Practical, Fault‑Robust Distributed Inference for DeepSeek on AMD MI300X#

As large scale LLM inference moves beyond a single server, engineering teams face a familiar trifecta of challenges: performance, fault isolation, and operational efficiency. DeepSeek‑V3/R1’s high‑sparsity Mixture‑of‑Experts (MoE) architecture can deliver excellent throughput, but only when computation, memory, and communication are orchestrated with care—especially across multiple nodes [1].
Recent production case studies [2] emphasize a few lessons that consistently hold up at scale: keep Prefill and Decode paths separated, bound the failure blast radius by using smaller Expert Parallel (EP) groups and avoid unnecessary cross‑node traffic. Rack‑level fabrics such as the GB200 NVL72 showcase [3] impressive raw bandwidth, but wide EP spanning many GPUs increase the fault radius and the cost of recovery when any single GPU, link, or switch is unstable. In practice, smaller EP groupings provide safer, more reliable service with better aggregate utilization. In this blog, you will learn how a small-radius EP design with Prefill–Decode disaggregation enables scalable, fault-isolated LLM inference on AMD Instinct™ MI300X clusters.
Architecture Overview: Small‑Radius EP with Prefill–Decode Disaggregation#
We implement a replicated instance pattern built from four AMD Instinct™ MI300X nodes per instance using a 2P2D layout—two nodes for Prefill and two for Decode (see Figure 1, below). Each instance is fully RDMA‑connected for low‑latency KV cache transfer and can be auto scaled horizontally to match load. If any node fails, only that instance is affected; other instances continue serving, traffic is rerouted automatically, and a replacement instance can be brought up quickly. This design minimizes the failure domain while preserving high throughput.

Figure 1. Multi‑instance distributed inference with a proxy/router fan‑out. Each instance uses a 2P2D (Prefill/Decode) layout across four nodes and a full‑mesh RDMA fabric.#
Results at Scale#
Using this architecture and AMD‑optimized libraries (e.g., AITER and MoRI), we scale across 32 Instinct™ MI300X GPUs and measure the following on 2,000‑token inputs:
Per-node throughput: 32.3k input tokens/s and 12.4k output tokens/s.
End-to-end gains: EP16 achieved up to 1.3× higher output throughput versus the EP8 baseline under business Service Level Objective (SLO) constraints, while maintaining fault isolation at the instance level. For offline mode (no serving SLA), the solution can achieve an average of 2× higher throughput than TP8.
These results reflect best practices for deploying DeepSeek on AMD Instinct™ MI300X clusters: keep EP groups small to reduce communication overhead and fault radius, separate Prefill and Decode for tighter SLO control, and use a horizontal fleet of instances to absorb failures and workload volatility.
What You’ll Learn#
How AITER‑based FP8 GEMM, MLA and FusedMoE optimizations unlock potential throughput headroom on Instinct™ MI300X.
How MoRI‑IO cleanly separates Prefill and Decode paths and sustains peak intra‑/inter‑node performance.
How MoRI‑EP routes experts efficiently across nodes without widening the fault domain.
Compared to the official DeepSeek Chat API, a well‑tuned on‑prem deployment of this design can materially lower serving costs. ($1.0 per 1M tokens, achieving around 55% cost savings compared to the official DeepSeek-R1 Chat API) If your objective is to meet strict SLOs while controlling Total Cost of Ownership (TCO), the blueprint in this post provides concrete steps to build, tune, and benchmark at production speed.
ROCm Optimization Library#
AITER#
AITER is AMD centralized repository supporting a variety of high-performance AI operators for workload acceleration. It serves as a unified hub for customer operator-level requests, addressing diverse needs. Developers can focus on operators, allowing customers to integrate this operator collection into their own private, public, or hybrid framework.
AITER empowers most key operators of DeepSeek-V3/R1. Through vLLM custom op registration, AITER provides Triton/CK/ASM type GEMM or MoE kernels. For our distributed end-to-end solution, we integrated FP8 MLA, per-token activation per-channel weight quantization, preshuffle AITER FP8 GEMM, fused rope cache concat, fused shared expert, etc to maximize the throughput.
MoRI#
MORI (Modular RDMA Interface) is a bottom-up, modular, and composable framework for building high-performance communication applications with a strong focus on RDMA + GPU integration. Inspired by the role of MLIR in compiler infrastructure, MORI provides reusable and extensible building blocks that make it easier for developers to adopt advanced techniques such as IBGDA (Infiniband GPUDirect Async) and GDS (GPUDirect Storage).
MORI includes a suite of optimized libraries—MORI-EP (MoE dispatch and combine kernels) to support high-efficiency expert parallelism across intra- and inter-node communication, and MORI-IO (P2P communication for KVCache transfer) to saturate the interconnect device bandwidth.
Key Optimization Details#
Parallelism Methodology#
Due to DeepSeek’s high sparsity MoE architecture, a tensor parallelism- only methodology faces new challenges at scale. To address these scaling limits, vLLM has made three major changes in MoE execution. The first is a shift from tensor parallel attention to data parallel attention paired with expert parallel MoEs (see Figure 2, below). The second is the introduction of specialized communication patterns for expert parallelism. The third is the addition of optimizations such as expert parallel load balancing and overlapping communication with computation.
During DeepSeek inference, global input batches are injected into each GPU separately. The MLA part will be executed independently rather than being sharded into different GPUs. After executing router layers of MoE layers, a dispatch operation sends each token according to the decision made by the router. And after grouped MLP computations, a combine operation aggregates and restores the outputs. This new paradigm provides a better ability to saturate the computation flops while running decoding.
The primary advantage is that dispatch and combine are sparse operations. Each token involves only the GPUs associated with its top-k experts, greatly improving scalability across multiple nodes.
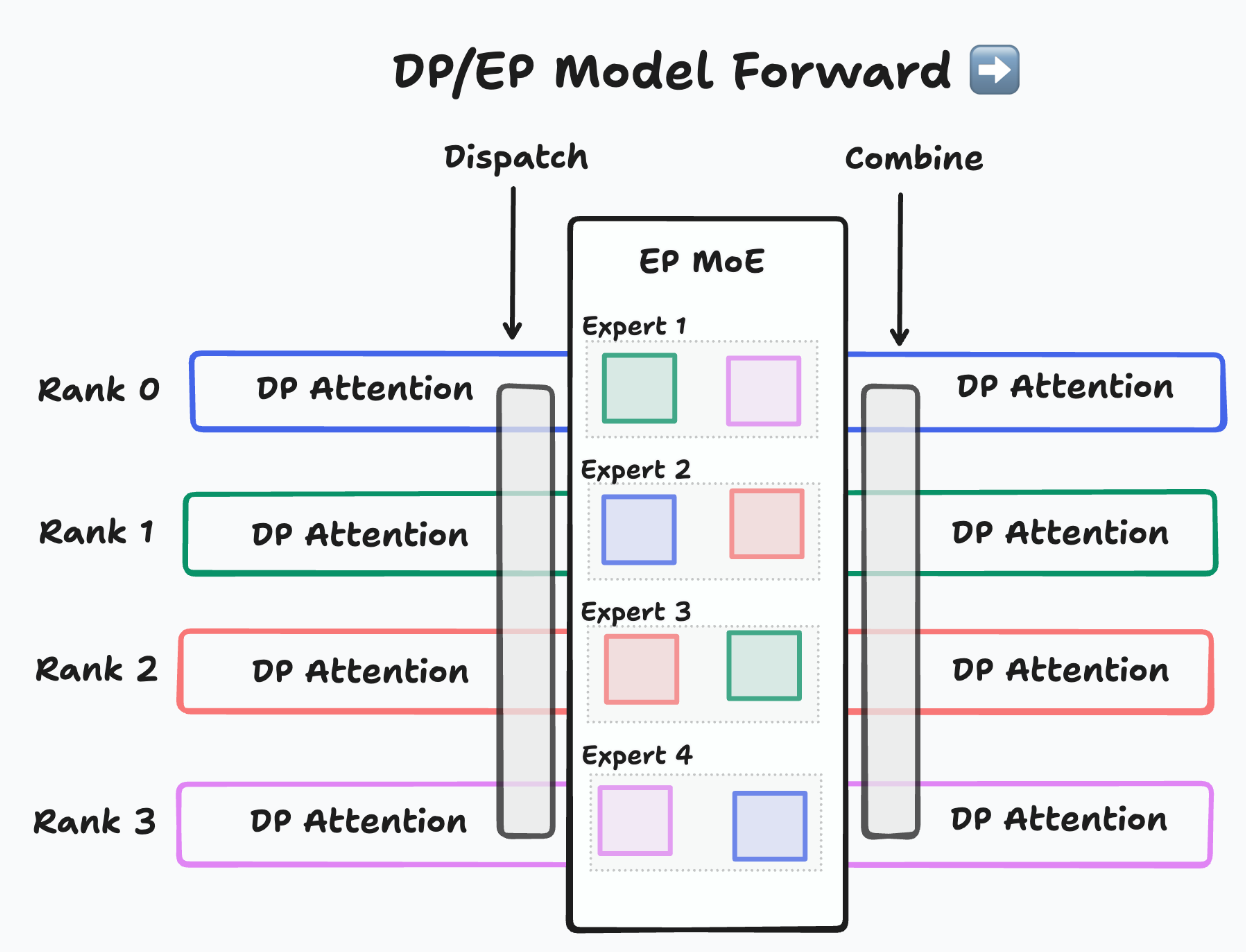
Figure 2. How DP Attention co-work with EP MoE [4]#
Computation Kernel Optimization#
AITER MLA with FP8 KV cache#
We observe tremendous performance gains by introducing AITER-related operators. AITER MLA for decode is one of the greatest optimizations, providing an impressive performance boost of up to 17x, dramatically enhancing decoding efficiency. However, this kernel does not support FP8 KV cache in vLLM upstream. We see the potential benefit of integrating MLA decode performance for DeepSeek, Kimi-k2, etc. It can also bring higher throughput to KV transfer for PD disaggregation.
PTPC FP8 Preshuffle GEMM#
DeepSeek-V3/R1 introduced a block-wise quantization scheme while per-token activation per-channel weights provide higher computational efficiency without sacrificing accuracy on the Instinct™ MI300X platform. Additionally, AITER introduces a novel bpreshuffle ckGEMM. To enable this optimization, we preshuffle the weights after loading the model weights.
AITER Sampling#
We integrate the optimized AITER sampling operator, replacing the default PyTorch native implementation. We are able to observe a significant improvement in the performance of top-k/top-p sampling on AMD Instinct™ MI300X GPU. The AITER sampling operator provides a substantial performance uplift. On average, it achieves an ~1.6x increase in total throughput and a ~50% reduction in Time To First Token (TTFT).
Communication Kernel Design and Optimization#
High Performance KV Cache Transfer Engine#
MORI-IO is a high-performance peer-to-peer (P2P) communication library purpose-built for KVCache transfer in LLM PD disaggregation inference. By leveraging GPU Direct RDMA (GDR) and aggressively minimizing the software’s critical path, MORI-IO significantly boosts KVCache transfer efficiency, eliminating it as a performance bottleneck in disaggregated inference. Even under severe KVCache block fragmentation, MORI-IO sustains high throughput through advanced techniques such as batch transfer, buffer merging, multi-QP transfer, and multi-threaded transfer, etc.
By integrating MoRI-IO into vLLM, we have designed a high performance KV connector based on the MoRI-IO library, which minimizes the KV transfer overhead by leveraging layer-wise KVCache transfer (PUSH mode), zero-copy, and non-blocking CPU & GPU operations. Details are illustrated in Figure 3:
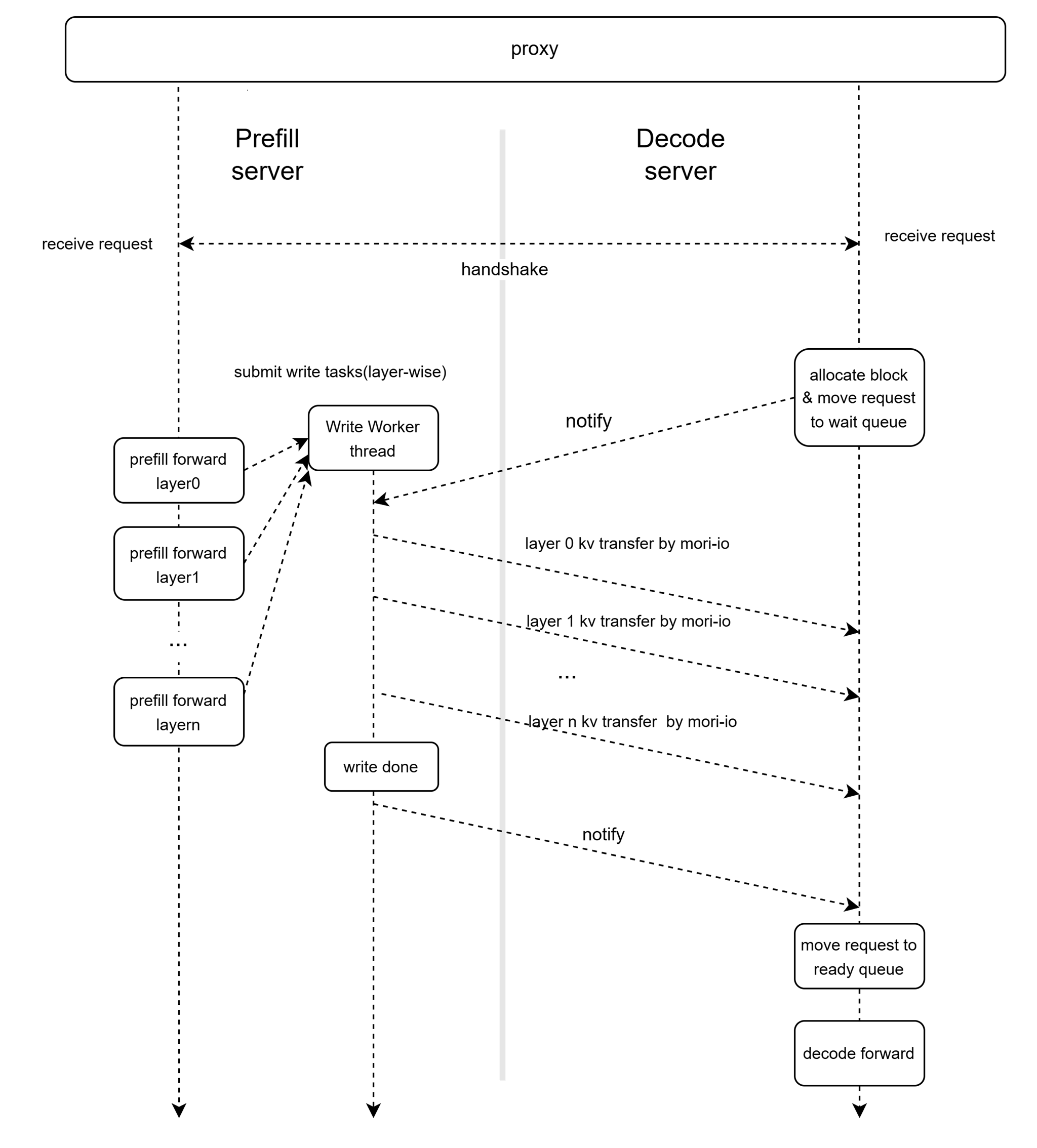
Figure 3. MoRI-IO KV-Connector implementation#
Token dispatch & combine through MoRI-EP#
MORI-EP is AMD’s native communication library designed for Mixture-of-Experts (MoE) training and inference. Built on MORI-Core’s InfiniBand GPU Direct Asynchronous (IBGDA) implementation and enhanced with optimizations such as network-domain forwarding, runtime token tracing, and aggressive network pipelining, MORI-EP achieves both high bandwidth and low latency for expert parallelism. It is co-designed with AITER FusedMoE to expand the optimization space and deliver even higher performance in MoE inference.
We have registered MoRI-EP as a novel all-to-all communication backend. In contrast to the naive all-to-all backend in vLLM, which relies on RCCL APIs, MoRI-EP delivers higher performance and lower latency through the following advantages:
Higher Bandwidth: MoRI-EP achieves high bandwidth even with relatively small message sizes.
Tailored for MoE Architecture: Designed specifically for expert parallelism, MoRI-EP uses tensor layouts optimized for AITER fused MoE kernels.
CUDA Graph Support: This feature is critical for performance, particularly during the decoding phase. MoRI-EP implementation now supports HIP graph mode.
GPU-Initiated Communication: By enabling GPU-initiated operations, MoRI-EP reduces latency—especially beneficial for meeting strict service-level objectives (SLOs).
Performance Result#
We conducted the experiments on AMD Instinct™ MI300X cluster (for more details about the setup we used, please see the Endnotes section). We evaluate the end-to-end performance based on different configurations of our distributed inference framework. For prefill, we tested the 2,000-length prompt input scenario which shows that our end-to-end distributed solution achieved 32.3k tokens per second per node (see Figure 4, below).
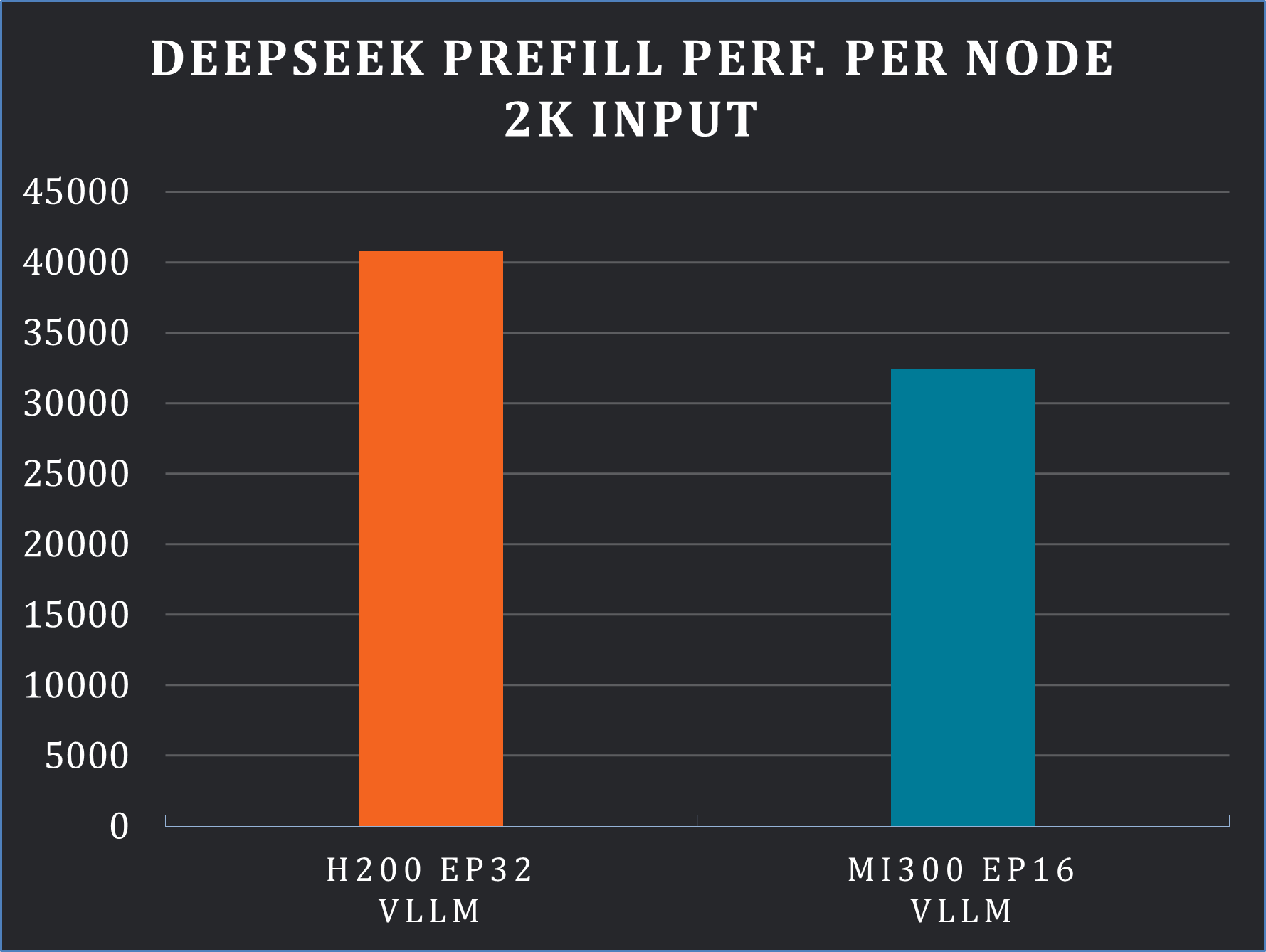
Figure 4. Prefill performance evaluation [5]#
For decode, we also tested the 2,000-length prompt input and 100 length output which shows that our end-to-end distributed solution achieved 12.4k tokens per second per node. Compared to the TP8 scenario, the EP16 solution delivered 1.6× higher output tokens, demonstrating great scaling capability (see Figure 5, below).
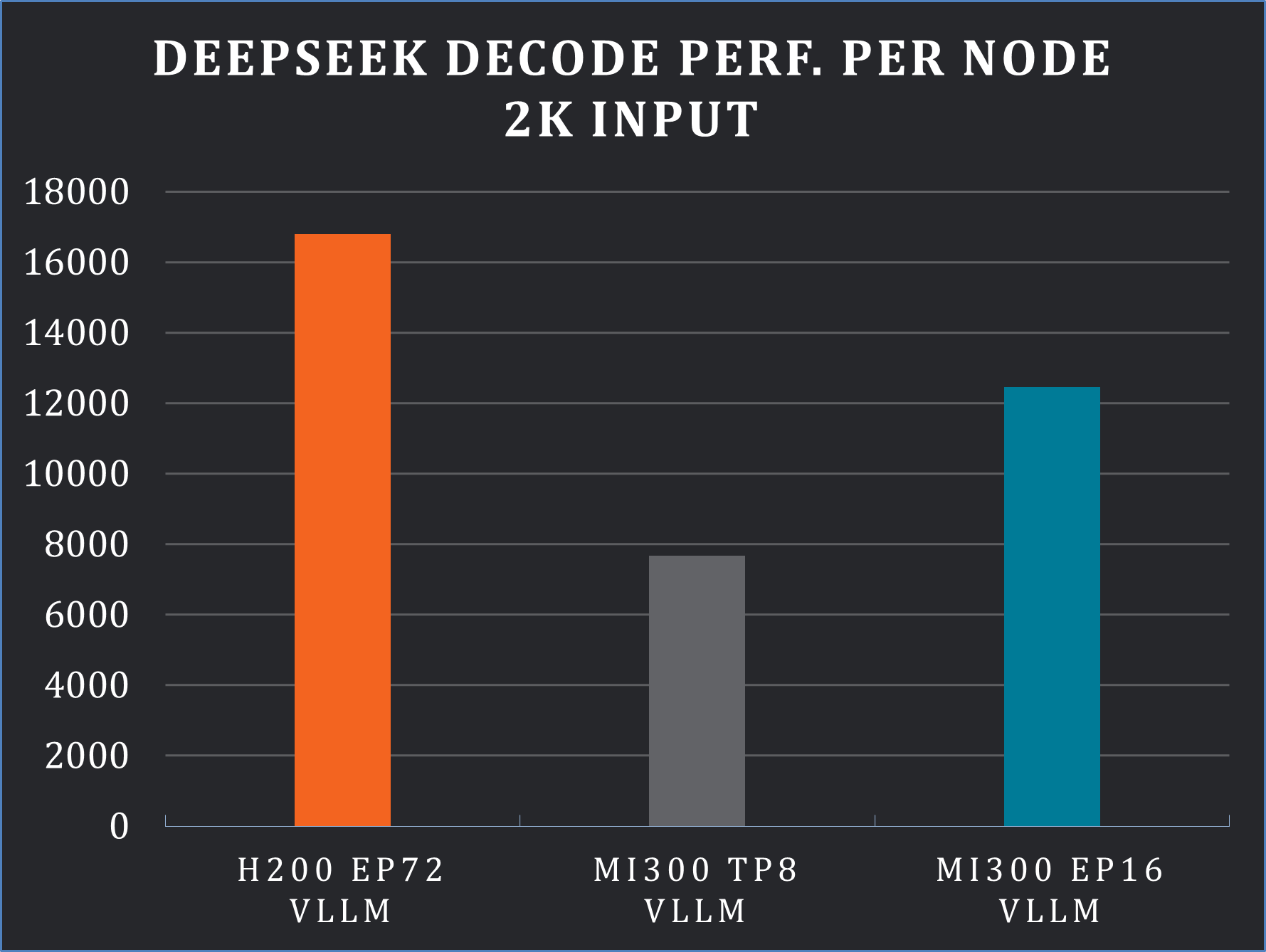
Figure 5. Decode performance evaluation [5]#
As illustrated in Figure 6, EP16 delivers up to 1.3× higher output throughput compared to the EP8 baseline under business SLO constraints, while preserving instance-level fault isolation. In offline mode, where no serving SLA is imposed, the configuration achieves an average of 2× throughput improvement over TP8 (see Figure 6, below).

Figure 6. Decode throughput#
With essential features such as dual-batches overlapping still being developed, the AMD Instinct™ MI300X platform holds strong potential for further performance improvements. Once these enhancements are in place, we expect the current performance gap to be effectively eliminated.
Future Work#
Our future efforts will focus on enhancing parallel efficiency and reducing communication–computation latency in large-scale MoE inference. In particular, we plan to explore dual-batch overlapping and adaptive expert load balancing to further improve throughput and utilization.
Dual Batch Overlap#
The core motivation behind the Dual Batch Overlap (DBO) system inspired by DeepSeek DualPipe [6] in vLLM is to overlap the sparse all-to-all communication in the MoE layer with the surrounding computation. This system currently only targets DP+EP deployments.
The Dual Batch Overlap system works by splitting the batch in the model runner, creating two worker threads, and then running the model on each of these worker threads. Some studies claim significant performance gains through either overlapping dual batches or certain operations within a single batch.
Expert Parallel Load Balancer#
When utilizing Expert Parallelism (EP), distinct experts are assigned to different GPUs alongside their respective tokens. Maintaining balanced loads across GPUs is critical, as the computational demand of individual experts can fluctuate based on the current workload (i.e., token distribution). To address this, vLLM incorporates an Expert Parallel Load Balancer (EPLB) first introduced by DeepSeek EPLB [7] project, which redistributes expert mappings across EP ranks to equalize the load across all experts.
With the growing scale of expert parallelism, the imbalance in token distribution becomes more pronounced, potentially degrading the overall inference performance. Hence, resolving this issue is crucial for our next step in performance optimization.
Summary#
This post demonstrates how a small-radius Expert Parallel (EP) design with Prefill–Decode disaggregation enables scalable, fault-isolated LLM inference on AMD Instinct™ MI300X clusters. Each 2P2D instance (two Prefill + two Decode nodes) confines failures while sustaining high throughput and efficient scaling. At 32 GPUs, DeepSeek achieved up to 1.3× higher throughput than EP8 under business SLOs and 2× improvement in offline mode.
AMD optimized components (e.g., AITER and MoRI) deliver strong performance and reliability. A well-tuned on-prem deployment following this blueprint can cut serving costs to $1.0 per 1M tokens, saving about 55% compared to the official DeepSeek-R1 Chat API.
As upcoming features like dual batches overlapping and continued ROCm enhancements mature, this architecture provides a proven foundation for even greater efficiency. Together, these innovations define the best-practice blueprint for large-scale DeepSeek deployment on AMD platforms.
References#
Endnotes#
[1] AMD Instinct ™ MI300X GPU platform
System Model: Supermicro AS-8125GS-TNMR2 CPU: 2x AMD EPYC™ 9654 96-Core Processor NUMA: 2 NUMA nodes per socket. NUMA auto-balancing disabled/ Memory: 2304 GiB (24 DIMMs x 96 GiB Micron Technology MTC40F204WS1RC48BB1 DDR5 4800 MT/s) Disk: 16,092 GiB (4x SAMSUNG MZQL23T8HCLS-00A07 3576 GiB, 2x SAMSUNG MZ1L2960HCJR-00A07 894 GiB) GPU: 8x AMD Instinct™ MI300X 192GB HBM3 750W Host OS: Ubuntu 22.04.4 System BIOS: 3.2 System BIOS Vendor: American Megatrends International, LLC. Host GPU Driver (amdgpu version): ROCm 6.3.1
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.