Optimizing FP4 Mixed-Precision Inference with Petit on AMD Instinct MI250 and MI300 GPUs: A Developer’s Perspective#

Haohui Mai is affiliated with the company CausalFlow.ai.
As frontier large language models (LLMs) continue scaling to unprecedented sizes, they demand increasingly more compute power and memory bandwidth from GPUs. Both GPU manufacturers and model developers are shifting toward low-precision floating-point formats. FP4 (4-bit floating point) quantization has emerged as a particularly compelling solution—for instance, FP4-quantized Llama 3.3 70B models achieve a 3.5x reduction in model size while maintaining minimal quality degradation on benchmarks such as Massive Multitask Language Understanding (MMLU).
However, a critical gap exists in current hardware support. While next-generation GPUs from NVIDIA and AMD provide native FP4 matrix multiplication support, the widely deployed AMD InstinctTM MI250 and MI300 series GPUs lack this capability. This limitation prevents users from leveraging efficient FP4 models on existing AMD hardware investments.
To bridge this divide, we developed Petit – a collection of optimized FP16/BF16 × FP4 mixed-precision GPU kernels specifically engineered for AMD GPUs. Petit enables serving FP4 models on both AMD Instinct MI200 and MI300 series hardware without requiring hardware upgrades.
Petit delivers substantial performance improvements across the board:
1.74x faster end-to-end inference performance on Llama 3.3 70B using SGLang
Up to 3.7x faster execution for equivalent matrix multiplication operations compared to hipBLASLt (AMD state-of-the-art GEMM library)
Open-source availability under BSD license
Production ready – already integrated into SGLang, enabling immediate deployment
This blog explores our optimization journey and the techniques that made these performance gains possible. Petit leverages AMD open software ecosystem while introducing novel optimizations including offline shuffling and low-level hardware-specific enhancements.
Co-designing Performant GPU Kernels with Hardware Architecture#
Modern GPUs achieve massive computational throughput by stacking simple yet compact compute units (CUs) on a single die. However, this hardware design philosophy requires applications to be explicitly co-designed with the underlying architecture to deliver optimal performance. As illustrated in Figure 1, several key co-design principles guided Petit’s development.
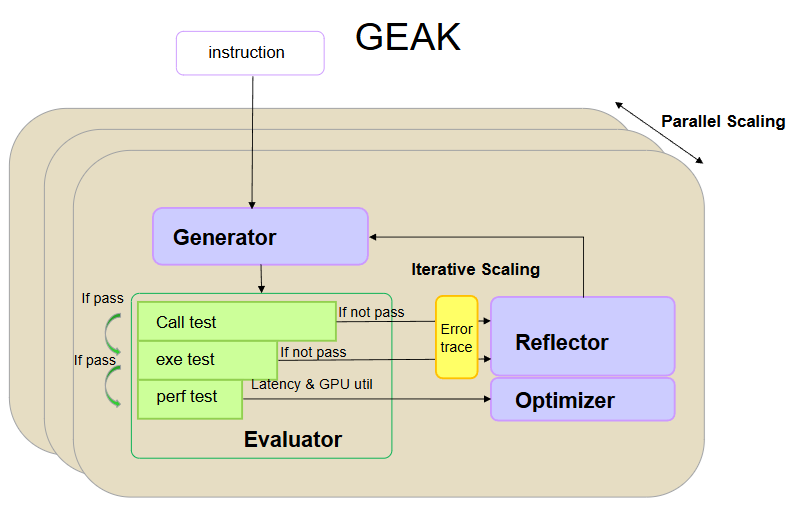
Figure 1: Overview of optimizations in Petit.#
Efficient Dequantizations via pre-processing#
Petit efficiently utilizes specialized MatrixCore hardware on AMD GPUs to accelerate matrix multiplications. MatrixCore enables a wavefront (a group of 64 threads) to collectively multiply two BF16/FP16 16×16 matrices with high efficiency. However, since there’s no native MatrixCore support for FP4 weights on AMD Instinct MI300 series GPUs, Petit must dequantize FP4 weights to BF16/FP16 format while maintaining high efficiency for both loading FP4 weights from memory and preparing them for MatrixCore operations.
This creates a fundamental challenge: optimal memory loading and MatrixCore preparation require matrix B in different data layouts. For memory efficiency, wavefronts should load consecutive 1024-byte chunks. However, MatrixCore expects matrices partitioned into 16×16 tiles with values distributed across wavefronts. Traditional GPU-side data shuffling introduces significant overhead.
The Marlin implementation for NVIDIA GPUs addresses this by pre-arranging matrix B elements on disk, eliminating GPU-side shuffling. Adapting this approach to AMD GPUs, we pack 8 consecutive FP4 values into a 32-bit integer, requiring 31 instructions for dequantization.
Petit goes further by tailoring the bit packing format to AMD GPU capabilities. We rearrange the first 4 FP4 elements in BF8 layout and store the remaining elements in the packed integer’s remaining bits. By utilizing AMD’s unique v_bfrev_b32 and v_cvt_pk_f32_bf8 instructions with sub-dword addressing (SDWA) capabilities, Petit dequantizes 8 FP4 values with only 15 instructions, resulting in a 30% performance improvement in multiplication operations.
Mastering Memory Hierarchies#
GPUs like the AMD Instinct MI300 series feature extremely high arithmetic density (>500), meaning that compute units must perform hundreds of operations per byte to achieve peak FLOPS. Maximizing effective memory bandwidth is therefore essential for performant matrix multiplication kernels. Petit employs proven techniques such as tiling and double buffering using Local Data Store (LDS), while addressing several AMD-specific considerations:
Avoiding LDS Bank Conflicts. AMD GPU LDS is partitioned into 32 banks, allowing 32 concurrent accesses to unique banks per cycle. Bank conflicts serialize accesses, creating performance bottlenecks. This challenge is particularly acute on AMD GPUs since wavefronts contain 64 threads. Petit implements permuted data layouts based on bank designs to achieve conflict-free LDS utilization.
Chiplet and Interconnect. Each AMD Instinct MI300 GPU chiplet (XCD) features a 4MB local L2 cache and shares a 256MB L3 cache across all XCDs via interconnects. While interconnects provide high bandwidth, they introduce significant latency. Petit implements topology-aware workload partitioning that minimizes interconnect traffic, favoring naive grid-based partitions over global stripe partitions when profiling shows that interconnect overhead outweighs the benefits.
Generating High-Quality Machine Code#
GPUs use simple in-order execution units to maximize CU density, but this design makes branches and pipeline stalls particularly expensive. AMD GPUs provide conditional moves and bounded memory instructions to eliminate branches entirely. For example, Petit leverages buffer load and store instructions with specified memory region ranges – the GPU automatically discards out-of-bounds accesses. Similarly, LDS accesses beyond the 64KB limit are automatically handled. This eliminates memory access branches without performance penalties. Additionally, Petit provides compiler hints to overlap MFMA (Matrix Fused Multiply-Add) instructions with memory accesses, effectively hiding memory access latency behind computation.
Standard compilers, however, may not fully utilize advanced GPU ISA capabilities. For instance, intentional out-of-bounds access represents undefined behavior that compilers won’t optimize. These optimizations require careful manual construction and validation.
Performance Results#
End-to-End Inference Performance#
We evaluated Petit’s real-world effectiveness by comparing end-to-end inference performance between FP4 and BF16 models. Testing used both variants of Llama 3.3 70B with SGLang v0.4.10, measuring input and output token throughputs for batch sizes of 10 and 64 requests. Evaluation was performed on an AMD developer cloud VM that has 1× MI300X GPU, 240 GB RAM, and 5 TB SSD. The VM runs ROCm 6.4.2 on Ubuntu 24.04.1.
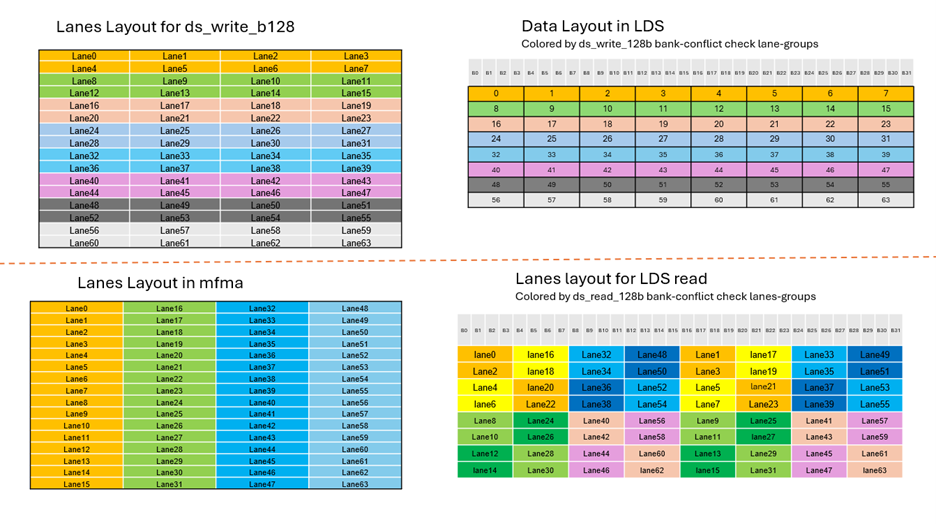
Figure 2: Throughputs of input and output tokens for the offline generation benchmarks in SGLang.#
Figure 2 presents the results of the offline generation benchmark. The offline generation benchmark uses real-world ShareGPT traces as inputs which reflect the production performance. Overall, Petit serving the Llama 3.3 70B FP4 model is 1.74x and 1.60x faster than SGLang serving the original BF16 model. In production scenarios with small batch sizes where performance is memory bandwidth-bound, Petit’s efficient utilization of the 3.5x smaller FP4 models translates directly to superior throughput.
Detailed Performance Analysis#
We then compared Petit’s performance against HipBLASLt. HipBLASLt is AMD’s state-of-the-art GEMM library written in low-level assembly.
Note that these libraries target slightly different workloads:
Petit. Multiplies a BF16 matrix with an NVFP4 matrix (16 elements share an FP8 scale)
HipBLASLt. Multiplies two BF16 matrices.
Though the workloads are not identical, the results present some quantitative ideas of how well Petit performs. We examined actual weight matrix sizes when serving Llama 3 70B, measuring performance with m=16 (decode workloads) and m=256 (prefill workloads), averaging 100 runs after 50 warmup iterations. Both libraries were tuned for optimal configurations.
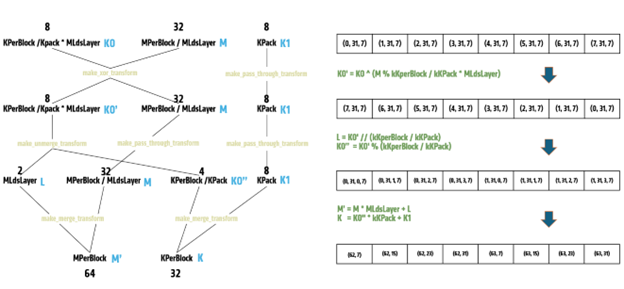
Figure 3: GEMM performances for Petit and HipBlasLt.#
Figure 3 presents the GEMM performances of Petit and HipBlasLt. Petit is efficient: for m=16 (decode-heavy workloads), Petit is up to 3.7x faster than HipBlasLt, with an average improvement of 2.56x. For m=256 (prefill workloads), Petit is up to 1.09x faster than HipBlasLt with comparable average performance.
Petit’s superior performance for small m values stems from memory bandwidth optimization—the 3.5x smaller FP4 models dramatically reduce bandwidth requirements. This makes Petit particularly effective for real-world inference scenarios where m is typically small, aligning perfectly with production deployment patterns.
We studied individual optimization contributions by implementing each technique incrementally: efficient dequantization (Dequant), LDS bank conflict elimination (LDS), topology-aware work placement (Topo), and efficient instruction scheduling (InstSchedule). Figure 4 presents the breakdowns of performance improvements for various sizes of matrices.
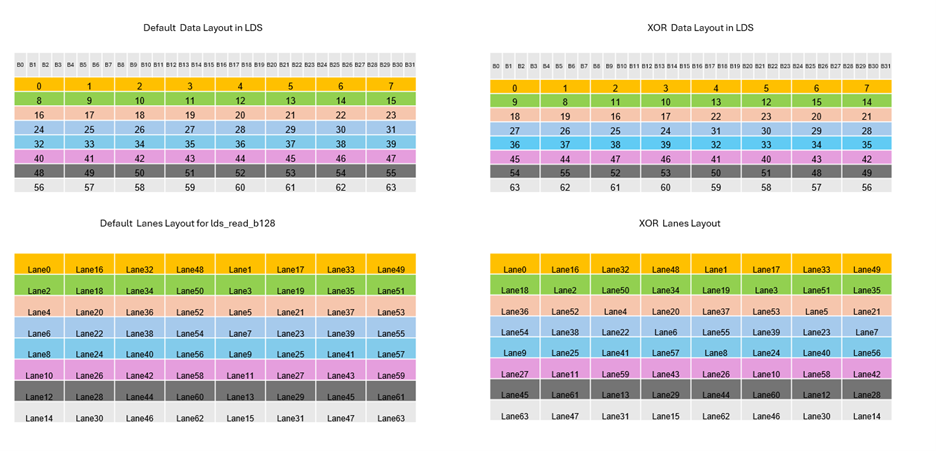
Figure 4: Impacts of individual optimizations of Petit.#
We found that efficient dequantization and LDS optimization provide the largest gains: it generates 70-117% performance improvements. Topology-aware scheduling shows greater impacts for larger m. Interestingly, the results of optimizing instruction scheduling vary and do not always improve performance. Petit provides compiler hints via the amdgcn_sched_group_barrier() intrinsics. It is nontrivial to control the greedy scheduling algorithm inside LLVM to generate the desired sequences, while we were unable to use the exponential solver as it takes too long to run.
Lessons Learned#
Our journey building Petit revealed several insights:
Hardware-software co-design is fundamental. Understanding and designing around hardware architecture should be the foundation of any GPU kernel optimization effort. Without proper co-design, significant performance potential remains untapped regardless of other optimization efforts.
Programming language and compiler support is invaluable. Tools like Triton dramatically improve productivity during prototyping and exploration phases. Petit’s Tensor abstractions, inspired by CuTE, simplified offset calculations and reduced debugging time. While compilers may not fully utilize unique hardware features, exposing performance tuning knobs provides significant value.
Open ecosystems accelerate innovation. Access to open-source codebases provides substantial advantages over black-box approaches. The ability to study, adapt, and build upon existing optimizations accelerates both development and optimization efforts.
Summary#
In this blog, we introduced Petit, a mixed-precision FP4 kernel library tailored for AMD MI250/MI300 GPUs, and demonstrated how hardware-software co-design can deliver substantial real-world performance improvements. Readers gained practical insights into techniques such as efficient memory hierarchy utilization, optimized dequantization, and instruction scheduling, all of which are directly applicable to deploying large-scale models on existing AMD hardware. Beyond the performance numbers, this work highlights a repeatable approach to bridging hardware limitations through careful architectural understanding and targeted kernel design. This effort also complements our other posts on MXFP4 supported OpenAI gpt-oss model and our soon-to-appear FP8 quantization strategies blog, reinforcing co-design as a central theme across our work. Together, these contributions aim to provide developers with both tools and methodology to unlock greater efficiency in modern inference pipelines. Looking ahead, we plan to address current limitations by fixing issues like denormal handling and scaling constraints, while giving users more flexibility in quantization workflows. We also aim to further increase acceleration benefits, extend model support beyond the Llama 3.3 70B model, and add precision formats beyond FP4. In parallel, we will broaden framework integration from SGLang to vLLM, and ensure Petit is ready for next-generation AMD platforms such as AMD Instinct MI355X (gfx950). By pursuing these directions, we intend to deliver both immediate usability and long-term scalability for efficient inference on AMD GPUs.
Our work optimizing Petit for AMD Instinct MI250 and MI300 series GPUs demonstrates the transformative power of hardware-software co-design. Through careful attention to algorithms, memory hierarchy optimization, and low-level assembly techniques, we achieved performance improvements of up to 75x over naive implementations.
The techniques and insights from Petit extend beyond this specific implementation – they represent a methodology for extracting maximum performance from specialized hardware through thoughtful co-design and optimization.
The complete source code of Petit is available at this link.
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.