Supercharge DeepSeek-R1 Inference on AMD Instinct MI300X#

Our previous blog post on this topic discussed how DeepSeek-R1 achieves competitive performance on AMD Instinct™ MI300X GPUs. We also included performance comparisons against Nvidia H200 GPUs and a short demo application illustrating real-world usage. In this blog we will delve into how using the SGLang framework, critical kernel optimizations like AI Tensor Engine for ROCm™, and hyperparameter tuning helps to achieve performance boosts.
At a Glance#
By using the latest SGLang framework, compared to Nvidia H200,MI300X achieves - 2X–5X higher throughput at the same latency[1] - Up to 75% higher throughput and 60% lower latency for same concurrency [1].
AI Tensor Engine for ROCm software (AITER) kernels are optimized providing +2X GEMM [2], +3X MoE [3], +17x MLA decode[4], +14X MHA prefill[5]
SGLang serving hyperparameter tuning, thanks to the larger memory capacity of MI300X, boosted throughput at large concurrency
Key Takeaways from DeepSeek-R1 Serving Benchmark#
MI300X GPU demonstrates significantly better performance with SGLang across the board regarding total throughput vs. end-to-end latency with various optimization techniques. Figure 1 below shows that using SGLang framework and key optimization techniques, MI300X achieved up to 5X higher throughput at similar latencies vs NVIDIA H200.
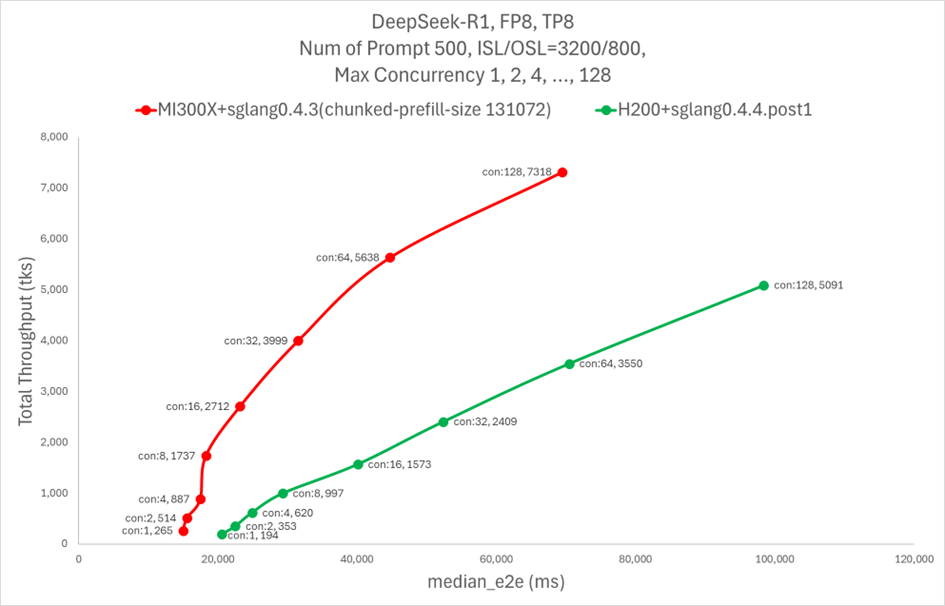
Figure 1. DeepSeek R1 Total Throughput (tks) vs. Latency (ms)[1]#
As shown in Figure 2, H200 GPUs can serve up to 16 concurrent requests with inter-token latency (ITL) below 50ms in a single node. We benchmarked the performance of SGLang on the Nvidia H200 GPUs, using SGLang 0.4.4.post1 and flashinfer MLA library. A single MI300X node, which consists of 8 GPUs, can serve up to 128 concurrent requests while maintaining inter-token latency (ITL) below 50ms, which shows MI300X has higher user capacity to complete response without violating user experience.
Note: Setting the chunked prefill size parameter to 131,072 enables single batching of input sequences, but this may lead to out-of-memory (OOM) errors for very large input sequences. Reducing the chunked prefill size allows for batched prefill cache computation, making better use of the model’s total context length budget. However, this comes at the cost of increased decode latency, as the input must be processed in smaller batches and retrieved during decoding. Readers are encouraged to optimize this parameter for their specific use-case.
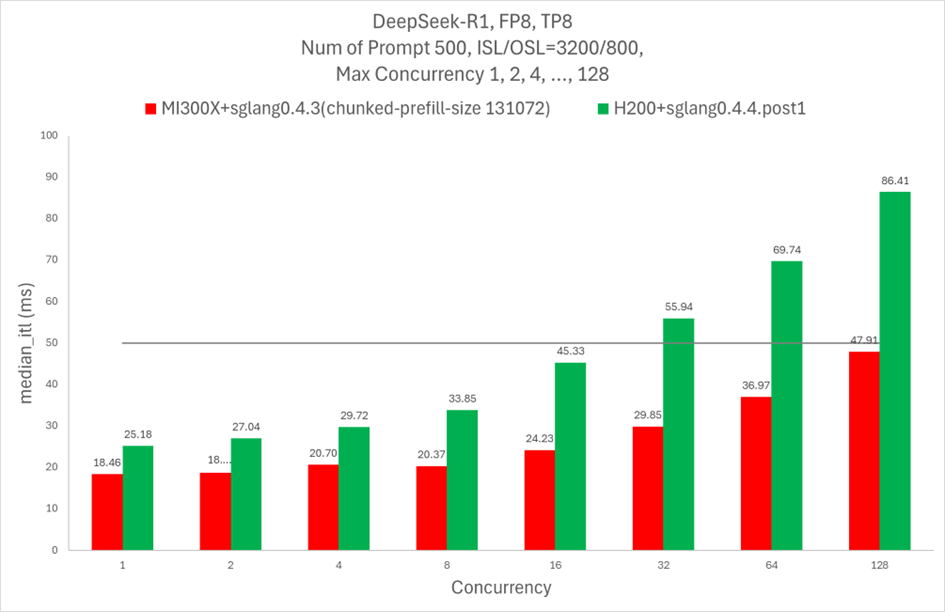
Figure 2. DeepSeek R1 Higher concurrency under 50 ms Inter Token Latency limit [1]#
Key Optimizations#
Optimization techniques enable developers to significantly improve the performance of applications running on GPUs, leveraging the full potential of parallel processing and removing memory bottlenecks. The AMD AI Tensor Engine for ROCm (AITER) is a centralized repository filled with high-performance AI operators designed to accelerate various AI workloads.
AI Tensor Engine for ROCm (AITER)
AITER is a brand-new high-performance open-source AI operator library. It provides Python and C++ APIs that can be easily integrated into SGlang, vLLM, and other custom frameworks. The following kernels for DeepSeek V3/R1 have been optimized in AITER to achieve significant uplift on the MI300X GPUs so that users can experienced significant performance boost using this library. - AITER block-scale GEMM (up to 2X boost) - AITER block-scale fused MoE (up to 3X boost) - AITER MLA for decode (up to 17X boost) - AITER MHA for prefill (up to 14X boost)
Hyperparameter Tuning
When running programs with a high number of threads (e.g., 128 or more), the system faces a bottleneck due to slow prefill throughput. We found that using a higher value of chunked_prefill_size can accelerate the prefill phase with the cost of more VRAM consumption as shown in Figure 3.
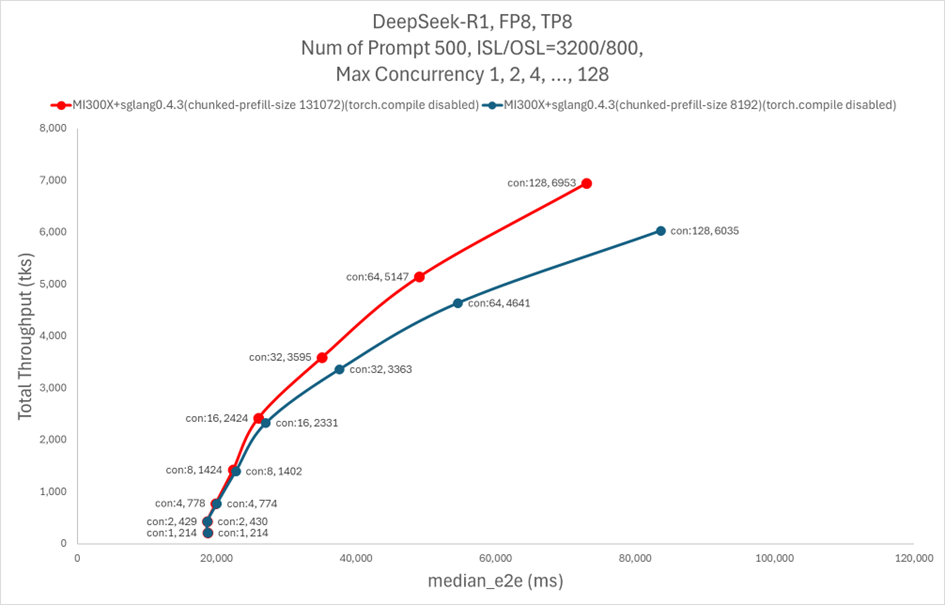
Figure 3. DeepSeek R1 Higher Total Throughput (tks) with Hyperparameter tuning on SGLang [1]#
How to Reproduce the Benchmark#
Now let’s reproduce the same performance boost on your system and apply the same techniques to your application for optimal performance on the MI300X GPUs.
The following instructions assume that the user already downloaded a model.
Note: The image provided for replicating the MI300X benchmark is a pre-upstream staging version. The optimizations and performance enhancements in this release are expected to be included in the upcoming lmsysorg upstream production release.
AMD Instinct MI300X GPU with SGLang#
Set relevant environment variables and launch the AMD SGLang container.
docker pull rocm/sgl-dev:upstream_20250312_v1
export MODEL_DIR=<DeepSeek-R1 saved_path>
docker run -it \
--ipc=host \
--network=host \
--privileged \
--shm-size 32G \
--cap-add=CAP_SYS_ADMIN \
--device=/dev/kfd \
--device=/dev/dri \
--group-add video \
--group-add render \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
--security-opt apparmor=unconfined \
-v $MODEL_DIR:/model \
rocm/sgl-dev:upstream_20250312_v1
Start the SGLang server.
python3 -m sglang.launch_server \
--model /model \
--tp 8 \
--trust-remote-code \
--chunked-prefill-size 131072 \
--enable-torch-compile \
--torch-compile-max-bs 256 &
Run the SGLang benchmark serving script for the user defined concurrency values and desired parameters.
# Run after “The server is fired up and ready to roll!”
concurrency_values=(128 64 32 16 8 4 2 1)
for concurrency in "${concurrency_values[@]}"; do
python3 -m sglang.bench_serving \
--dataset-name random \
--random-range-ratio 1 \
--num-prompt 500 \
--random-input 3200 \
--random-output 800 \
--max-concurrency "${concurrency}"
done
Note: Using the torch compile flags will result in longer server launch time
NVIDIA H200 GPU with SGLang#
Set relevant environment variables and launch the NVIDIA SGLang container.
docker pull lmsysorg/sglang:v0.4.4.post1-cu125
export MODEL_DIR=<DeepSeek-R1 saved_path>
docker run -it \
--ipc=host \
--network=host \
--privileged \
--shm-size 32G \
--gpus all \
-v $MODEL_DIR:/model \
lmsysorg/sglang:v0.4.4.post1-cu125
Start the SGLang server.
export SGL_ENABLE_JIT_DEEPGEMM=1
python3 -m sglang.launch_server \
--model /model \
--trust-remote-code \
--tp 8 \
--mem-fraction-static 0.9 \
--enable-torch-compile \
--torch-compile-max-bs 256 \
--chunked-prefill-size 131072 \
--enable-flashinfer-mla &
Run the SGLang benchmark serving script for the user defined concurrency values and desired parameters.
# Run after “The server is fired up and ready to roll!”
concurrency_values=(128 64 32 16 8 4 2 1)
for concurrency in "${concurrency_values[@]}"; do
python3 -m sglang.bench_serving \
--dataset-name random \
--random-range-ratio 1 \
--num-prompt 500 \
--random-input 3200 \
--random-output 800 \
--max-concurrency "${concurrency}"
done
Summary#
This blog showed you how to achieves breakthrough inference performance using DeepSeek-R1 on AMD Instinct™ MI300X GPUs by leveraging the SGLang framework, AMD’s AI Tensor Engine for ROCm (AITER), and targeted hyperparameter tuning. We demonstrated how MI300X outperforms Nvidia’s H200 with up to 5× higher throughput and significantly lower latency, especially under high concurrency workloads. We showed how core kernel optimizations—including GEMM, MoE, MLA decode, and MHA prefill—delivered major performance boosts, while tuning parameters like chunked_prefill_size enhanced throughput scaling. We also provided step-by-step benchmarking instructions to help you replicate our findings, showcasing MI300X’s strength for serving large-scale machine learning models efficiently
More optimizations are coming soon in future AMD ROCm software releases. We expect further performance boost, including but not limited to:
Expert Parallelism (EP)
Prefill and decode disaggregation
Speculative decoding
Try Today#
Download the prebuilt SGLang docker container from Docker hub and follow the instructions here to get started on the MI300X GPUs: sgl-project/SGLang.
Additional Resources#
SGLang Docker files for production deployment: Dockerfile
GitHub For AITER: ROCm/aiter.
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.