Medical Imaging on MI300X: Optimized SwinUNETR for Tumor Detection#

This blog is part of a series of walkthroughs of Life Science AI models, stemming from this article.
We show how minimal code changes can get you started with the process and results of running the SwinUNETR model for segmentation of lung tumors on AMD Instinct™ MI300X GPUs.
The primary goal was to evaluate the compatibility and performance of this powerful hardware in a real-world medical imaging scenario.
We demonstrate how simple, AMD-specific software optimizations can lead to substantial performance gains, cutting training time by nearly 3x. Furthermore, we show that the MI300X’s massive 192 GB HBM3 memory is a game-changer, allowing for the analysis of significantly larger Regions of Interest (ROIs), up to 25 times larger than what is possible on typical 24GB GPUs.
GPU Acceleration in Medical Imaging#
The field of medical imaging is undergoing a revolution, driven by the immense computational power of modern GPUs. Complex and data-intensive tasks, such as training AI models on high-resolution MRI or CT scans, are now achievable in a fraction of the time they once took. This acceleration is not just an incremental improvement, it enables the development of sophisticated deep learning models like SwinUNETR, which can identify subtle patterns and assist clinicians in diagnosing diseases with greater accuracy. By dramatically speeding up processes like image analysis, segmentation, and reconstruction, GPUs are becoming indispensable tools in advancing patient care and medical research.
The SwinUNETR Model#
SwinUNETR (Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images) is a transformer-based model (see figure 1, below) designed for medical image segmentation, particularly in 3D volumetric data such as CT or MRI scans.
It combines the strengths of two powerful models: (1) Swin Transformer - a hierarchical vision transformer that captures long-range dependencies and contextual information efficiently; and (2) UNETR (UNet with Transformers) - a transformer-based encoder-decoder architecture tailored for medical image segmentation.
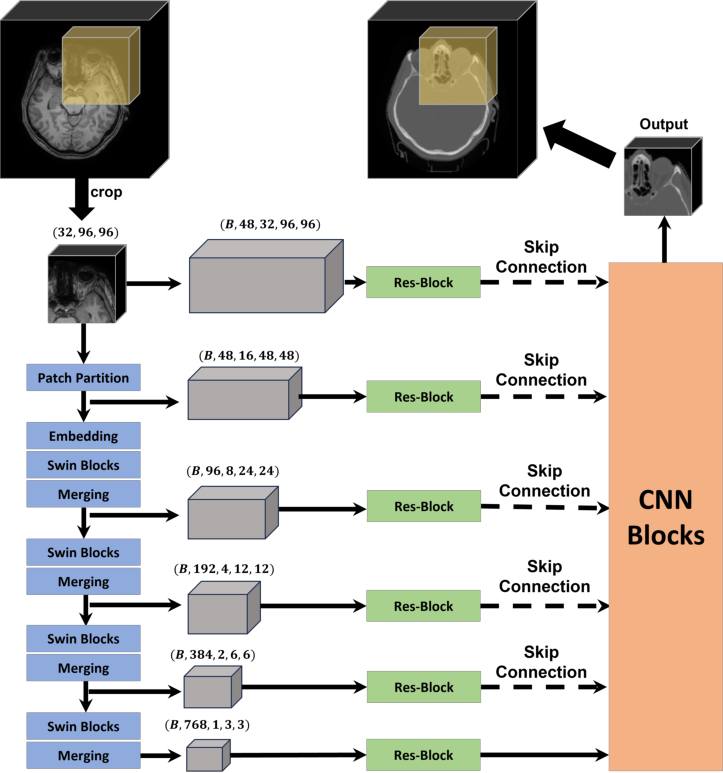
Figure 1. Overview of the SwinUNETR network structure. Adapted from Liu et al. (2024), available under CC BY 4.0 license.#
Training Code#
For this blog, we utilized the original MONAI scripts, and adapted them with the following key modifications:
Replacing outdated code references.
Incorporating specific data and data loading functions for the MONAI TciaDataset dataset from NSCLC-Radiomics.
The modified code can be found here.
Dockerizing SwinUNETR for AMD GPUs#
The simplest way to work with ROCm and PyTorch installations is to use an image that comes pre-packaged with AMD’s ROCm software stack and a compatible version of PyTorch, simplifying the setup process.
Multiple versions are available here. The base image used was rocm/pytorch:rocm6.4_ubuntu22.04_py3.10_pytorch_release_2.6.0.
Dockerfile:
FROM rocm/pytorch:rocm6.4_ubuntu22.04_py3.10_pytorch_release_2.6.0 AS base
# Set environment variables for MIOpen optimizations
ENV MIOPEN_FIND_MODE=1
ENV MIOPEN_FIND_ENFORCE=3
WORKDIR /workspace
# Copy and install required Python packages
COPY requirements.txt requirements.txt
RUN pip install -r requirements.txt --no-cache-dir
# Copy source code
COPY src/ src/
# Set default command
CMD ["bin/bash"]
This Dockerfile sets environment variables to enable MIOpen’s auto-tuning features, which, as we will see, significantly boosts performance. It then installs the necessary Python dependencies and copies the source code into the container.
Running SwinUNETR with Docker Compose#
We use Docker Compose to define the container’s configuration. While you can launch the container using a lengthy docker run command, Docker Compose makes it easier to keep build instructions, hardware access, volumes, and runtime command, in a single file.
Here is an example docker-compose.yml file to run the SwinUNETR training:
services:
swinunetr-train:
build:
context: .
dockerfile: Dockerfile
network_mode: host
ipc: host
devices:
- /dev/kfd
- /dev/dri # Or a specific renderD device like /dev/dri/renderD128
group_add:
- video
security_opt:
- seccomp=unconfined
cap_add:
- SYS_PTRACE
shm_size: 64G
tty: true
volumes:
- ./data:/workspace/data
- ./runs:/workspace/src/runs
command: >
/bin/bash -c "
cd src/ && python main.py
--download_data
--data_root_dir=/workspace/data/datasets
--dataset_labels=GTV-1
--val_every=10
--in_channels=1
--out_channels=1
--warmup_epochs=100
--save_checkpoint
--use_checkpoint
--feature_size=48
--roi_x=96
--roi_y=96
--roi_z=96
--logdir=model_temp
--n_crops_val=4
--n_crops=2
--batch_size=1
--workers=64
--max_epochs=700
"
To build the image and start the training, you can simply run the following command in the same directory as your docker-compose.yml file:
docker compose up --build
This command tells Docker Compose to build the image based on your Dockerfile and then start the swinunetr-train service as defined in the YAML file.
Optimizations for Peak Performance#
Several optimization strategies were employed to maximize the performance of SwinUNETR on the MI300X GPUs.
MIOpen Auto-Tuning#
AMD’s MIOpen is a deep learning primitives library for AMD GPUs. By enabling its auto-tuning feature, MIOpen can find the most optimal kernel for a given operation, which can lead to substantial performance gains. We activated this by setting the following environment variables:
MIOPEN_FIND_MODE=1MIOPEN_FIND_ENFORCE=3
MIOpen provides a set of Find modes which are used to accelerate the Find calls (see MIOpen Docs).
The value 1 for MIOPEN_FIND_MODE is the full Find mode call, which will benchmark all the solvers.
The MIOPEN_FIND_ENFORCE=3 is used to force MIOpen to perform auto-tuning.
This single optimization resulted in a remarkable performance improvement of over 5x in the model’s forward and backward pass. The benefits were even more pronounced when using larger Regions of Interest (ROI).
Notes:
Latest ROCm/pytorch releases: On
ROCm6.4_pytorch_2.6.0or later, same performance is achieved by default, without requiring any additional MIOpen configuration.Older ROCm/pytorch releases: MIOpen Implicit GEMM related errors might appear during algorithm evaluation when AMP is enabled on older releases. However, it should be safe to ignore them. MIOpen will gracefully fall back to an alternative, compatible algorithm when this happens.
Data Loading Enhancements#
The data loading pipeline can often be a bottleneck in training AI models that require significant processing of large 3D medical images. We experimented with the dataset and dataloader parameters, and found two key optimizations that helped mitigate this:
Increased Number of Workers: Utilizing a sufficient number of workers (>32) for the dataloader helped to reduce the time spent waiting for data.
Persistent Workers: Setting
persistent_workers=Truein the PyTorch DataLoader caches the data loaders in memory, avoiding re-instantiation between epochs and saving approximately 14 seconds per epoch.
train_ds = TciaDataset(
root_dir=args.data_root_dir,
collection="NSCLC-Radiomics",
section="training",
download=True,
seg_type="GTV-1",
val_frac=0.2,
num_workers=32, # Increased number of workers to reduce time waiting for data
transform=train_transform,
runtime_cache=False,
)
train_sampler = Sampler(train_ds) if args.distributed else None
train_loader = data.DataLoader(
train_ds,
batch_size=args.batch_size,
shuffle=(train_sampler is None),
num_workers=args.workers,
sampler=train_sampler,
pin_memory=True,
persistent_workers=True # Persist workers between epochs to save time
)
Investigated Optimizations with Limited Impact#
Not all attempted optimizations yielded significant improvements for this specific workload. This was largely expected, as the performance of this particular model is heavily dominated by convolutional operations. Since MIOpen’s auto-tuning was already providing highly optimized kernels for these specific layers, other optimization methods had limited room to deliver significant additional speedups. These included:
PyTorch Compile: Using
torch.compilewith and without max-autotune did not provide additional speedups beyond what MIOpen’s auto-tuning delivered.TunableOps: This feature offered only minor gains (less than 1%) while adding a considerable amount of tuning time.
Mixed Precision Datatype: Changing the automatic mixed precision (AMP) datatype from float16 to bfloat16 resulted in worse performance, likely due to the lack of optimized MIOpen kernels for bfloat16.
Results and Benchmarks#
The combination of the powerful MI300X GPU and our optimization strategies led to a significant reduction in training time, as depicted in figure 2.
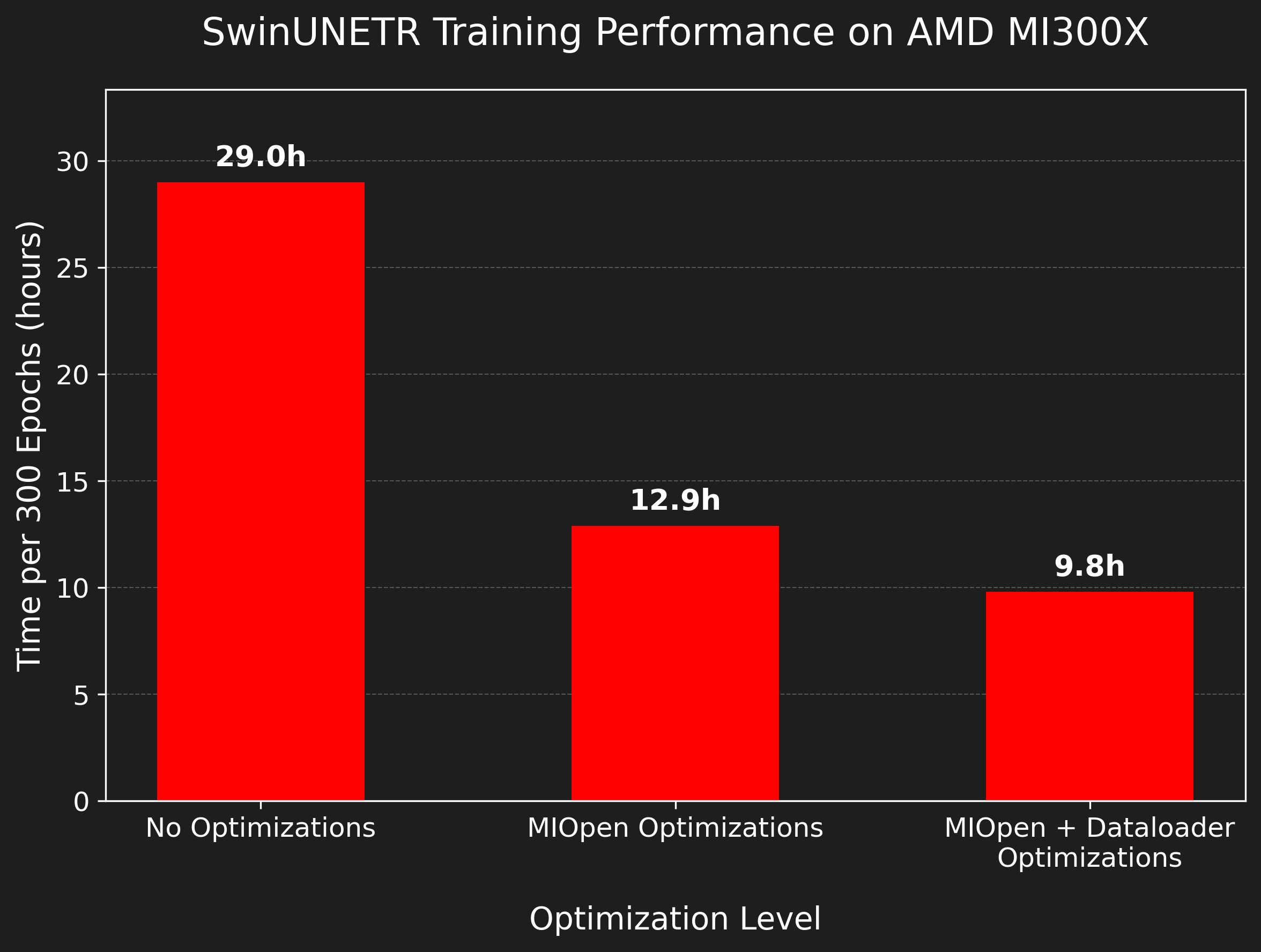
Figure 2. Training time reduction for SwinUNETR on the AMD MI300X with successive optimizations. All runs were performed with default parameters (ROI=96x96x96) on the NSCLC-Radiomics dataset.#
As the results show, after enabling MIOpen’s auto-tuning, the training time was ~3 times faster, demonstrating the immense potential of this feature.
A key advantage of the AMD MI300X is its large HBM3 memory capacity of 192 GB. This allowed for the analysis of significantly larger ROIs (480x480x96), up to 25 times larger than what was possible on a 24GB GPU. This is a critical point, as the ability to process larger ROIs opens up the possibility of significant accuracy improvements. By capturing more of the surrounding anatomical context, the model can make better predictions, although fully realizing these gains often requires corresponding changes to the model architecture or the optimization problem in order to scale effectively.
Prediction example:
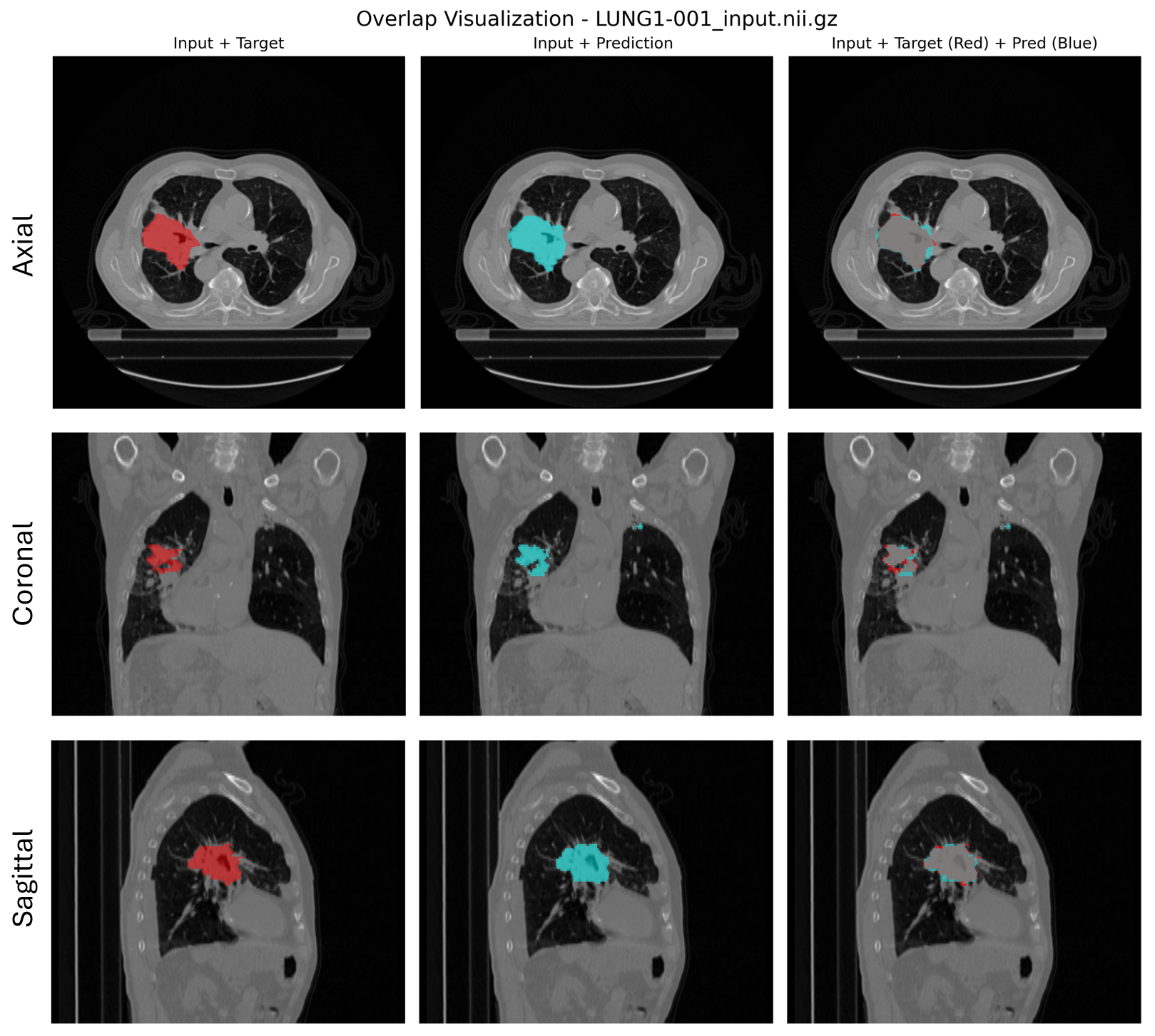
Figure 3. From left to right: CT scan with the ground truth tumor mask (red), the predicted mask (cyan), and an overlap of both masks to visualize prediction accuracy.#
Summary#
The SwinUNETR model for medical image segmentation was successfully executed and optimized on AMD MI300X GPUs. The results clearly demonstrate that with proper software enablement, particularly MIOpen’s auto-tuning capabilities, AMD’s hardware provides a highly performant platform for demanding deep learning workloads. The significant reductions in training time, coupled with the ability to handle much larger datasets due to the increased memory capacity, position the AMD MI300X as a compelling choice for researchers and practitioners in the field of medical imaging and beyond.
Key Deliverables#
This blog provided readers with:
Complete setup guide for running SwinUNETR on AMD MI300X GPUs
Performance optimization strategies including MIOpen auto-tuning that achieved 5x speedup in forward/backward passes
Practical code examples for data loading optimizations and configuration best practices
Real-world benchmarks demonstrating 3x training time reduction and ability to process ROIs 25x larger than typical 24GB GPUs
Troubleshooting insights for common challenges and optimization approaches that work (and those that don’t)
Potential Areas for Further Optimization#
While the overall results were highly successful, several areas could benefit from additional investigation:
Distributed Training: Multi-GPU and multi-node training strategies could further accelerate the training process beyond single-GPU performance.
Loss Function Improvements: Alternative loss functions might scale better with larger ROIs and improve model performance.
Data Processing GPU Acceleration: GPU-accelerated data preprocessing could address the CPU bottleneck identified in data loading stages, potentially using tools like AMD’s ROCm-LS toolkit for life science computational workloads.
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.