Deploying Serverless AI Inference on AMD GPU Clusters#

Deploying Large Language Models (LLMs) in enterprise environments presents a multitude of challenges that organizations must navigate to harness their full potential. As enterprises expand their AI and HPC workloads, scaling the underlying compute and GPU infrastructure presents numerous challenges, including deployment complexities, resource optimization, and effective management of the compute resource fleet. In this blog, we will walk you through how to spin-up production-grade Serverless AI inference service on Kubernetes clusters by leveraging open source Knative/KServe technologies.
Architecture Overview#
A serverless deployment of an inference stack on Kubernetes clusters typically includes the following components: model storage, inference platform, API server and client. These components are depicted in Figure 1 and explained in more details, below.
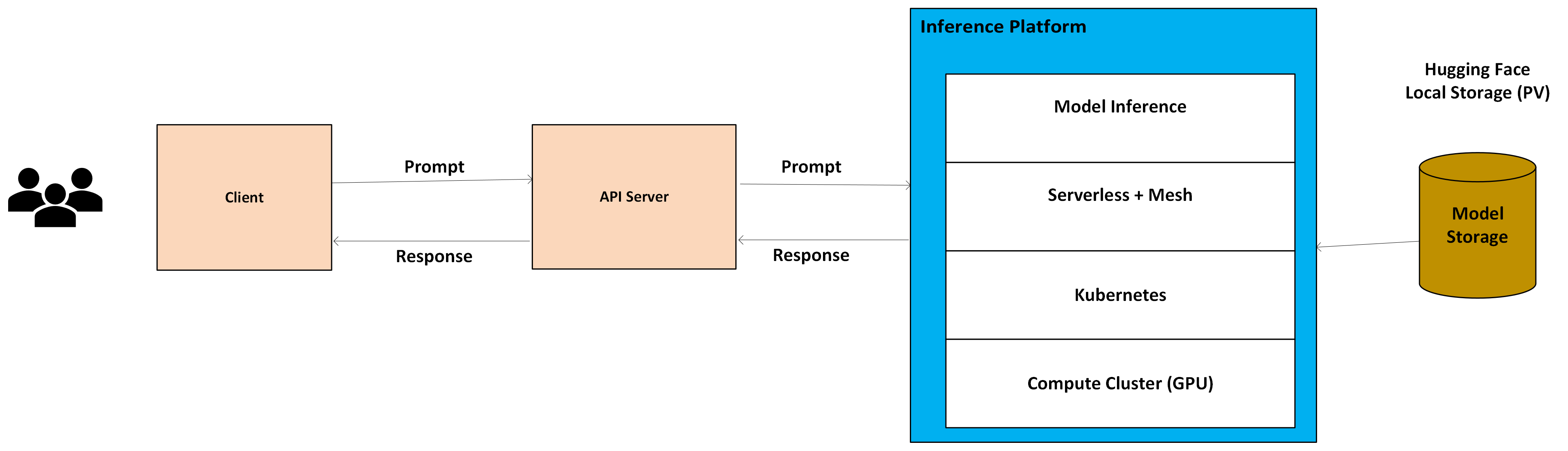
Figure 1: AI Serverless Inference Architecture#
Model Storage#
A centralized repository for storing and versioning ML models. Model can be downloaded from hugging face server or local storage such as PVC to reduce model download and serving times.
Inference Platform#
KServe (formerly KFServing) A Kubernetes-native serverless framework for ML model serving. It provides standardized model inference on Kubernetes and integrates with popular ML frameworks. Knative Serving is an extension of Kubernetes standard services that enables cost-effective autoscaling of ML models. Kubernetes Horizontal Pod Autoscaler (HPA) automatically scales the number of pods based on observed CPU utilization or custom metrics. Service Mesh and Networking Istio a service mesh technology that manages traffic routing, load balancing, and security for the deployed models. Inference platform frameworks run as custom resources in kubernetes clusters for serverless inference.
API Server#
Open AI compatible API server exposes text generation, images generation, model info and versioning APIs to interact with inference platform.
Client#
Client user interface (UI) or Command Line interface (CLI) to interact with Serverless Inference API endpoints.
AI Serverless Inference Architecture#
A reference architecture of an inference stack on Kubernetes clusters consists of the following four components: Kubernetes, Istio, Knative and KServe (see Figure 2 and more details below) .
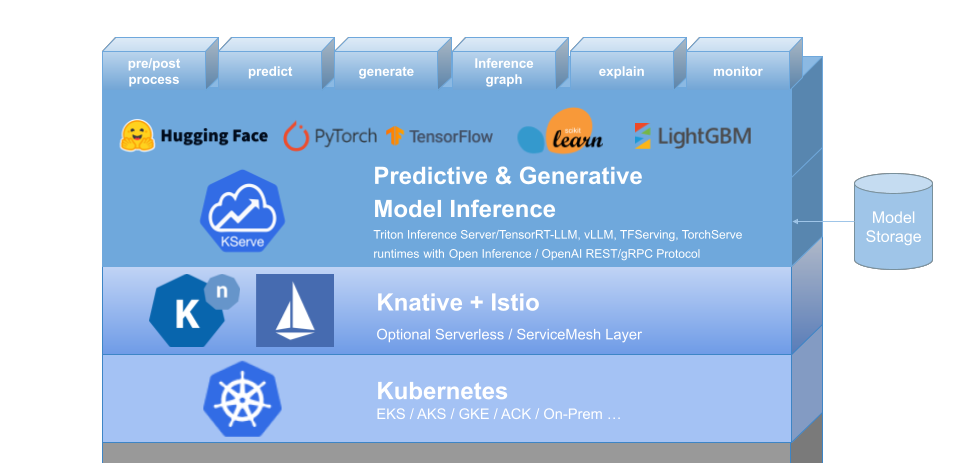
Figure 2: Reference Architecture for AI Serverless Inference#
Kubernetes: Kubernetes is an open-source software that automates the deployment, scaling, and management of containerized applications
Istio: Istio is an open source service mesh that layers transparently onto existing distributed applications.
Knative: Knative Serving builds on Kubernetes to support deploying and serving of applications and functions as serverless containers. Serving is easy to get started with and scales to support advanced scenarios.
KServe: KServe is a standard, cloud agnostic Model Inference Platform for serving predictive and generative AI models on Kubernetes, built for highly scalable use cases.
Step-by-Step Deployment Guide#
To set up the inference service on a Kubernetes GPU cluster, please follow the installation steps outlined below. The complete inference stack can be deployed in a cluster with support from CI/CD tools.
Kubernetes Cluster Setup#
To bring up kubernetes cluster, follow the instructions Kubernetes to download and install k8s and its ecosystem of tools. Kubeternetes installation for linux distribution can be found here: K8s on Linux
Istio Configuration#
We need to install a networking layer for Knative/Kserve serving layer and the following commands install Istio and enable its Knative integration. To download and install Istio:
curl -L https://istio.io/downloadIstio | sh -
cd istio-1.24.2
export PATH=$PWD/bin:$PATH
istioctl install -y --set profile=default
Verify that istio-ingressgateway and istiod are up and running.
cirrascale@amd-k8s-master:~$ kubectl get all,cm,secret,ing -n istio-system
NAME READY STATUS RESTARTS AGE
pod/istio-ingressgateway-5557d58f97-6smkq 1/1 Running 0 28d
pod/istiod-5464c4b5cb-mnl52 1/1 Running 0 28d
...
Cert Manager Installation#
Download and install cert-manager. The default static configuration can be installed as follows:
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.17.0/cert-manager.yaml
Verify all resources under cert-manager namespace are up.
cirrascale@amd-k8s-master:~$ kubectl get all,cm,secret,ing -n cert-manager
NAME READY STATUS RESTARTS AGE
pod/cert-manager-6c899d58d-6bmnb 1/1 Running 1 (8d ago) 28d
pod/cert-manager-cainjector-668c4c6957-nwnht 1/1 Running 1 (8d ago) 28d
pod/cert-manager-webhook-75567f887d-bkgqs 1/1 Running 0 28d
...
Knative Setup#
To install the Knative Serving component:
Install the required custom resources by running the command:
kubectl apply -f https://github.com/knative/serving/releases/download/knative-v1.17.0/serving-crds.yaml
Install the core components of Knative Serving by running the command:
kubectl apply -f https://github.com/knative/serving/releases/download/knative-v1.17.0/serving-core.yaml
Install the Knative Istio controller by running the command:
kubectl apply -f https://github.com/knative/net-istio/releases/download/knative-v1.17.0/net-istio.yaml
Monitor the Knative components until all of the components show a STATUS of Running or Completed.
cirrascale@amd-k8s-master:~$ kubectl get all,cm,secret,ing -n knative-serving
NAME READY STATUS RESTARTS AGE
pod/activator-d984f7999-4f6gs 2/2 Running 0 28d
pod/autoscaler-6986d89b8-zmd2d 2/2 Running 0 28d
pod/controller-79b74d6dd5-x4hfs 2/2 Running 1 (28d ago) 28d
pod/net-istio-controller-5bd5f984c9-bv2hh 1/1 Running 0 28d
pod/net-istio-webhook-6cb6f98666-5n7jf 2/2 Running 0 28d
pod/webhook-7b769dd4fc-hp877 2/2 Running 0 28d
...
KServe Setup#
KServe provides a Kubernetes Custom Resource Definition for serving predictive and generative machine learning (ML) models. It aims to solve production model serving use cases by providing high abstraction interfaces for TensorFlow, XGBoost, ScikitLearn, PyTorch, Huggingface Transformer/LLM models using standardized data plane protocols. It encapsulates the complexity of autoscaling, networking, health checking, and server configuration to bring cutting edge serving features like GPU Autoscaling, Scale to Zero, and Canary Rollouts to your ML deployments.
Create kserve namespace
# Create the manifests
cat << EOF > kserve-namespace.yaml
apiVersion: v1
kind: Namespace
metadata:
labels:
control-plane: kserve-controller-manager
controller-tools.k8s.io: "1.0"
istio-injection: disabled
name: kserve
EOF
# Apply the manifests
kubectl apply -f kserve-namespace.yaml
Create a self-signed (or TLS enabled) serving certificate under kserve namespace
# Create the manifests
cat << EOF > kserve-certificate.yaml
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: serving-cert
namespace: kserve
spec:
commonName: kserve-webhook-server-service.kserve.svc
dnsNames:
- kserve-webhook-server-service.kserve.svc
issuerRef:
kind: Issuer
name: selfsigned-issuer
secretName: kserve-webhook-server-cert
---
apiVersion: cert-manager.io/v1
kind: Issuer
metadata:
name: selfsigned-issuer
namespace: kserve
spec:
selfSigned: {}
EOF
# Apply the manifests
kubectl apply -f kserve-certificate.yaml
Install KServe CRDs and Controller
kubectl apply --server-side -f https://github.com/kserve/kserve/releases/download/v0.14.1/kserve.yaml
Install KServe Built-in ClusterServingRuntimes
kubectl apply --server-side -f https://github.com/kserve/kserve/releases/download/v0.14.1/kserve-cluster-resources.yaml
Verify all resources under kserve namespace are up.
cirrascale@amd-k8s-master:~$ kubectl get all,cm,secret,ing -n kserve
NAME READY STATUS RESTARTS AGE
pod/kserve-controller-manager-7b78d89c86-mzg5s 2/2 Running 3 (8d ago) 28d
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kserve-controller-manager-metrics-service ClusterIP 10.105.21.48 <none> 8443/TCP 28d
service/kserve-controller-manager-service ClusterIP 10.98.175.223 <none> 8443/TCP 28d
service/kserve-webhook-server-service ClusterIP 10.96.124.27 <none> 443/TCP 28d
...
Serving Runtime Setup#
For running Open source models on kserve, we need a serving runtime with popular runtime frameworks such as vllm and deploy the serving runtime with following yaml manifest.
Create a fm namespace for inference service.
kubectl create namespace fm
Pull the vllm docker image from Docker hub
docker pull amdaccelcloud/ce:ubuntu22.04_rocm6.3.2_py3.11_torch2.7.0_vllm_02-03-2025
# Create the manifests
cat << EOF > serving-runtime.yaml
apiVersion: serving.kserve.io/v1alpha1
kind: ServingRuntime
metadata:
name: foundation-model-runtime
namespace: fm
spec:
supportedModelFormats:
- name: foundation-model-vllm
version: "1"
autoSelect: true
priority: 1
containers:
- name: kserve-container
image: amdaccelcloud/ce:ubuntu22.04_rocm6.3.2_py3.11_torch2.7.0_vllm_02-03-2025
command: ["python3", "-m", "vllm.entrypoints.openai.api_server"]
volumeMounts:
- mountPath: /dev/shm
name: dshm
- mountPath: /root/.cache/huggingface/hub
name: kserve-pvc-source
subPath: .cache/huggingface/hub
EOF
# Apply the manifests
kubectl apply -f serving-runtime.yaml
Verify foundation-model-runtime-vllm Serving runtime is created.
cirrascale@amd-k8s-master:~$ kubectl get servingruntime foundation-model-runtime-vllm -n fm
NAME DISABLED MODELTYPE CONTAINERS AGE
foundation-model-runtime-vllm false foundation-model-vllm kserve-container 29h
Inference Service Setup#
Deploy InferenceService with the below manifest for a open source model from hugging face model hub.
# Create the manifests
cat << EOF > inference-service.yaml
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: fm
namespace: fm
spec:
predictor:
model:
runtime: foundation-model-runtime-vllm
modelFormat:
name: foundation-model-vllm
args:
- "--model"
- "meta-llama/Llama-3.2-3B-Instruct"
- "--port"
- "$(PORT)"
- "--dtype"
- "bfloat16"
- "--gpu-memory-utilization"
- "0.9"
- "--distributed-executor-backend"
- "mp"
- "--tensor-parallel-size"
- "1"
- "--num-scheduler-steps"
- "8"
- "--swap-space"
- "16"
- "--enable-chunked-prefill"
- "false"
- "--disable-log-requests"
- "--uvicorn-log-level"
- "info"
EOF
# Apply the manifests
kubectl apply -f inference-service.yaml
# Verify the inference service is up.
$ kubectl get inferenceservice fm-llama-3-2-3b-instruct-vllm -n fm
NAME URL READY PREV LATEST PREVROLLEDOUTREVISION LATESTREADYREVISION AGE
fm-llama-3-2-3b-instruct-vllm http://fm-llama-3-2-3b-instruct-vllm.amd.com True 100 fm-llama-3-2-3b-instruct-vllm-predictor-00002 29h
# Describe inference service and verify no errors
$ kubectl describe inferenceservice fm-llama-3-2-3b-instruct-vllm -n fm
Name: fm-llama-3-2-3b-instruct-vllm
Namespace: fm
Labels: app.kubernetes.io/instance=models
Annotations: kserve.io/redeploy: 1740069643
serving.kserve.io/deploymentMode: Recreate
serving.kserve.io/enable-metric-aggregation: true
serving.kserve.io/enable-prometheus-scraping: true
sidecar.istio.io/inject: true
API Version: serving.kserve.io/v1beta1
...
# Check pods are running
$ kubectl get pods -n fm
NAME READY STATUS RESTARTS AGE
fm-llama-3-2-3b-instruct-vllm-predictor-00002-deployment-c4bcdc 4/4 Running 0 29h
Verify Inference#
Determine ingress IP and ports
$ kubectl get svc istio-ingressgateway -n istio-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
istio-ingressgateway LoadBalancer 10.105.253.92 <pending> 15021:8072/TCP,80:8170/TCP,443:8076/TCP 29d
If the EXTERNAL-IP value is none (or perpetually pending), your environment does not provide an external load balancer for the ingress gateway. In this case, you can access the gateway using the service’s node port.
# Get ingress HOST and PORT
export INGRESS_HOST=$(kubectl get po -l istio=ingressgateway -n istio-system -o jsonpath='{.items[0].status.hostIP}')
export INGRESS_PORT=$(kubectl -n istio-system get service istio-ingressgateway -o jsonpath='{.spec.ports[?(@.name=="http2")].nodePort}')
Send a inference request to model.
curl -v http://${INGRESS_HOST}:${INGRESS_PORT}/v1/completions -H "content-type: application/json" -d '{"model": "meta-llama/Llama-3.2-3B-Instruct", "stream":false, "max_tokens": 128, "prompt": [
"What is Generative AI?",]}'
Summary#
In this blog post, we showed you, step-by-step, how you can implement a highly scalable AI inference solution utilizing a serverless architecture on Kubernetes, harnessing the power of Knative and KServe. The process is streamlined into a few efficient steps, with a particular focus on optimizing performance for AMD GPUs, such as the MI300X. The serverless approach combines the flexibility of Kubernetes with the advanced capabilities of Knative and KServe, enabling seamless deployment and management of AI models. The solution is designed to maximize resource utilization and cost-effectiveness, particularly when dealing with large language models and fluctuating workloads.
By leveraging the strengths of AMD’s MI300X GPU, which outperforms NVIDIA’s H100 in certain LLM inference benchmarks due to its larger memory capacity and higher bandwidth, this setup can significantly enhance inference throughput and reduce latency. The integration of KServe further simplifies model deployment and versioning, while Knative provides robust auto-scaling capabilities, including scaling to zero when idle.
In our upcoming blog posts, we will delve deeper into auto-scaling workloads, including scale-to-zero capabilities for both CPU and GPU, as well as deployments across multiple nodes and multiple GPUs with serverless architecture.
Disclaimers
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED "AS IS" WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.