Unlock DeepSeek-R1 Inference Performance on AMD Instinct™ MI300X GPU#

In this blog, we explore how DeepSeek-R1 achieves competitive performance on AMD Instinct™ MI300X GPUs, along with performance comparisons to H200 and a short demo application showcasing real-world usage. By leveraging MI300X, users can deploy DeepSeek-R1 and V3 models on a single node with impressive efficiency. In just two weeks, optimizations using SGLang have unlocked up to a 4X boost in inference speed, ensuring efficient scaling, lower latency, and optimized throughput. The MI300X’s high-bandwidth memory (HBM) and compute power enable execution of complex AI workloads, handling longer sequences and demanding reasoning tasks. With AMD and the SGLang community driving ongoing optimizations—including fused MoE kernels, MLA kernel fusion, and speculative decoding—MI300X is set to deliver an even more powerful AI inference experience.
At a Glance#
DeepSeek-R1 has gained widespread attention for its deep reasoning capabilities, rivaling top closed-source models in language modeling performance benchmarks.
AMD Instinct MI300X GPUs can serve the new DeepSeek-R1 and V3 model in a single node with competitive performance
Users have achieved up to a 4X performance boost compared to the day 0 performance on MI300X, using SGLang. With additional optimizations to be upstreamed in the coming weeks.
Chain of Thought (CoT) benefits from MI300X GPU increased memory bandwidth and capacity advantages over the competition enable faster and more efficient access to large memory, efficiently supporting longer sequence lengths in real-world AI applications.
DeepSeek Model Deployment Challenges#
While the need for large-scale deployment is stronger than ever, it also poses significant technical challenges to achieve optimal inference performance. Deepseek-R1 is a large model with over 640 GB of parameters. Even when trained in FP8 precision, it is infeasible to fit in a single node of 8 NVIDIA H100 GPU. Additionally, the Multi-Head Latent Attention (MLA) and Mixture of Experts (MoE) architecture demands highly optimized kernels to ensure efficient scaling and leveraging of custom optimizations. Lastly, adapting FP8 GEMM kernels to support block-wise quantization is crucial for maximizing throughput and performance, making tuning these kernels essential for effective execution.
Leveraging SGLang on MI300X#
SGLang is a high-performance, open source serving framework for LLMs and VLMs. It offers an efficient runtime, broad model support, and an active community, with growing adoption across the industry. AMD is a key contributor to SGLang and has been working closely with the community to enable and optimize LLM inference on AMD Instinct GPUs. To offer the best out-of-the-box experience on MI300X, SGLang releases prebuilt docker images and docker files. These assets can be used for production deployments and as a starting point for custom images tailored to use-case specific requirements.
Key Takeaways from Serving Benchmark#
Below are a few key takeaways from SGLang serving benchmark on Instinct MI300X:
In just two weeks, we achieved up to a 4× boost in inference performance—using the 671B DeepSeek-R1 FP8 model, not a smaller distilled version—with all optimizations upstreamed to SGLang (Figure 1).
DeepSeek-R1 and V3 performance has been highly optimized for MI300X to leverage its powerful compute power and large HBM memory capacity.
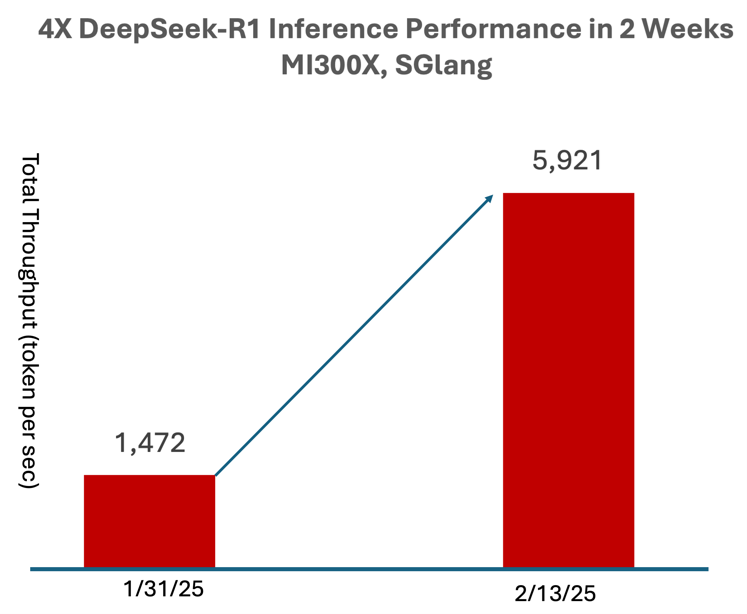
For online inference use cases like chat applications requiring low latency, the SGLang serving benchmark on a single Instinct MI300X node (8 GPUs) demonstrates strong performance, maintaining time per output token (TPOT) below 50ms even with concurrency up to 32 requests. For offline workloads, larger concurrency settings can be used to maximize throughput.
From Figure 2, we can see that for max concurrency ranging from 1 to 32, the performance is primarily memory-bound, whereas for max concurrency between 32 and 64, it shifts to being compute-bound.
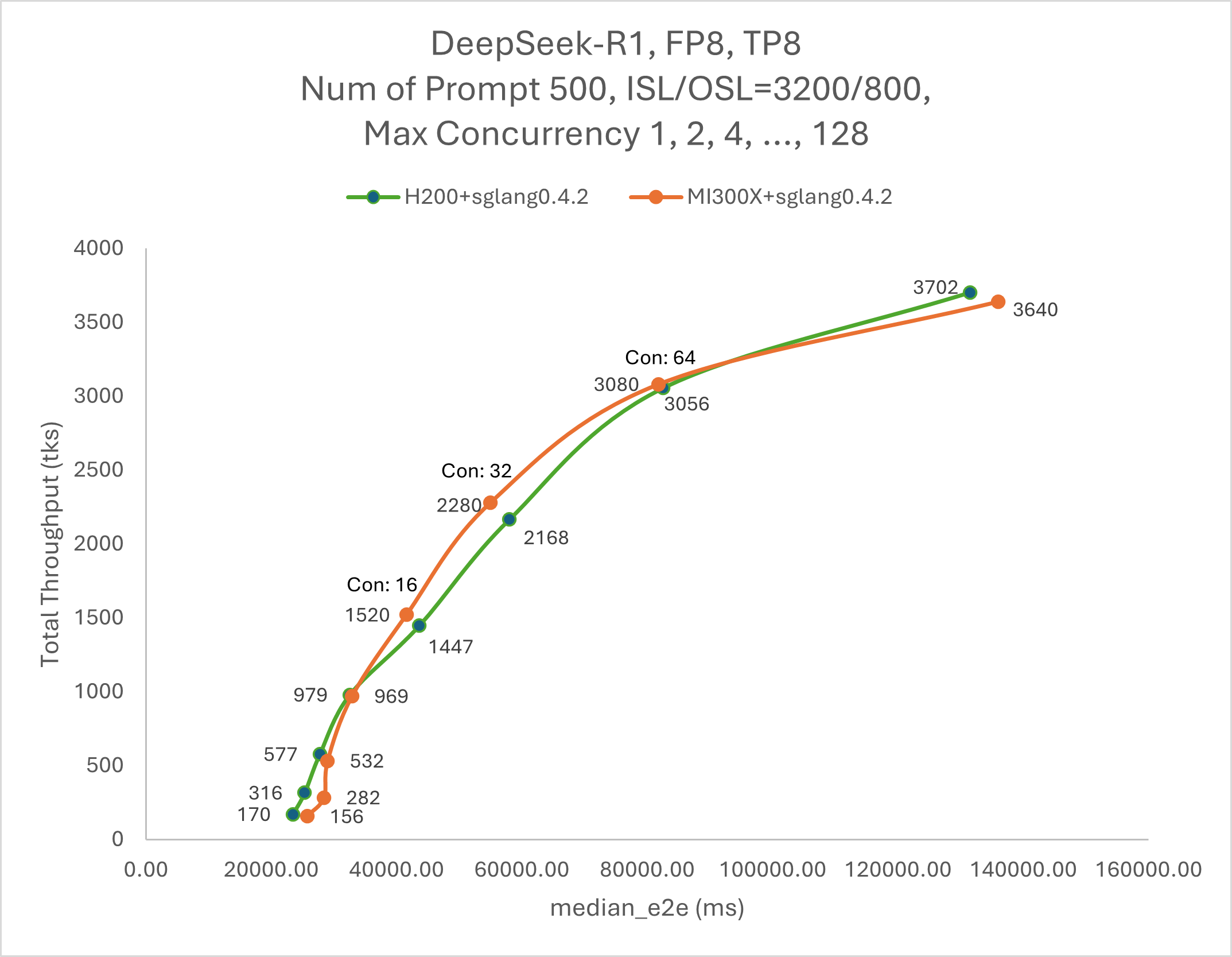
Figure 2: Deepseek R1 Total Throughput(tks) vs Latency(ms) [2]#
How to Reproduce the Benchmark#
Below you will find instructions for MI300X and H200. The following instructions assume that the model has been downloaded already.
On MI300X#
Download the Docker Container:
docker pull rocm/sglang-staging:20250212
Run docker container:
docker run -d -it --ipc=host --network=host --privileged --device=/dev/kfd --device=/dev/dri --device=/dev/mem --group-add render --security-opt seccomp=unconfined -v /home:/workspace rocm/sglang-staging:20250212
docker exec -it <container_id> bash
Run serving benchmark:
HSA_NO_SCRATCH_RECLAIM=1 python3 -m sglang.launch_server --model /workspace/models/DeepSeek-R1/ --tp 8 --trust-remote-code
run client request
concurrency_values=(128 64 32 16 8 4 2 1) for concurrency in "${concurrency_values[@]}";do python3 -m sglang.bench_serving \ --dataset-name random \ --random-range-ratio 1 \ --num-prompt 500 \ --random-input 3200 \ --random-output 800 \ --max-concurrency "${concurrency}" done
On H200#
Download the Docker Container:
docker pull lmsysorg/sglang:v0.4.2.post3-cu125
Run docker container:
docker run -d -it --rm --gpus all --shm-size 32g -p 30000:30000 -v /home:/workspace --ipc=host lmsysorg/sglang:v0.4.2.post4-cu125
docker exec -it <container_id> bash
To run the serving benchmark, you can utilize the same bash commands as with MI300x:
HSA_NO_SCRATCH_RECLAIM=1 python3 -m sglang.launch_server --model /workspace/models/DeepSeek-R1/ --tp 8 --trust-remote-code
run client request:
concurrency_values=(128 64 32 16 8 4 2 1) for concurrency in "${concurrency_values[@]}";do python3 -m sglang.bench_serving \ --dataset-name random \ --random-range-ratio 1 \ --num-prompt 500 \ --random-input 3200 \ --random-output 800 \ --max-concurrency "${concurrency}" done
Check out the demonstration below#
The demo below, showcases a simple chat application running live inference of DeepSeek-R1 on a MI300X server. From this demo, it is easy to see that acceptable latency and throughput can easily be achieved for similar use-cases.
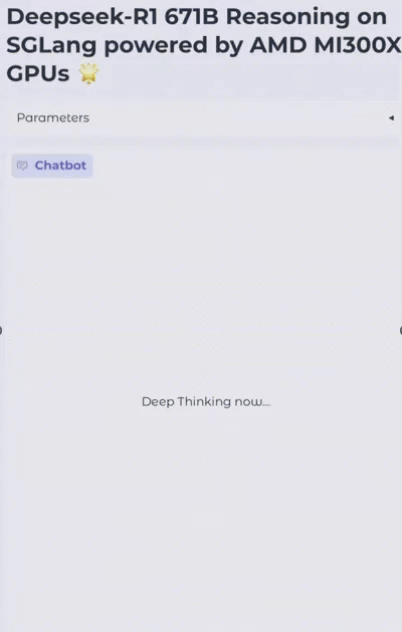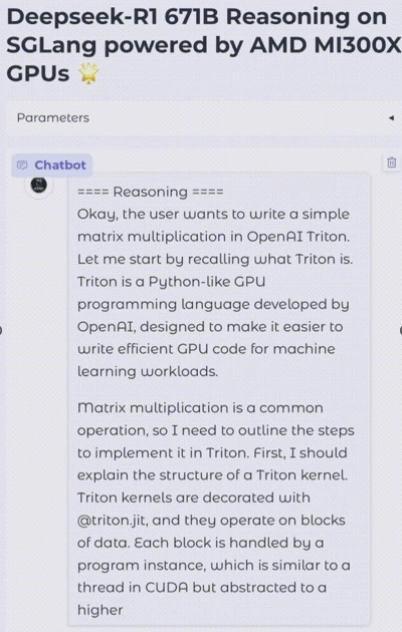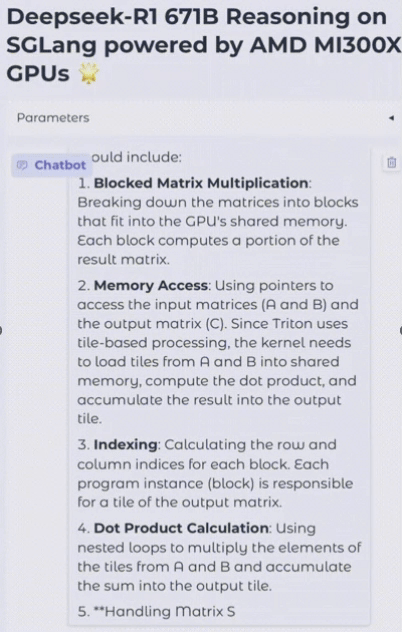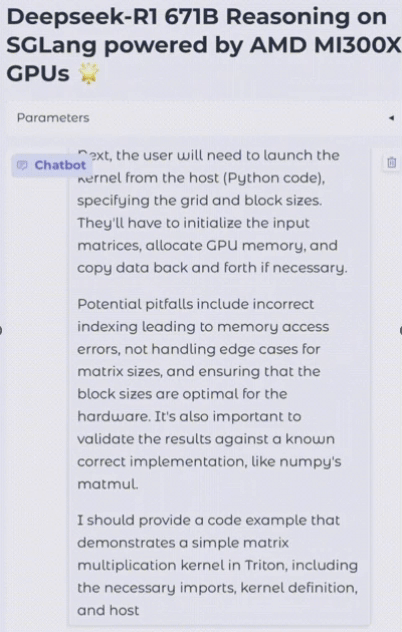
Figure 3: Live Demo Chat application running DeepSeek-R1 on a MI300X Server#
Where do we go from here#
This blog highlights the commitment from AMD in collaboration with SGLang, to deliver the best out of the box user experience of DeepSeek-R1 on Instinct MI300X GPUs. There are more optimizations coming soon that are expected to further boost performance, including but not limited to:
Fused MoE kernel optimization
MLA kernel fusion
Collective communication enhancement
Data Parallelism (DP) and Expert Parallelism (EP)
Prefill and decode disaggregation
Speculative decoding
Try Today#
To get started with DeepSeek-R1 and V3 on MI300X, start by pulling prebuilt SGLang docker container from Dockerhub and following the instructions here
Summary#
DeepSeek-R1 delivers top-tier inference performance on AMD Instinct™ MI300X GPUs. MI300X’s high-bandwidth memory and compute power support efficient scaling, lower latency, and longer sequence handling. AMD, in collaboration with SGLang, continues to enhance performance with MoE kernel optimizations, MLA fusion, and speculative decoding. Get started today by pulling the latest SGLang docker container and unlocking the full potential of DeepSeek-R1 on MI300X.
Additional Resources#
ROCm AI Developer Hub: Access tutorials, blogs, open-source projects, and other resources for AI development with ROCm™ software platform.
SGLang Docker Images || SGLang Docker files for production deployment
SGLang: Fast Serving Framework for Large Language and Vision-Language Models on AMD Instinct GPUs
Endnotes#
[1] Figure 1 herein represents the results of inference performance testing by AMD over 2 weeks in February 2025, with the DeepSeek R-1 FP8 LLM, running the SGLang 0.4.2 serving benchmark on a single node AMD Instinct MI300X GPU (8 GPUs) with concurrency up to 16 looks, serviceable with less than 50ms TPOT, using batch size 1, 2, 4, 8, 16, 32, 64, 128; and 3,200 input tokens and 800 output tokens. Configuration Details: Supermicro AS-8125GS-TNMR2 with 2P AMD EPYC 9654 96-Core Processor with 8x AMD Instinct MI300X (192GB, 750W) GPUs, Ubuntu 22.04.4, and ROCm 6.3.1, 1536 GiB (24 DIMMS, 4800 mts, 64 GiB/DIMM, 20 channels, -1 DIMMs/channel), 8x 3840GB Micron 7450 SSDs, SBIOS 1.8 vs. Supermicro AS-8125GS-THNR with 2P Intel Xeon Platinum 8592V 64-Core Processor with 8x NVIDIA Hopper H200 (141GB, 700W) GPUs, Ubuntu 22.04.5, and CUDA 12.5, 2048 GiB (16 DIMMS, 4800 mts, 128 GiB/DIMM, 20 channels, -1 DIMMs/channel), 8x 3840GB Micron 7450 SSDs, SBIOS 1.8 Actual results will vary depending on hardware configuration, software version, drivers, and optimizations (MI300-076).
[2] Figure 2 herein represents a performance “snapshot” with the stated results based on out of box testing (no hyperparameter tuning on the SGLang backend) by AMD in February 2025, with the DeepSeek R-1 FP8 LLM, running the SGLang 0.4.2 serving benchmark to measure Total Throughput (tks) vs. Latency (ms) of AMD Instinct MI300X GPU vs. NVIDIA H200 GPU. Configuration Details: Supermicro AS-8125GS-TNMR2 with 2P AMD EPYC 9654 96-Core Processor with 8x AMD Instinct MI300X (192GB, 750W) GPUs, Ubuntu 22.04.4, and ROCm 6.3.1, 1536 GiB (24 DIMMS, 4800 mts, 64 GiB/DIMM, 20 channels, -1 DIMMs/channel), 8x 3840GB Micron 7450 SSDs, SBIOS 1.8 vs. Supermicro AS-8125GS-THNR with 2P Intel Xeon Platinum 8592V 64-Core Processor with 8x NVIDIA Hopper H200 (141GB, 700W) GPUs, Ubuntu 22.04.5, and CUDA 12.5, 2048 GiB (16 DIMMS, 4800 mts, 128 GiB/DIMM, 20 channels, -1 DIMMs/channel), 8x 3840GB Micron 7450 SSDs, SBIOS 1.8 Actual results will vary depending on hardware configuration, software version and optimizations. Actual results will vary depending on hardware configuration, software version, drivers, and optimizations (MI300-077).