AI - Applications & Models - Page 9#
Medical Imaging on MI300X: Optimized SwinUNETR for Tumor Detection
Learn how to setup, run and optimize SwinUNETR on AMD MI300X GPUs for fast medical imaging 3D segmentation of tumors using fast, large ROIs.

Announcing MONAI 1.0.0 for AMD ROCm: Breakthrough AI Acceleration for Medical Imaging Models on AMD Instinct™ GPUs
Learn how to use Medical Open Network for Artificial Intelligence (MONAI) 1.0 on ROCm, with examples and demonstrations.

Optimizing FP4 Mixed-Precision Inference with Petit on AMD Instinct MI250 and MI300 GPUs: A Developer’s Perspective
Learn how FP4 mixed-precision on AMD GPUs boosts inference speed and integrates seamlessly with SGLang.

From Ingestion to Inference: RAG Pipelines on AMD GPUs
Build a RAG enhanced GenAI application that improves the quality of model responses by incorporating data that is missing in the model training data.

Enabling FlashInfer on ROCm for Accelerated LLM Serving
FlashInfer is an open-source library for accelerating LLM serving that is now supported by ROCm.

Coding Agents on AMD GPUs: Fast LLM Pipelines for Developers
Accelerate AI-assisted coding with agentic workflows on AMD GPUs. Deploy DeepSeek-V3.1 via SGLang, vLLM, or llama.cpp to power fast, scalable coding agents

Day-0 Support for the SGLang-Native RL Framework - slime on AMD Instinct™ GPUs
Learn how to deploy slime on AMD GPUs for high-performance RL training with ROCm optimization
Accelerating Audio-Driven Video Generation: WAN2.2-S2V on AMD ROCm
This blog will highlight AMD ROCm’s ability to power next-generation audio-to-video models with simple, reproducible workflows.

A Simple Design for Serving Video Generation Models with Distributed Inference
Minimalist FastAPI + Redis + Torchrun design for serving video generation models with distributed inference.

Optimizing Drug Discovery Tools on AMD MI300X Part 1: Molecular Design with REINVENT
Learn how to set up, run, and optimize REINVENT4, a molecular design tool, on AMD MI300X GPUs for faster drug discovery workflows
Running SOTA AI-based Weather Forecasting models on AMD Instinct
We look at a few State of the Art AI models in weather forecasting, and demonstrate how to run them on AMD Instinct MI300X in a step-by-step fashion.
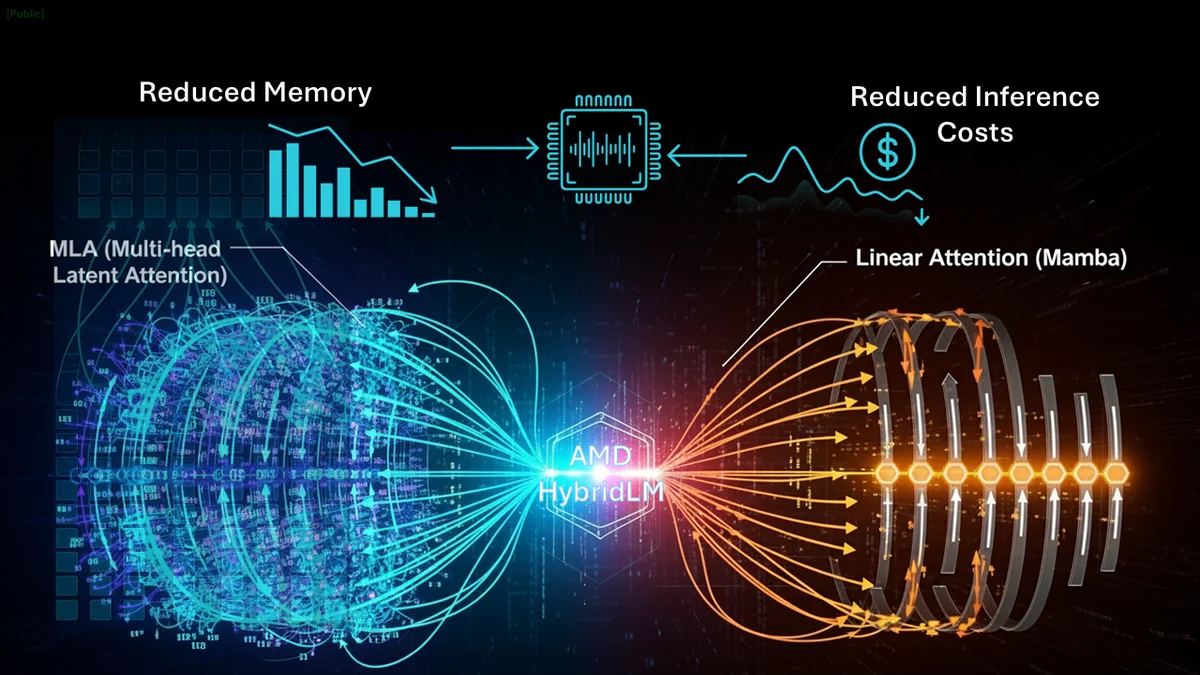
AMD-HybridLM: Towards Extremely Efficient Hybrid Language Models
Explore AMD-HybridLM’s architecture and see how hybridization redefines LLM efficiency and performance without requiring retraining from scratch