Hands-On with CK-Tile: Develop and Run Optimized GEMM on AMD GPUs#

Composable Kernel (CK-Tile) for ROCm is used to build portable high-performance kernels for accelerating computing, e.g. HPC, DL and LLMs for training and inference workloads. CK-Tile APIs consist of vendor optimized kernels like GEMM, BatchGemm, fused-MHA, fused-MoE, SmoothQuant, element-wise kernels and many other kernels. This blog focuses on creating the most commonly used GEMM kernel, incorporating a vendor-optimized kernel pipeline and policies, and covers key CK-Tile concepts for quick learning.
Components for CK-Tile Kernels#
To implement a kernel with CK-Tile, you usually need the following classes, which are defined as C++ templates as shown in Figure 1.
Problem Definition is used to define the overall kernel traits, e.g. input/output(IO) tensor data type, layout, workgroup-level tile shapes, and other global flags, e.g. cross-wave scheduler, transposed written e.t.c
Kernel Pipelines are built on Tile Programming APIs, which are used to load and store tiles for computation. As seen, there are vendor optimized pipelines and user can add its own customized pipelines.
Pipeline Policies are built on Coordinate Transformation APIs, which are used to manage data layout in memory. There are vendor optimized policies and user can add its own user customized policies.
Epilogue is used to define any suffix operations after kernel pipeline is done.

Figure 1. Kernel implementation with CK-Tile#
Let’s further decompose vendor optimized pipelines and vendor optimized policies.
GEMM Kernel Overview#
In GPU Programming, it is essential to leverage GPU’s hierarchy memory and Computing Units (CU) structures. Figure 2 below illustrates the hardware hierarchy of AMD MI300x GPU Processor:
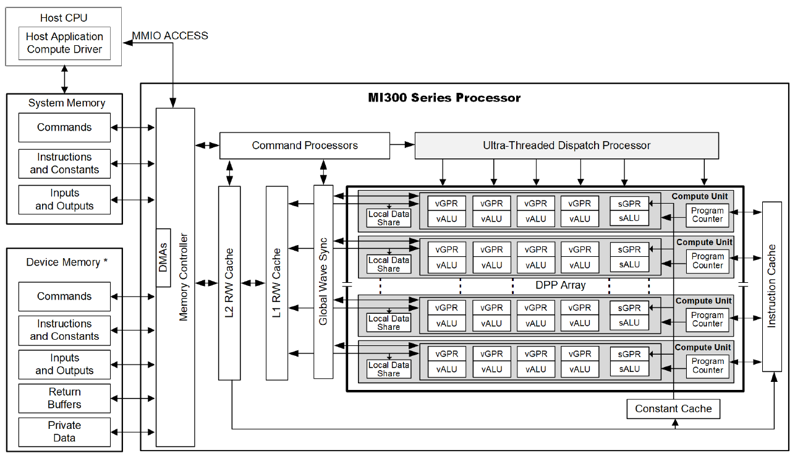
Figure 2. Hierarchy Structures of MI300x Processor#
In logic hierarchy view, the execution of a GEMM kernel is organized in multiple levels - starting from grids, down to workgroups, and further into wavefronts. When it comes to memory, tensors are moved efficiently between different memory types depending on their access patterns and performance needs. Typically, data flows from global memory (DRAM) into faster, on-chip memory like shared memory (LDS) or registers to minimize latency and maximize throughput.
For GEMM Pipeline, the execution hierarchy is as shown in Figure 3.
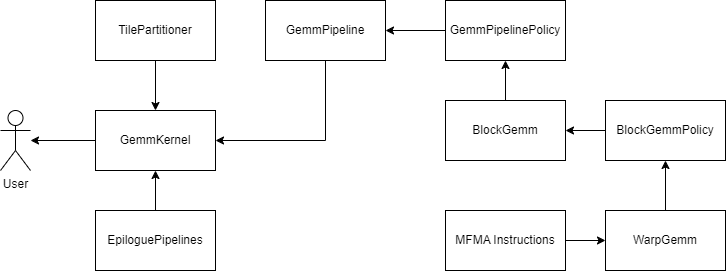
Figure 3. GEMM Kernel Pipeline#
TilePartitioner#
TilePartitioner defines constants, which are used to map the problem size to the GPU hierarchy. Given the problem size with M, N, K, the TilePartitioner defines:
The workgroup-level gemm size kM, kN, kK.
The GridSize along x, y dimension is determined by dividing the problem size M, N into chunks of block-size kM and kN, respectively.
The K dimension size is used to determine the number of iterations that single workgroup have to do in order to calculate dot product of single output element.
GEMMKernel#
GemmKernel is templated with 3 instances: TilePartitioner, GemmPipeline and EpiloguePipelines. The core logic can be described in the following pseudo code:
Transfer from raw 1D memory A, B, C pointers into naive 2D Tensor memory view in actual problem-related coordinate space, by calling make_naive_tensor_view()
Further pad Tensor A, B, C for memory access alignment based on pad flag by calling pad_tensor_view()
Prepare workgroup-level Tensor A,B,C in Transformed Coordinate Space for real GEMM calculation usage by calling make_tile_window()
Launch GemmPipeline Instance for C = A*B GEMM calculation
Launch EpilogePipeline in order to write matrix multiplication result to C tensor. Additionally here user can fuse simple elementwise operations with C tensor’s data.
Keep in mind, the Tile APIs used here, e.g. make_naive_tensor_view(), make_tile_window() are only declaring memory address for matrix A, B, C and make them ready for GEMMPipeline consuming, the real loading or writing of matrix A, B, C is in following GemmPipeline and Epilogue instance.
GEMMPipeline#
We use the vendor-optimized GEMM Pipeline, specifically GemmPipelineAGmemBGmemCRegV1 in this example. The name essentially indicates that Tiles A and B are sourced from Global Memory, while Tile C is stored in Registers. This example demonstrates the first version in a series of GEMM pipelines. Once you become familiar with the pipeline instances you can explore and customize your GEMM pipelines to suit specific workloads.
GEMMPipeline is parameterized with 2 types: GemmPipelineProblem and GemmPipelinePolicy. We will talk about GemmPipelinePolicy in following sections. Let us walk you through GemmPipeline first as shown in Figure 4.
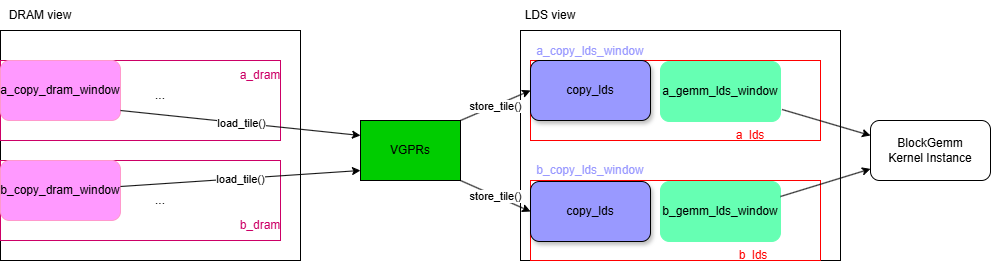
Figure 4. GEMMPipeline#
In each iteration, tiles are first loaded at the workgroup level from DRAM to LDS. If double-buffering is used for LDS, there will be separate copy_lds and gemm_lds for each matrix tile. The copy_lds is responsible for receiving data from DRAM, while the gemm_lds is used for BlockGemm execution. In the case of double-buffering, data copying from DRAM to LDS and GPU computation overlap during each iteration. The copy_lds handles data for the next iteration, while the gemm_lds handles computations for the current iteration.
GEMMPipelinePolicy#
As explained in GemmPipeline instance, tiles are located either on DRAM or on LDS. GemmPipeline Policy instance is used to define the access pattern of how waves would load/write tiles on DRAM or LDS especially. Let’s take GemmPipelineAGmemBGmemCRegV1DefaultPolicy as an example.
The input tensors A and B are initially stored in global memory. The v1 pipeline utilizes LDS for data reuse, which leads to at least two types of policies: the DRAM policy and the LDS policy. The DRAM policy is referred to as MakeADramTileDistribution for tensor A and MakeBDramTileDistribution for tensor B, individually. Inside these functions, the tile_distribution_encoding() is called, which essentially defines the meta information about how workgroups are mapped to the tensor buffers. This includes details such as warp layouts, lanes per dimension, vector load size per lane, and lane repeats. The LDS policy is named as MakeALdsBlockDescriptor, MakeBLdsBlockDescriptor for tensor A, B individually, inside which call 3 low-level transformation primitives to convert 1D raw LDS address to descriptor, which is later used to define tensor views.
BlockGEMM#
Let us now understand how to optimize BlockGemm, specially BlockGemmASmemBSmemCRegV1.
BlockGemm is parameterized with two types: GemmProblem and BlockGemmPolicy. The key aspect here is creating a map between lanes in wavefront and elements within the workgroup-level tiles, and then loop over multiple subtiles within workgroup tile and execute WarpGemm on each of them. Please also note that configs such as wavefront layouts, tile sizes, and wavefront repeat patterns are all determined at compile time. These are not set or modified during the BlockGemm execution itself. So the execution of a BlockGemm instance is loading tile and consuming tile with loops along M, N, K dimensions:
loading tile: loading a subtile of data from A/B tile LDS.
consuming tile: feed the subtiles to the specific MFMA instructions and accumulate result in registers.
The sole purpose of BlockGemmPolicy, for example BlockGemmASmemBSmemCRegV1CustomPolicy, is to specify WarpGemm instance used internally.
WarpGEMM#
WarpGEMM instance encapsulates the low-level MFMA instructions for executing on hardware. We achieve this by
Prepare tiling tensors based on the required input/output tensor shape of the specific instruction
Call the specific instruction with the pre-defined tiling tensors
Below you can find a sample code of WarpGemm MFMA instruction:
struct WarpGemmAttributeMfmaImplF16F16F32M32N32K8 {
AVecType = <fp16_t, 4> ;
kM = 32 ;
kN = 32 ;
kK = 8 ;
kAMLane = 32 ;
kBNLane = 32 ;
kABKLane = 2;
kABKPerLane = 4;
kCMLane = 2 ;
kCNLane = 32 ;
kCM0PerLane = 4; // 4x loops
kCM1PerLane = 4; // 4 consecutive elements
// c_vec += a_vec * b_vec
operator()(CVecType& c_vec, AVecType& a_vec, BVecType& b_vec){
c_vec = __builtin_amdgcn_mfma_f32_32x32x8f16(a_vec, b_vec, c_vec, 0, 0, 0);
}
}
Visualization of WarpGEMM instance shown in Figure 5
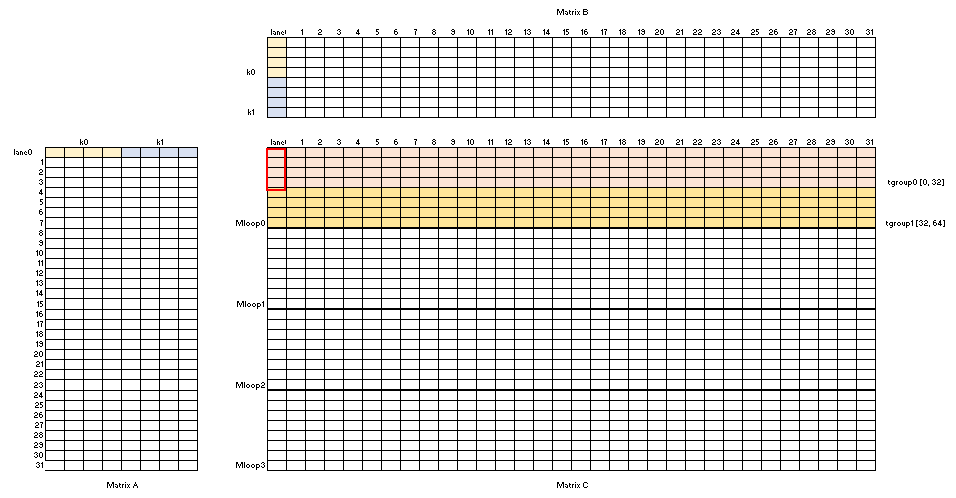
Figure 5. WarpGEMM Instance#
It shows:
\([kM, kN, kK]\): the GEMM MNK shape is [32, 32, 8] for per wavefront
\([kAMLane(kBNLane), kABKLane]\): the lane layouts in wavefront for both tileA, tileB are [32, 2]
\(kABKPerLane\): each lane along K dim loads 4 elements
\([kCMLane, kCNLane]\): the lane layouts in wavefront for output tileC is [2, 32]
\(kCM0PerLane\): there is 4 times repeat along M dim of tileC
\(kCM1PerLane\) : per lane write vector size is 4 along M of tileC
Further more, in CK-Tile implementation, based on GemmPipelinePolicy and BlockGemmPolicy, there are default WarpGemm instances and WarpGemm dispatch selections, the following Figure 6 depicts an overview:
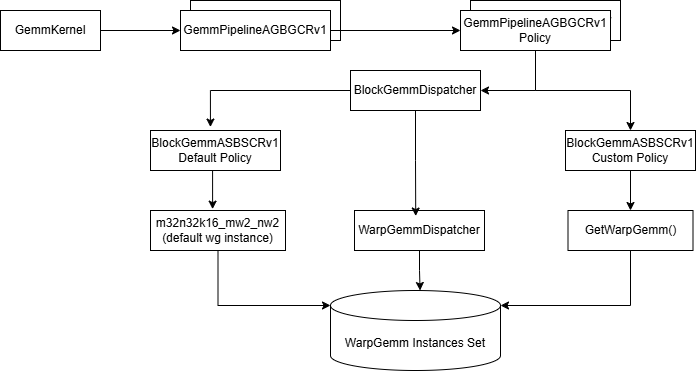
Figure 6. WRAP GEMM visualization#
eXtensible Data Language(XDL) Instructions#
XDL instructions are a set of specialized, low-level instructions used to optimize data movement, memory access, and layout in high-performance computing, GPU programming, and deep learning tasks. They help ensure that data is processed efficiently by transforming its layout and optimizing memory access patterns, leading to improved performance, especially in data-intensive operations like matrix multiplications and tensor computations. For MI300X(CDNA3 arch) GPUs, XDL instructions are mainly used for Matrix Fused Multiply Add(MFMA), you can find details of supported CDNA3 MFMA instructions from here
Building and Running the GEMM Kernel#
From the ck-tile/example/03_GEMM, run the following:
cd composable_kernel
mkdir build && cd build
sh ../script/cmake-ck-dev.sh ../ gfx942
make tile_example_gemm_basic –j
./tile_example_gemm_basic –m 256 –n 256 –k 32
Summary#
This blog walked through the fundamentals of CK-Tile, focusing on the key components behind efficient GEMM kernel construction on AMD Instinct GPUs. For advanced topics such as kernel tuning and fusion examples, please refer to the CK-Tile repository and its accompanying examples.
Terminology#
Table 1 below presents a terminology mapping between CUDA and ROCm:
Concept |
CUDA(NVIDIA) |
ROCM(AMD) |
|---|---|---|
Thread |
Thread |
Work-item |
Warp |
Warp (32 threads) |
Wavefront (32/64 work-item) |
Thread Block |
Block |
Work Group |
Shared Memory |
Shared Memory |
LDS (Local Data Share) |
Global Memory |
Global Memory |
Global Memory |
Registers |
Register |
VGPR, SGPR |
Compute Units |
SM (Streaming Multiprocessor) |
CU (Compute Unit) |
Accelerators |
Tensor Core |
Matrix Core |
Parallel Strategy |
SIMT (single-instruction, multi-threads) |
SIMD (single-instruction, multi-data) |
Table 1. CUDA to ROCm Terminology Mapping for GPU Programming
Acknowledgement#
We would like to express our special thanks for the support from the AMD CK Core team members.
Additional Resources#
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.