AMD Integrates llm-d on AMD Instinct MI300X Cluster For Distributed LLM Serving#

AMD has successfully deployed the open-source llm-d framework on AMD Kubernetes infrastructure as part of our efforts for distributed large language model inference at scale. It leverages Kubernetes-native toolkit to streamline LLM serving with features like KV-cache-aware routing, distributed scheduling, and integration with Inference Gateway (IGW). In this blog we showcase initial deployment on an AMD cluster with distributed prefill and decode stages on a Llama model.
llm-d: vLLM-based Kubernetes-native Distributed Inference Framework#
Rapid advancements in the inference serving landscape, combined with the need to optimize LLM workloads, present an opportunity to build frameworks that support a wide range of latency requirements. llm-d is a Kubernetes-native high performance distributed LLM inference framework which provides this infrastructure. llm-d is a modular and layered architecture on top of industry-standard open-source technologies - vLLM, Kubernetes, and Inference Gateway as shown in Figure 1 below.
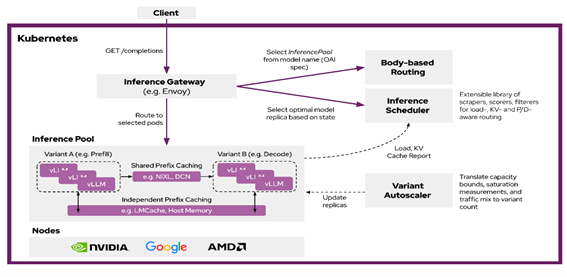
Figure 1. llm-d architecture#
vLLM (vLLM). is the leading open-source LLM inference engine, supporting a wide range of models (including Llama and DeepSeek) and hardware accelerators (including NVIDIA GPU, Google TPU, AMD) with high performance.
Kubernetes (K8s). K8s is an open-source container orchestration engine for automating deployment, scaling, and management of containerized applications. It is the industry standard for deploying and updating LLM inference engines across various hardware accelerators.
Inference Gateway (IGW). IGW is an official Kubernetes project that extends the Gateway API (the next generation of Kubernetes Ingress and Load Balancing API) with inference-specific routing. IGW includes many important features like model routing, serving priority, and extensible scheduling logic for “smart” load balancing. IGW integrates with many different gateway implementations, such as Envoy, making it widely portable across Kubernetes clusters.
Llama Model Deployment on llm-d#
Our initial deployment, based on the llm-d-deployer quickstart configuration and shown in Figure 2, validated the correct provisioning and launch of system components including the gateway, modelservice controller, Redis backend, and endpoint picker, prefill and decode components as shown in Figure 2. The llm-d prefill and decode workers are actively being configured to leverage our internally validated disaggregated vLLM stack –that we have successfully enabled high-performance distributed prefill and decode vLLM inference over MI300X nodes using our patched KV transport backend as shown in Figure 3.
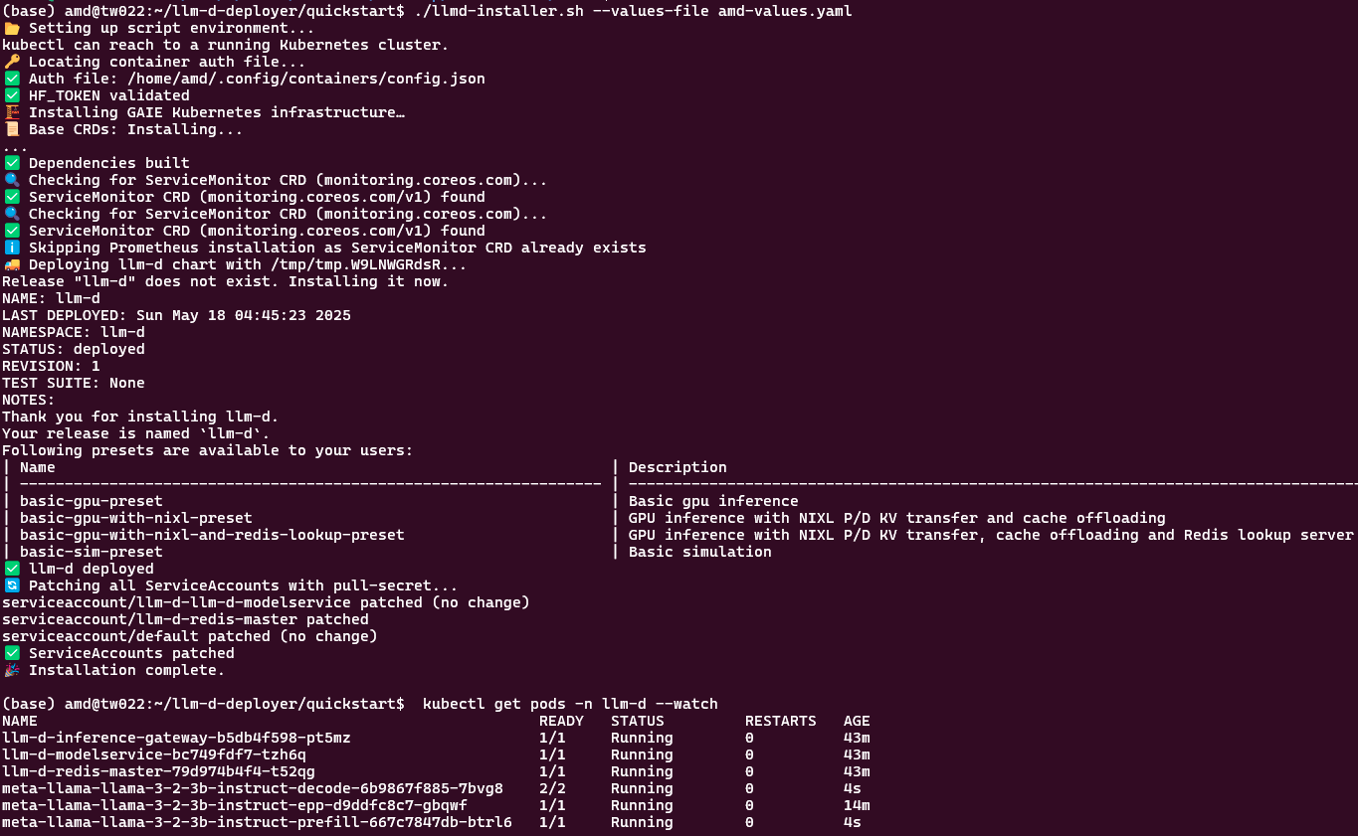
Figure 2. Snapshot of successful Llama model deployment with llm-d#
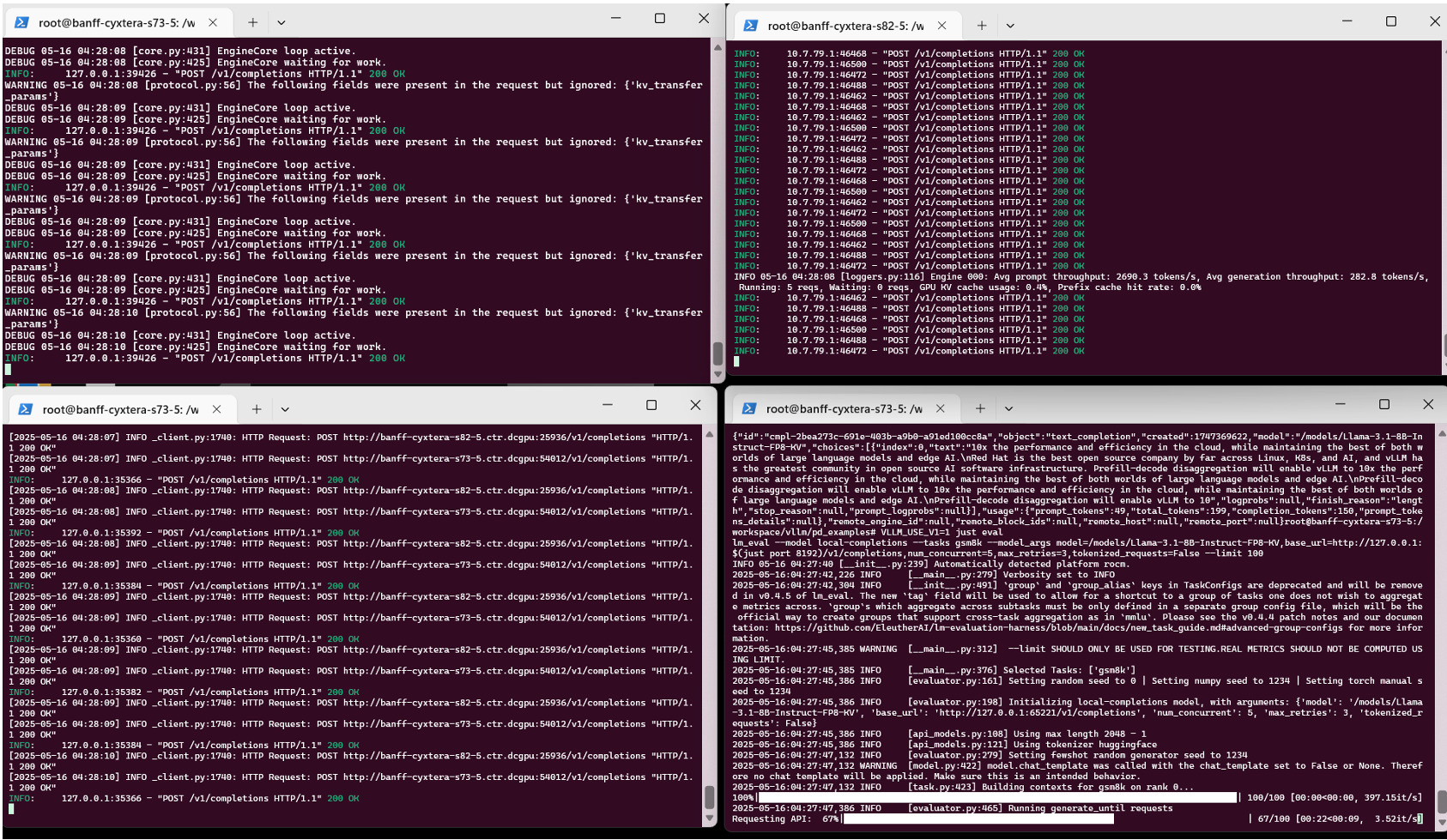
Figure 3. Snapshot of AMD vLLM prefill and decode 2-node inference instance: (upper left) prefill on node 1, (lower left) proxy server on node 1, (upper right) decode on node 2, (lower right) user inputs being served#
Summary#
This announcement marks our early adoption of llm-d as a core tool for distributed inference orchestration and reflects our commitment to supporting open, scalable GenAI infrastructure on AMD platforms. In our upcoming blog, we will provide a step-by-step guide for the complete end-to-end validation of disaggregated prefill/decode within the llm-d framework.
References#
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.