Optimizing LLM Workloads: AMD Instinct MI355X GPUs Drive Competitive Performance#

AI training workloads are pushing the limits of modern GPU architectures. With the release of AMD ROCm™ 7.0 software, AMD is raising the bar for high-performance training by delivering optimized support for LLM workloads across the JAX and PyTorch frameworks. The latest v25.9 Training Dockers demonstrate exceptional scaling efficiency for both single-node and multi-node setups, empowering researchers and developers to push model sizes and complexity further than ever.
By integrating Primus, a unified and flexible LLM training framework, the PyTorch training docker streamlines LLM development on AMD Instinct™ GPUs. Primus now supports both TorchTitan and Megatron-LM backends, while Primus-Turbo accelerates Transformer models, further boosting training throughput on AMD Instinct™ MI355X GPUs. Try Primus-Repo here: Primus-Repo
The AMD PyTorch and Megatron-LM training docker v25.9 release is built with Primus —a unified and flexible LLM training framework designed to streamline training. Primus simplifies LLM development on AMD Instinct GPUs through a modular, reproducible configuration paradigm. With this release, Primus now supports both PyTorch TorchTitan and PyTorch Megatron-LM backends, providing developers with a powerful and scalable solution for next-generation models. Primus-Turbo, a library for accelerating transformer models on AMD GPUs, is also introduced in the v25.9 release of the training docker, delivering further optimized training performance.
This blog highlights benchmark results showcasing AMD Instinct MI355X GPUs’ performance advantages across popular dense and Mixture-of-Experts (MoE) models, emphasizing token throughput (tokens/gpu/s) as a critical metric for large-scale LLM training efficiency.
Single-Node Performance with Primus#
We evaluated multiple models on ROCm 7.0 PyTorch Training Docker v25.9. Across dense LLMs like Llama3 and MoE models such as Mixtral 8x 7B, AMD Instinct MI355X GPUs consistently delivered higher throughput.
Key Highlights:
Llama3 70B FP8: AMD Instinct MI355X GPU matches baseline performance at 1.0X in Primus-TorchTitan v25.9
Llama3 70B BF16: AMD Instinct MI355X GPU achieves 1.16X in Primus-TorchTitan v25.9
Llama3 8B FP8: AMD Instinct MI355X GPU delivers 1.08X in Primus-Megatron v25.9
Llama3 8B BF16: AMD Instinct MI355X GPU shows a 1.02X in Primus-Megatron v25.9
Mixtral 8X7B FP16: AMD Instinct MI355X GPU achieves 1.15X in Primus-Megatron v25.9
MI355X vs. B200 performance ratio, as shown in Figure 1 below.

Figure 1: PyTorch Single-Node Performance#
These results underscore AMD Instinct MI355X GPU’s ability to handle both small and large models efficiently within a single node.
Single-Node Performance in JAX MaxText#
JAX has rapidly gained popularity in the AI research and development community for its composability, high-performance numerical computing and ease of scaling across accelerators. Its functional programming paradigm and integration with XLA make it a preferred choice for cutting-edge LLM and scientific workloads.
The ROCm MaxText Docker image provides a prebuilt environment for training on AMD Instinct MI355X GPUs, including JAX, XLA, ROCm libraries, and MaxText utilities. This streamlined setup enables developers to leverage JAX’s flexibility and performance on AMD hardware without complex configuration. We evaluated three models on ROCm 7.0 JAX MaxText Training Docker v25.9. Results show MI355X consistently outperforms the B200 JAX MaxText 25.08 in dense models and achieving near-parity on MoE workloads.
Key Highlights:
Llama3.1 70B FP8: 1.11X improvement on AMD Instinct MI355X GPU
Llama3.1 8B FP8: 1.07X improvement on AMD Instinct MI355X GPU
Mixtral 8×7B FP16: 1.00X on AMD Instinct MI355X GPU
MI355X vs. B200 performance ratio as you can see in figure 2 below
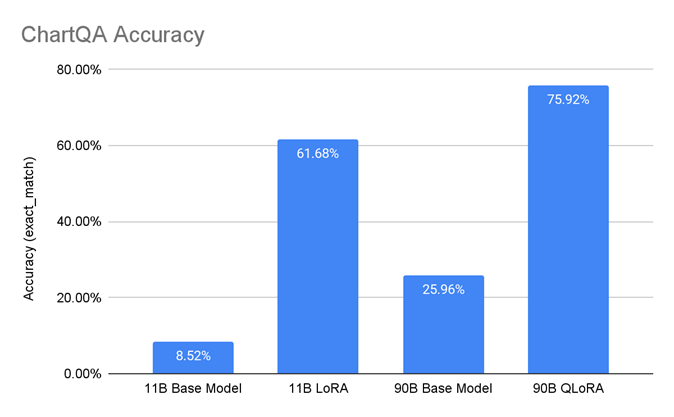
Figure 2: Jax MaxText Single-Node Performance#
AMD Instinct MI355X GPUs demonstrate strong throughput while enabling JAX’s flexibility and accelerator scaling, making it an excellent choice for cutting-edge research workloads.
Multi-Node Scaling#
For distributed training, MI355X demonstrates strong scalability across multiple nodes, maintaining competitive performance against B200.
Key Highlights:
Mixtral 8x22B BF16: 1.14X advantage in 4-node Primus-Megatron
Llama3 70B FP8: Maintains parity at 1.01X in 4-node Primus-Megatron
Llama3.1 405B FP8: Competitive at 0.96X in 8-node Primus-Megatron
MI355X vs. B200 performance ratio as you can see in figure 3 below
Figure 3: Pytorch Multi-Node Performance#
These results demonstrate that AMD Instinct MI355X GPUs not only perform well on single nodes but also scale effectively for distributed training scenarios.
Summary#
AMD ROCm 7.0 software, paired with AMD Instinct MI355X GPUs, establishes a new standard for AI training performance. Throughout this blog, we demonstrated how MI355X delivers outstanding throughput, flexibility, and scalability for large language models on both JAX and PyTorch frameworks. With seamless integration of Primus and JAX MaxText, developers can efficiently train next-generation models without compromise.
Whether you are optimizing for single-node speed or scaling across multiple nodes, ROCm 7.0 provides a robust foundation for pushing the boundaries of AI workloads. MI355X empowers researchers and engineers to tackle today’s most demanding models with confidence and efficiency. We encourage you to experience these advancements firsthand—download the v25.9 Training Docker and unlock new possibilities for your AI projects.
Try it yourself: Download the v25.9 Training Docker today to experience optimized LLM training performance on AMD GPUs and see firsthand how ROCm 7.0 software can accelerate your AI workloads.
Endnotes#
MI350-65 - Based on testing by AMD Performance Labs on Oct 27, 2025, Llama3 8B pretraining throughput (tokens/second/GPU) was tested with FP8 & BF16 precision, a maximum sequence length of 8192 tokens using a per-GPU batch size of 8. Server manufacturers may vary configurations, yielding different results. Performance may vary based on use of latest drivers and optimizations. AMD system configuration: Dual Core AMD EPYC 9575F 64-core processor , 8x AMD Instinct MI355X GPU platform, System BIOS 1.4a,4 NUMA nodes per socket, Host OS Ubuntu 22.04.5 LTS with Linux kernel 5.15.160-generic, Host GPU driver ROCm 7.0.1 + amdgpu 6.14.12 . PyTorch 2.9.0, AMD ROCm 7.0.1 software
MI350-66 - Based on testing by AMD Performance Labs on Oct 27, 2025, with the Mixtral 8x7B model, measuring the pretraining throughput (tokens/second/GPU) on an AMD Instinct MI355X 8x GPU platform and AMD ROCm software, running “Primus Megatron-LM,”. Server manufacturers may vary configurations, yielding different results. Performance may vary based on use of latest drivers and optimizations. AMD system configuration: Dual Core AMD EPYC 9575F 64-core processor, AMD Instinct 8x GPU MI355X platform, System BIOS 1.4a, 4 NUMA nodes per socket, Host OS Ubuntu 22.04.5 LTS with Linux kernel 5.15.160-generic, Host GPU driver ROCm 7.0.1 + amdgpu 6.14.12, PyTorch deep learning framework 2.9.0, and AMD ROCm 7.0.1 software.
MI350-67 - Based on testing by AMD Performance Labs on Oct 27, 2025, Llama3 70B pretraining throughput (tokens/second/GPU) was tested with FP8 & BF16 precision, a maximum sequence length of 8192 tokens using a per-GPU batch size of 8. Server manufacturers may vary configurations, yielding different results. Performance may vary based on use of latest drivers and optimizations. AMD system configuration: Dual Core AMD EPYC 9575F 64-core processor , 8x AMD Instinct MI355X GPU platform, System BIOS 1.4a,4 NUMA nodes per socket, Host OS Ubuntu 22.04.5 LTS with Linux kernel 5.15.160-generic, Host GPU driver ROCm 7.0.1 + amdgpu 6.14.12 . PyTorch 2.9.0, AMD ROCm 7.0.1 software
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.