_USE_V1=0 \
vllm serve RedHatAI/Llama-3.3-70B-Instruct \
-tp 8 \
--disable-log-requests \
--trust-remote-code &
vLLM V1 default server launch command#
# Inside the container: vLLM V1 running in background with “&”
VLLM_V1_USE_PREFILL_DECODE_ATTENTION=1 \
vllm serve RedHatAI/Llama-3.3-70B-Instruct \
-tp 8 \
--disable-log-requests \
--trust-remote-code \
--compilation-config '{"full_cuda_graph": true}' &
vLLM client benchmark command: common for V0 and V1#
# Inside the containers
isl=1024
osl=1024
MaxConcurrency="4 8 16 32 64 128 256"
for concurrency in $MaxConcurrency;
do
python3 /app/vllm/benchmarks/benchmark_serving.py \
--model RedHatAI/Llama-3.3-70B-Instruct \
--dataset-name random \
--random-input-len $isl \
--random-output-len $osl \
--num-prompts $((10 * $concurrency)) \
--max-concurrency $concurrency \
--ignore-eos \
--percentile-metrics ttft,tpot,e2el
done
Summary#
This blog demonstrated how to harness the architectural advancements of vLLM v1 using the Llama 3.3-70B model on AMD Instinct™ MI300X GPUs through the vLLM framework. In this blog we provided an in-depth look at how multimodal capabilities and online serving enhancements in vLLM v1 contribute to reduced end-to-end latency and deliver significant performance improvements. Looking forward, we are developing a high-performance attention kernel for chunked-prefill within ROCm AITER, featuring FP8 key-value cache support. If you’d like to stay updated or contribute, be sure to visit the ROCm AITER GitHub repository.
Endnotes#
[1] vLLMV1 Blog
[2] Based on testing by AMD on June 25, 2025, on the cloud instance from AMD Developer Cloud configured with an AMD Instinct MI300X GPU with a request rate from 1 to 30 to compare the processing latency of the Qwen2.5-VL-7B-Instruct model with lmarena-ai/Vision Arena-Chat dataset. Performance may vary based on configuration, usage, software version, and optimizations.
[3]. Based on testing by AMD on June 25, 2025, on the cloud instance from AMD Developer Cloud configured with an AMD Instinct MI300X GPU with a concurrency 10, 100 prompts, 1000 input sequence length, and 100 output sequence length to compare the TTFT (Time To First Token) distribution of each prompt of the Llama-3.1-8B-Instruct model with random dataset. Performance may vary based on configuration, usage, software version, and optimizations.
[4]. Based on testing by AMD on June 25, 2025, on the cloud instance from AMD Developer Cloud configured with 8 AMD Instinct MI300X GPUs with a concurrency from 4 to 256, the number of prompts from 40 to 2560, 1024 input sequence length, and 1024 output sequence length to compare the overall Throughput and TTFT (Time To First Token) the Llama-3.3-70B-Instruct model with random dataset. Performance may vary based on configuration, usage, software version, and optimizations.
[5] AMD Developer
Cloud
CONFIGURATION:
8x AMD Instinct MI300X 192GB HBM3 750W - 1.5 TB VRAM - 160 vCPU - 1920
GB RAM
Boot disk: 2 TB NVMe- Scratch disk: 40 TB NVMe, Instance OS: Ubuntu
24.04.2 LTS, Host GPU Driver: (amdgpu version): ROCm 6.4.0
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.