Accelerated LLM Inference on AMD Instinct™ GPUs with vLLM 0.9.x and ROCm#

AMD is pleased to announce the release of vLLM 0.9.x, delivering significant advances in LLM inference performance through ROCm™ software and AITER integration. This release provides a variety of powerful optimizations and exciting new capabilities to the AMD ROCm software ecosystem as shown in Figure 1, below. Whether you are a developer or a researcher, this release is designed to help you unlock new levels of performance and explore wider model support on AMD Instinct™ GPUs.
For anyone deploying LLMs in real-world scenarios, every millisecond of latency whether it’s time to first token (TTFT), time per output token (TPOT), or overall throughput plays a crucial role in providing a seamless user experience and operational efficiency. In this blog, we will discuss how vLLM 0.9.x, with its deep integration with ROCm software, offers a range of powerful enhancements designed to meet these performance-critical needs.

Figure 1. Key Enhancements in vLLM 0.9.x for AMD ROCm#
AITER Integration and ROCm Optimization#
This release is packed with features that leverage the full potential of AMD hardware, focusing on integrating and harnessing the power of AI Tensor Engine for ROCm (AITER) framework, along with other targeted kernel optimizations. AITER serves as the centralized repository of high-performance AI operators from AMD, providing the foundational building blocks for many of the performance leaps seen in vLLM 0.9.x. By integrating versatile and highly optimized operators in AITER, vLLM 0.9.x taps into a rich ecosystem of kernels (from Triton, composable kernel, HIP, and ASM) designed for maximum efficiency on AMD Instinct GPUs. This allows vLLM to accelerate critical components of LLM serving, leading to better concurrency, reduced latency, and significantly higher throughput.
All AITER integration pull requests are accompanied by `lm_eval` accuracy evaluations to ensure that performance gains do not compromise model accuracy.
vLLM 0.9.x specifically expands and refines AITER support on ROCm through several key integrations:
High-Throughput FP8 Inference with AITER Block-Scaled GEMM#
vLLM 0.9.x now incorporates highly optimized block-scaled GEMM kernels in AITER. As we scale large language models (LLMs) and transition to low-precision formats like FP8, it is critical to ensure numerical stability without compromising performance. That is where block-scaled GEMM comes into play. Instead of applying a single global scale to an entire matrix, block-scaled GEMM partitions matrices into smaller blocks and applies per-block scaling factors based on the value range within each block. (Note that this applies to DeepSeek models only). To enable this functionality, we need to set both VLLM_ROCM_USE_AITER and VLLM_ROCM_USE_AITER_LINEAR to 1.
AITER block-scaled FP8 GEMM integration demonstrated up to
19.4% increase in request throughput [1]
18.6% increase in output token throughput [1]
Advanced Attention and MoE Mechanisms#
1. AITER Multi-head Latent Attention (MLA) on V1 Engine [2]#
We’ve significantly enhanced vLLM’s V1 engine by fully integrating high-performance MLA attention in AITER. This is a critical update for achieving top performance on models like DeepSeek-V3, bringing the V1 engine’s capabilities on par with the V0 engine.
2. AITER Biased Group TopK for DeepSeek-V3#
Traditional mixture-of-experts (MoE) models select Top-K experts per token based on gating scores, often causing imbalanced expert usage. The Biased Group TopK strategy improves this by first grouping experts, then having each token select groups and Top-K experts within them using adjusted gating scores, leading to more balanced and efficient expert utilization. Tailored for the DeepSeek-V3/R1 architecture, this AITER kernel optimization further enhances sampling performance by leveraging specialized AITER operators. For developers and researchers working with DeepSeek-V3 on AMD platforms, leveraging AITER’s Biased Group TopK implementation can lead to substantial performance gains and more efficient model deployment.
AITER Biased Group TopK integration demonstrated up to:
4.9% request throughput increase [3]
6.1% reduction in Mean TTFT on the V1 engine in its targeted vLLM test [3]
3. Enhanced MoE Optimizations#
Enhanced Mixture of Experts (MoE) models are gaining popularity due to their ability to activate a small subset of specialized “experts” for each input token. These models also feature advancements in gating mechanisms, expert utilization, and training stability, making MoE more efficient and scalable. The vLLM 0.9.x version brings significant improvements, leveraging specialized operators in AITER.
Leveraging AITER fused MoE Kernels [4]#
The AITER package introduced a new external API, fused_moe, for the AITER fused MoE kernels. This API automatically selects and invokes the appropriate type of MoE kernel based on the specified quantization method. By integrating AITER’s optimized MoE operators, such as moe-2stages and fp8-blockscale_g1u1, the fused_moe API ensures efficient MoE execution by automatically choosing the most optimized backend for the task.
Optimized Qwen/Qwen3 Triton fused MoE Configs [5,6]#
Specific Triton tuning for popular Qwen MoE models (e.g., Qwen3-235B-A22B, Qwen3-30B-A3B) on MI300X, leveraging AITER fused MoE capabilities. This helps to deliver up to +16.83% request throughput for Qwen3-235B-A22B.
Scaling Llama 4 Models with AITER Fused Kernels and ROCm Optimizations#
The combination of AITER’s fused MoE, advanced attention kernels, and other ROCm optimizations delivers significant throughput gains across various MoE models. Our benchmarks on Llama 4 models show substantial improvements over baseline implementations
Llama4-Scout-17B-16E: Throughput gains ranging from ~33% (ISL/OSL: 1000/1000) to ~60% (ISL/OSL: 10000/1000) comparing with baseline;
Llama4-Maverick-17B-128E-Instruct: Throughput gains ranging from ~58% (ISL/OSL: 1000/1000) to ~67% (ISL/OSL: 10000/1000).
These improvements were observed across a variety of input/output sequence length (ISL/OSL) combinations—including 2000/150, 1000/1000, 5000/1000, 10000/1000, and 3200/800—under a maximum concurrency setting of 64.
Figures 2 and 3 (below) illustrate these throughput deltas compared to baseline implementations without AITER fused MoE or ROCm optimizations. See the section “In-Depth Performance Analysis: AITER Configurations and Attention Backends in vLLM V1” for details on Configuration 1, which serves as the baseline, and Configuration 4, which represents the optimized setup used to achieve the performance improvements shown in Figures 2 and 3.
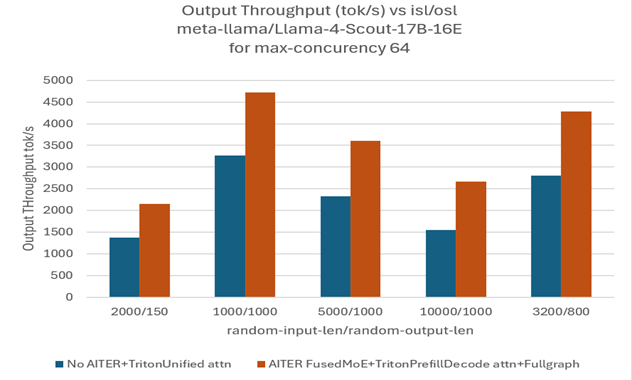
Figure 2. Performance comparison on model Llama4-Scout-17B-16E [7]#
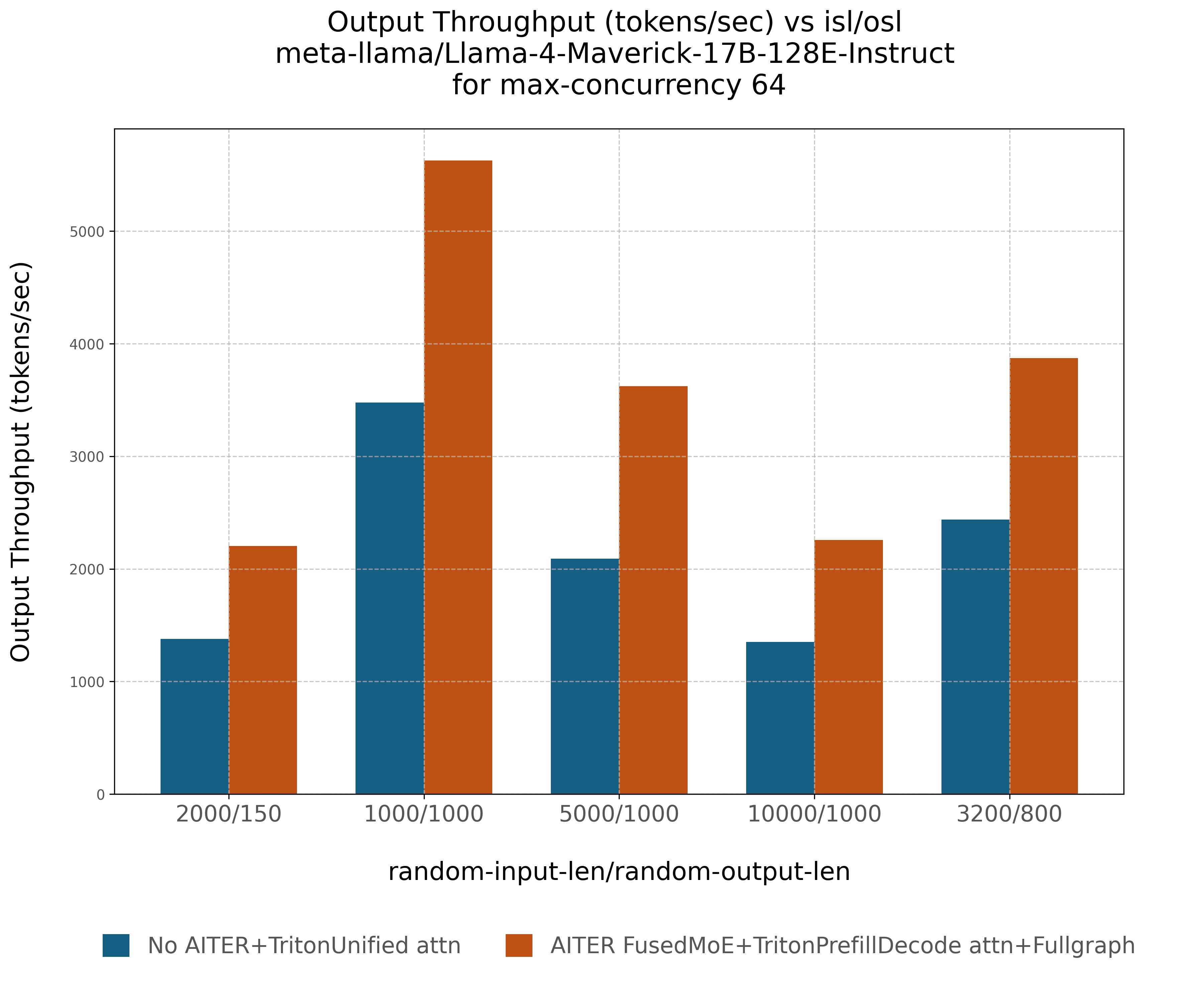
Figure 3. Performance comparison on model Llama4-Maverick-17B-128E-Instruct [7]#
Getting Started with vLLM 0.9.x on AMD ROCm#
Ready to experience these enhancements for the above mentioned optimized setup? Here’s how to get started:
Step 1: Pull the Docker image: The current recommended image incorporating these ROCm improvements is:
docker pull rocm/vllm-dev:nightly_0624_rc2_0624_rc2_20250620
Step 2: Launch the Docker container (example for MI-series):
docker run -it \
--network=host \
--group-add=video \
--ipc=host \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
--device /dev/kfd \
--device /dev/dri \
rocm/vllm-dev:nightly_0624_rc2_0624_rc2_20250620 \
bash
Step 3: Run the vLLM Server (inside Docker): To leverage the new V1 engine and AITER optimizations:
#!/bin/bash
MODEL=$1
VLLM_USE_V1=1 VLLM_ROCM_USE_AITER=1 VLLM_ROCM_USE_AITER_RMSNORM=0 VLLM_ROCM_USE_AITER_MHA=0 VLLM_V1_USE_PREFILL_DECODE_ATTENTION=1 \
vllm serve $MODEL \
--tensor-parallel-size 8 \
--max-model-len 32768 \
--max-num-seqs 1024 \
--max-num-batched-tokens 32768 \
--disable-log-requests \
--compilation-config '{"full_cuda_graph":true}' \
--trust-remote-code
You can pass the model location to the script to run the server with different Llama4 models.
Step 4: Benchmark Your Setup:
You can use the provided benchmark script to measure performance with different sequence lengths.
#!/bin/bash
MODEL=$1
ISL_OSL=("2000:150" "1000:1000" "5000:1000" "10000:1000" "3200:800")
for in_out in ${ISL_OSL[@]}
do
isl=$(echo $in_out | awk -F':' '{ print $1 }')
osl=$(echo $in_out | awk -F':' '{ print $2 }')
vllm bench serve \
--model $MODEL \
--dataset-name random \
--random-input-len $isl \
--random-output-len $osl \
--max-concurrency 64 \
--num-prompts 640 \
--ignore-eos \
--percentile_metrics ttft,tpot,itl,e2el
done
Step 5: Verify Model Accuracy (Optional)
End-to-end accuracy evaluation is conducted for every AITER integration
PR by running lm-eval of model on GSM8K dataset. The following are the
lm-eval scores of meta-llama/Llama-4-Maverick-17B-128E-Instruct when
AITER is enabled and disabled.
Configuration |
Filter Type |
Exact Match Value |
Stderr |
|---|---|---|---|
AITER Enabled |
flexible-extract |
0.9272 |
±0.0072 |
AITER Enabled |
strict-match |
0.9295 |
±0.0071 |
AITER Disabled (baseline) |
flexible-extract |
0.9280 |
±0.0071 |
AITER Disabled (baseline) |
strict-match |
0.9287 |
±0.0071 |
The commands to run the lm_eval are as follows:
python3 -m pip install lm_eval
With AITER:
#!/bin/bash
rm -rf /root/.cache/vllm
MODEL=$1
VLLM_USE_V1=1 \
VLLM_ROCM_USE_AITER=1 \
VLLM_ROCM_USE_AITER_MHA=0 \
VLLM_ROCM_USE_AITER_RMSNORM=0 \
VLLM_V1_USE_PREFILL_DECODE_ATTENTION=1 \
VLLM_WORKER_MULTIPROC_METHOD=spawn \
SAFETENSORS_FAST_GPU=1 \
lm_eval --model vllm --model_args pretrained=$MODEL,tensor_parallel_size=8,max_model_len=32768,max_num_batched_tokens=32768 --trust_remote_code --tasks gsm8k --num_fewshot 5 --batch_size auto
Without AITER:
#!/bin/bash
rm -rf /root/.cache/vllm
MODEL=$1
VLLM_USE_V1=1 \
VLLM_ROCM_USE_AITER=0 \
VLLM_WORKER_MULTIPROC_METHOD=spawn \
SAFETENSORS_FAST_GPU=1 \
lm_eval --model vllm --model_args pretrained=$MODEL,tensor_parallel_size=8,max_model_len=32768,max_num_batched_tokens=32768 --trust_remote_code --tasks gsm8k --num_fewshot 5 --batch_size auto
In-Depth Performance Analysis: AITER Configurations and Attention Backends in vLLM V1#
To get the best performance on AMD Instinct GPUs, it’s important to understand the key configuration options available in vLLM V1. In this section, we’ll break down the key environment variables and attention backends you can use to tune your setup.
Key Performance Toggles
1. Enabling AITER Kernel
You can enable or disable the entire suite of AITER-optimized kernels with a single flag.
Environment Variable: VLLM_ROCM_USE_AITER
0 (Default): AITER is disabled by default, meaning the standard kernels are used.
1: Enables AITER kernels, allowing access to AITER’s optimized compute paths.
2. Enabling AITER Fused MoE Kernel
For Mixture-of-Experts (MoE) models, you can specifically control the MoE kernel.
Environment Variable: VLLM_ROCM_USE_AITER_MOE
1 (Default): When AITER is enabled (VLLM_ROCM_USE_AITER=1), the fused MoE kernel is also turned on by default to accelerate MoE workloads.
0: Disables the AITER fused MoE kernel and falls back to the Triton implementation instead.
Choosing the Right Attention Backend in vLLM V1
In vLLM V1, users can choose from three distinct attention backends, each engineered to maximize performance based on model architecture and hardware configuration. These options are tightly integrated with AMD ROCm, enabling efficient utilization of MI300X GPUs.
Triton Unified Attention
This is the default if VLLM_ROCM_USE_AITER is not enabled. It is a single unified kernel that performs chunked prefill and decodes attention in Triton.
Triton Prefill-Decode Attention:
An alternative and hybrid attention backend optimized for MI300X, enabled with VLLM_V1_USE_PREFILL_DECODE_ATTENTION=1 (when VLLM_ROCM_USE_AITER_MHA=0 if AITER is enabled).
It has demonstrated superior performance on Llama 4 models compared with Triton Unified Attention.
Triton Prefill-Decode attention consists of the following kernels:
Component |
Kernel Name |
Details |
|---|---|---|
Prefill |
context_attention_fwd |
A Triton kernel optimized for chunked prefill. |
Primary Decode |
torch.ops._rocm_C.paged_attention |
Highly optimized for MI300X. Supports head sizes (64, 128), block sizes (16, 32), GQA ratios (1-16), and context up to 131k. Note: Sliding window support is currently unavailable. |
Fallback Decode |
kernel_paged_attention_2d |
An optimized Triton kernel used automatically if the model’s parameters don’t match the primary decode kernel’s requirements. |
AITER Multi-head Attention (MHA):
This is the default attention backend used when AITER is enabled. It is controlled by the VLLM_ROCM_USE_AITER_MHA environment variable.
1 (Default): Enabled automatically when VLLM_ROCM_USE_AITER=1, making it the active attention backend.
Important Limitation: In the rocm/vllm-dev:nightly_0624_rc2_0624_rc2_20250620 Docker image, this backend currently supports context lengths up to 8K.
Due to this limitation, we will explore this option in the future when support for longer contexts is available in future releases.
0: Disables the AITER MHA kernel. This is necessary if you want to use an alternative backend like Triton Prefill-Decode Attention.
Experimental Optimization: Full CUDA Graph Mode:
We’ve also evaluated the impact of torch.compile with the
full_cuda_graph feature enabled. This setting can boost performance
by reducing the CPU overhead but is currently experimental and
only compatible with Triton Prefill-Decode Attention . To enable this
feature, add the flag --compilation-config '{"full_cuda_graph":true}' to your vllm serve command.
Benchmarking Configurations:
To summarize, to analyze the performance progression, we compared output token throughput across four key configurations:
The table below summarizes the setup for each of our four test configurations.
Config ID |
Runs |
Environment variables + Engine flag |
|---|---|---|
1 |
Baseline – No AITER, using Triton Unified Attention Kernel |
|
2 |
AITER Fused-MoE + Triton Unified Attention Kernel |
VLLM_ROCM_USE_AITER=1 VLLM_ROCM_USE_AITER_MHA=0 |
3 |
AITER Fused-MoE + Triton Prefill-Decode Attention Kernel |
VLLM_ROCM_USE_AITER=1 VLLM_ROCM_USE_AITER_MHA=0 VLLM_V1_USE_PREFILL_DECODE_ATTENTION=1 |
4 |
AITER Fused-MoE + Triton Prefill-Decode Attention Kernel + Full CUDA Graph Mode |
VLLM_ROCM_USE_AITER=1 VLLM_ROCM_USE_AITER_MHA=0 VLLM_V1_USE_PREFILL_DECODE_ATTENTION=1 |
Note: In the current vLLM ROCm build, VLLM_USE_V1 is enabled by default. If using older builds, it must be explicitly set via environment variable.
Benchmark Results and Performance Highlights#
Benchmark results clearly show that Configuration 4 consistently delivers the highest throughput and best end-to-end performance. Figure 4 (below) illustrates how these four configurations perform across various input/output sequence lengths (ISL/OSL).
Figure 5 (below) zooms in on the best configuration, showing how its performance scales with increasing concurrency levels (from 8, 16 to 128) for a fixed ISL/OSL, demonstrating its robustness under heavy load.
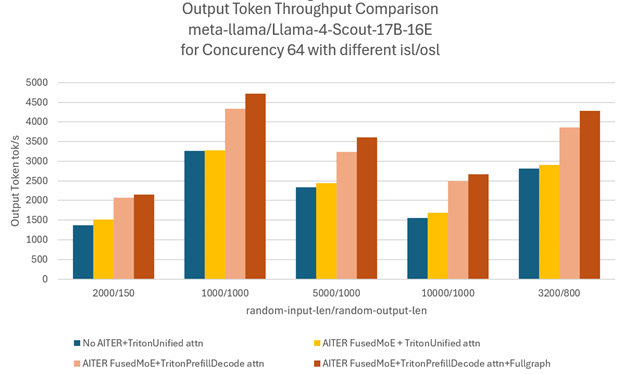
Figure 4. Performance comparison of different input sequence length (ISL)/output sequence length (OSL) of same concurrency with different configurations [7]#
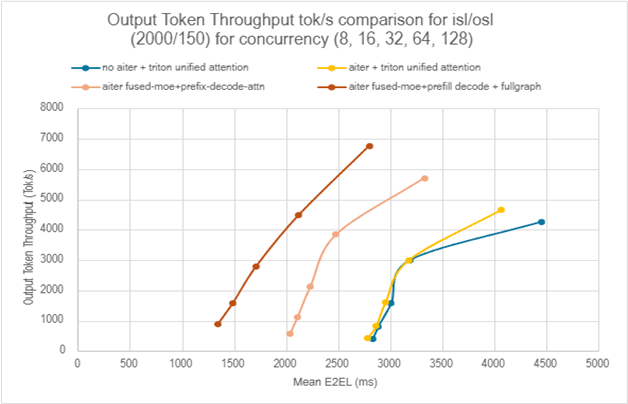
Figure 5. Performance comparison with different concurrency of the same ISL/OSL using different configuration [7]#
Summary#
The vLLM 0.9.x release marks a major milestone for LLM serving on AMD ROCm, delivering substantial performance gains, expanded model compatibility, and targeted optimizations for AMD Instinct GPUs. With vLLM 0.9.x, developers gain a powerful, production-ready toolkit built to harness the full capabilities of AMD hardware. Powered by the AITER framework and advanced kernel optimizations, this release unlocks next-level AI performance on ROCm—enabling significantly higher throughput, lower latency, and greater scalability. In this blog, we explored how vLLM 0.9.x leverages AITER integration, fused kernels, and attention backends to deliver measurable performance improvements across a range of LLM architectures. AMD remains committed to driving innovation in the open-source AI ecosystem and empowering developers to build and deploy at scale. We encourage the community to explore vLLM 0.9.x, and experience these improvements firsthand. Stay tuned for more feature improvements and optimizations in future releases.
Acknowledgements#
We would like to thank the members of the broader vLLM team and the ROCm AITER team for their contributions to the development and optimization efforts, which have helped us continue pushing the boundaries of what’s possible with LLMs on ROCm software.
Endnotes#
[1] PR#14968
[2] PR#17523
[3] PR#17955
[4] PR#18271
[5]PR #17530,
[6]PR #17535
[7] Configuration details
On average, a system configured with an AMD Instinct™ MI300X GPU running tests done by AMD on 06/24/2025, results may vary based on configuration, usage, software version, and optimizations.
Software: Docker image: rocm/vllm-dev:nightly_0624_rc2_0624_rc2_20250620
Base image: BASE_IMAGE: rocm/dev-ubuntu-22.04:6.4.1-complete
HIPBLAS_COMMON_BRANCH: 9b80ba8e
HIPBLASLT_BRANCH: aa0bda7b
TRITON_BRANCH: e5be006
TRITON_REPO: https://github.com/triton-lang/triton.git
PYTORCH_BRANCH: f717b2af
PYTORCH_VISION_BRANCH: v0.21.0
PYTORCH_REPO: https://github.com/ROCm/pytorch.git
PYTORCH_VISION_REPO: https://github.com/pytorch/vision.git
FA_BRANCH: 1a7f4dfa
AITER_BRANCH: 626d8127
AITER_REPO: https://github.com/ROCm/aiter.git
SYSTEM CONFIGURATION: AMD Instinct ™ MI300X platform System Model: Supermicro AS-8125GS-TNMR2 CPU: 2x AMD EPYC 9654 96-Core Processor NUMA: 2 NUMA node per socket. NUMA auto-balancing disabled/ Memory: 2304 GiB (24 DIMMs x 96 GiB Micron Technology MTC40F204WS1RC48BB1 DDR5 4800 MT/s) Disk: 16,092 GiB (4x SAMSUNG MZQL23T8HCLS-00A07 3576 GiB, 2x SAMSUNG MZ1L2960HCJR-00A07 894 GiB) GPU: 8x AMD Instinct MI300X 192GB HBM3 750W Host OS: Ubuntu 22.04.5 System BIOS: 3.2 System Bios Vendor: American Megatrends International, LLC. Host GPU Driver: (amdgpu version): ROCm 6.3.2
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.