Unleash Full GPU Potential: Overlap Communication and Computation with Triton-Distributed#

In distributed computing, AI workloads demand both massive parallelism and efficient data movement. A primary challenge lies in effectively overlapping computation with communication to maximize performance. GPUs are excellent at crunching numbers. However, their full potential often remains untapped due to relatively long inter-GPU communication. This results in their computing units staying idle for large amounts of time while waiting for data transfer from other nodes. In this blog, we will show how you can use the Triton-Distributed framework to generate kernels that overlap communication and computation, resulting in performance that can rival highly optimized libraries.
What is the Triton-Distributed Compiler?#
Triton-Distributed is a novel extension of the OpenAI Triton framework that enables concurrent execution of computation and cross-GPU data transfers. It aims to transform how developers tackle the fundamental trade-off between performance and compiler-induced latency overhead. Triton-Distributed empowers developers to write kernels that automatically optimize both local computations and cross-device communication patterns. For example, a single Triton-Distributed kernel can dynamically adjust memory access patterns to hide latency during operations like all-reduced. Triton-Distributed Compiler inherits the strengths of OpenAI Triton, a compiler renowned for simplifying GPU programming. In CUDA/HIP, crafting optimized kernels requires deep expertise in hardware microarchitecture and low-level programming, which requires intricate hand-tuning low-level code (error-prone and time-consuming) or rely on rigid libraries that limit flexibility. Triton changes this equation and offers a higher level of abstraction while maintaining flexibility, efficiency and productivity.
By encapsulating complex optimizations, such as shared-memory management, tensor/matrix core usage, and warp level parallelism into reusable compiler passes, Triton-Distributed lets developers focus on algorithmic innovation rather than low level architectural specifics. Imagine writing a matrix multiplication kernel once and achieving performance rivaling hand-tuned libraries for multiple input configurations across multiple GPU nodes. Triton-Distributed aims to deliver: efficient kernels comparable to highly-optimized libraries including Distributed-GEMM, cuBLASMp and FLUX. With its high-level abstractions and productivity-focused design, Triton-Distributed brings performance portability to a broader audience, abstracting away the complexity of distributed GPU programming into an accessible, extensible compiler stack. Let’s explore how to get started with Triton-Distributed.
Getting Started For Triton-Distributed#
Below are the steps to install and use Triton-Distributed on AMD GPUs.
Step 1. Install Triton-Distributed from source:
Refer to the Build Guide for best practices on compiling and configuring Triton-Distributed for AMD GPUs.
Step 2 How to use Triton-Distributed
Triton-Distributed provides a set of ease-of-use primitives to support the development of distributed compute-communication overlapping kernels. All the primitives are exposed by triton.distributed.language, which are additional features that add-on to the main Triton features, making Triton totally composable while not modifying core Triton The primitives are grouped into low-level and high-level sets. While the high-level primitives (as described in the MLSys 2025 paper) will be released in the future, the current release includes the following low-level primitives:
Low-level primitives - Context Querying Primitives
rank(axis=-1, _builder=None)
num_ranks(axis=-1, _builder=None)
symm_at(ptr, rank, _builder=None)
Low-level primitives - Singal Control Primitives
wait(barrierPtrs, numBarriers, scope: str, semantic: str, _builder=None)
consume_token(value, token, _builder=None)
notify(ptr, rank, signal=1, sig_op="set", comm_scope="inter_node", _builder=None)
Users can combine the communication part with computation part to design overlapping kernels.
Test and Reproduce Performance with Triton-Distributed on AMD CDNA3#
Below are the steps to test and reproduce the performance with Triton-Distributed on AMD CDNA3 for GEMM ReduceScatter on single node.
GEMM ReduceScatter on Single Node#
Below is the script for testing and reproducing the performance of ReduceScatter GEMM on a Single Node:
#!/bin/bash
set -e
SHAPES=(
"8192 4096 12288"
"8192 4096 14336"
"8192 3584 14336"
"8192 4608 36864"
"8192 8192 28672"
"8192 8192 30720"
)
for shape in "${SHAPES[@]}"; do
read -r m n k <<< "$shape"
echo "Testing GEMM_RS shape: m=$m, n=$n, k=$k"
bash ./third_party/distributed/launch_amd.sh ./third_party/distributed/distributed/test/amd/test_gemm_rs_intra_node.py ${m} ${n} ${k} --warmup 5 --iters 20
done
Figure 1 below shows the performance boost when using Triton distribution vs PyTorch+RCCL. On tuned cases, we see a 30% better with this approach.
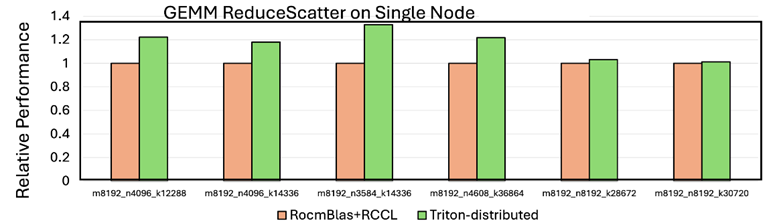
Figure 1: Performance of Intra-node GEMM ReduceScatter on AMD GPUs ^1#
AllGather GEMM on Single Node#
Below is the script for testing and reproducing the performance of AllGather GEMM on a Single Node
#!/bin/bash
set -e
SHAPES=(
"8192 4096 12288"
"8192 4096 14336"
"8192 3584 14336"
"8192 4608 36864"
"8192 8192 28672"
"8192 8192 30720"
)
for shape in "${SHAPES[@]}"; do
read -r m n k <<< "$shape"
echo "Testing AG_GEMM shape: m=$m, n=$n, k=$k"
bash ./third_party/distributed/launch_amd.sh ./third_party/distributed/distributed/test/amd/test_ag_gemm_intra_node.py ${m} ${n} ${k} --warmup 5 --iters 20
done
Figure 2 below shows the performance boost when using Triton distribution vs PyTorch+RCCL. On tuned cases, we see a 30 -40% better with this approach.
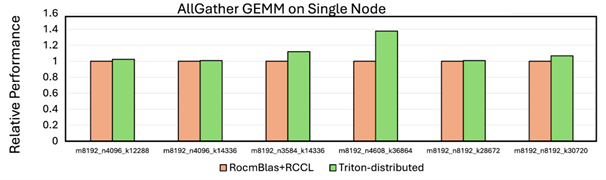
Figure 2: Performance of Intra-node AllGather GEMM on AMD GPUs ^2#
Summary#
Triton-Distributed is a compiler built on OpenAI’s Triton framework and represents a breakthrough in distributed GPU computing. It addresses one of the most pressing challenges in AI workloads—efficiently balancing computation with inter-GPU communication. By enabling the overlap of computation and communication, Triton-Distributed allows kernels to continue processing while data is transferred, thereby maximizing GPU utilization, reducing idle cycles, and improving system-wide throughput. Triton-Distributed inherits Triton’s high-level abstractions, eliminating the need for deep hardware expertise or rigid libraries. It enables the creation of portable, high-performance distributed kernels—like Distributed-GEMM—that rival hand-optimized CUDA implementations. By encapsulating complex optimizations such as shared memory management and warp-level parallelism into compiler passes, it empowers developers to focus on algorithmic design rather than low-level details. Triton-Distributed brings these capabilities to AMD GPUs, broadening access and performance portability across hardware platforms for developers. It provides a cutting-edge solution that enables developers to unlock the full potential of AMD GPU hardware, push the boundaries of distributed performance, and accelerate innovation in AI systems.
Acknowledgement#
Triton-Distributed Compiler on AMD GPUs is the result of a close collaboration between the AMD ROCm software engineering team and the ByteDance Seed Team ; we sincerely appreciate the great efforts and contributions of everyone involved in making this collaboration a success. We also greatly appreciate OpenAI’s open-source Triton project, which this effort is based upon.
Additional Resource#
Triton-Distributed on AMD GPUs platform
Bytedance Seed Triton-Distributed
Bytedance Flux - Fine-grained Computation-communication Overlapping GPU Kernel Library
Endnotes#
[1] Testing done by AMD on 04/28/2025, results may vary based on configuration, usage, software version, and optimizations.
SYSTEM CONFIGURATION
AMD CDNA3 platformSystem Model: Supermicro
AS-8125GS-TNMR2
CPU: 2x AMD EPYC 9654 96-Core Processor
NUMA: 2 NUMA node per socket. NUMA auto-balancing disabled/ Memory: 2304
GiB (24 DIMMs x 96 GiB Micron Technology MTC40F204WS1RC48BB1 DDR5 4800
MT/s)
Disk: 16,092 GiB (4x SAMSUNG MZQL23T8HCLS-00A07 3576 GiB, 2x SAMSUNG
MZ1L2960HCJR-00A07 894 GiB)
GPU: 8x AMD CDNA3 192GB HBM3 750W
Host OS: Ubuntu 22.04.4
System BIOS: 3.2
System Bios Vendor: American Megatrends International, LLC.
Host GPU Driver: (amdgpu version): ROCm 6.3.1
[2] Testing done by AMD on 04/28/2025, results may vary based on configuration, usage, software version, and optimizations.
SYSTEM CONFIGURATION
AMD CDNA3 platformSystem Model: Supermicro
AS-8125GS-TNMR2
CPU: 2x AMD EPYC 9654 96-Core Processor
NUMA: 2 NUMA node per socket. NUMA auto-balancing disabled/ Memory: 2304
GiB (24 DIMMs x 96 GiB Micron Technology MTC40F204WS1RC48BB1 DDR5 4800
MT/s)
Disk: 16,092 GiB (4x SAMSUNG MZQL23T8HCLS-00A07 3576 GiB, 2x SAMSUNG
MZ1L2960HCJR-00A07 894 GiB)
GPU: 8x AMD other GPU 192GB HBM3 750W
Host OS: Ubuntu 22.04.4
System BIOS: 3.2
System Bios Vendor: American Megatrends International, LLC.
Host GPU Driver: (amdgpu version): ROCm 6.3.1
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.