An Introduction to Primus-Turbo: A Library for Accelerating Transformer Models on AMD GPUs#

With the rapid growth of large-scale models, acceleration libraries are facing higher demands: they must deliver exceptional performance, offer comprehensive functionality, and remain easy to use. To meet these needs, we introduce Primus-Turbo — part of the Primus product family (see our previous blog for background). Primus-Turbo is designed around three core principles: performance, completeness, and ease of use. It supports training, inference, and a wide range of application scenarios, providing developers with a solid foundation to efficiently build and optimize large models on the ROCm platform. See Figure 1 below for a comprehensive stack coverage of Primus-Turbo.
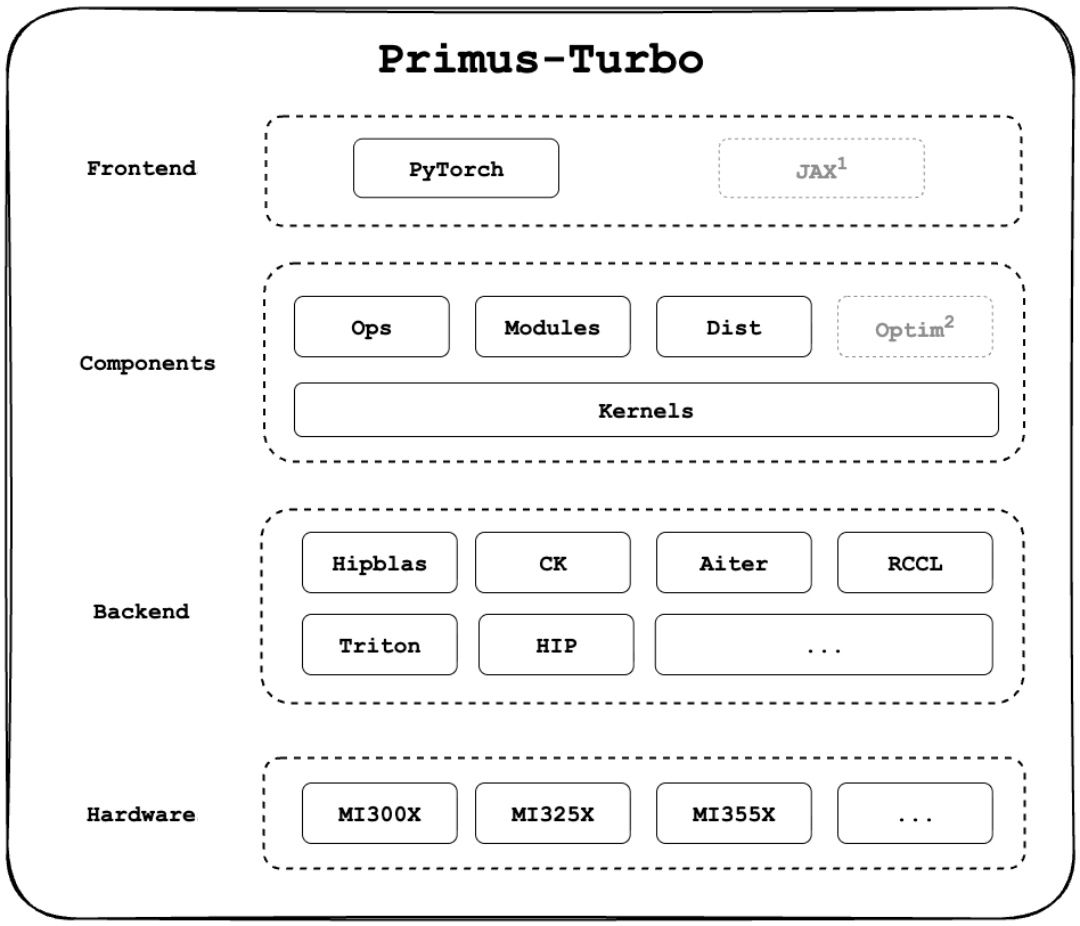
Figure 1. Primus-Turbo (note that JAX and Optim support are planned but not yet available).#
Primus-Turbo Performance#
The first design principle of Primus-Turbo is high performance. To fully unleash the computational power of AMD GPUs, we have applied deep optimizations while integrating existing high-performance libraries from the ROCm ecosystem, including AITER, Composable Kernel (CK), hipBLASLt, etc. Building on this foundation, Primus-Turbo provides unified and extended implementations of various operators, enabling developers to achieve efficient and reliable performance directly along the critical paths of training and inference. To demonstrate the advantages of Turbo, we conducted comparative experiments on Megatron and TorchTitan across multiple models. The results show that integrating Turbo consistently improves both training performance and memory efficiency.
Test Environment#
Component |
Configuration |
|---|---|
GPU |
MI300X |
Docker |
rocm/megatron-lm:v25.8_py310 |
ROCm |
6.4 |
Primus |
v0.2.0 |
Primus-Turbo |
v0.1.0 |
TorchTitan : Baseline vs Turbo#
In Figure 2 we detail the performance comparison of TorchTitan with the baseline versus Primus Turbo (TFLOPS and memory consumption).
Llama-3.1-8B
Configs: seq-length 8192, micro batch size 4, DP=8, enabled torch.compile, running on 8xMI300X.
Turbo optimizations: GQA-Attention.
DeepSeek-V2-Lite
Configs: seq-length 4096, micro batch size 8, EP=1, DP=8, running on 8xMI300X.
Turbo optimizations: MLA-Attention and Grouped GEMM.
Note: Integration of DeepSeek-V2-Lite with TorchTitan and Primus-Turbo is still in progress; the code will be released soon. The results we share here are from the integration-testing stage and are for reference.
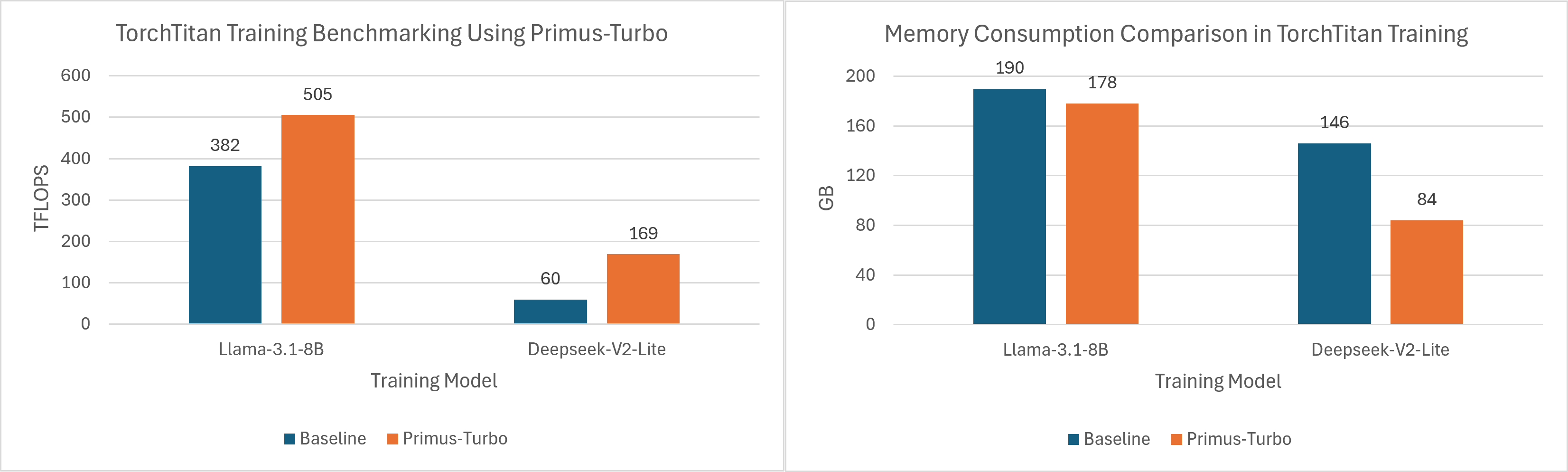
Figure 2. Primus-Turbo Performance with TorchTitan#
Megatron: Baseline vs Turbo#
In Figure 3 below, we detail the performance comparison of TorchTitan with the baseline on both the Deepseek-V2-Lite and the Deepseek-V2-8-Layers models:
DeepSeek-V2-Lite
Configs: seq-length 4096, micro batch size 4, EP=8, DP=8, running on 8xMI300X.
Turbo optimizations: MLA-Attention and Grouped GEMM.
DeepSeek-V2 8 Layers
Configs: seq-length 4096, micro batch size 4, EP=8, DP=8, running on 8xMI300X.
Turbo optimizations: MLA-Attention and Grouped GEMM.
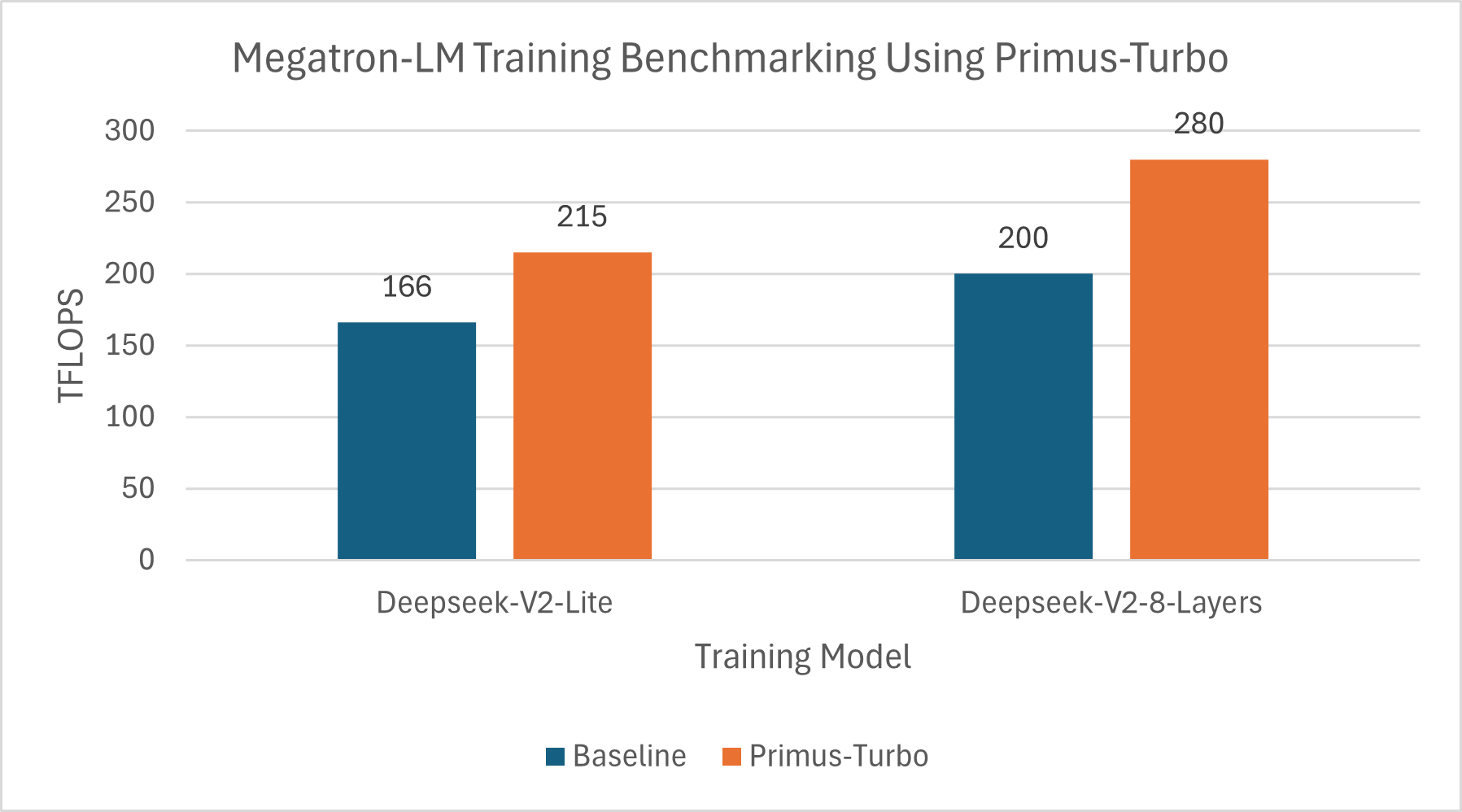
Figure 3. Primus-Turbo Performance with Megatron-LM#
Note that the above results are based on the currently adopted parallel strategy, and are intended to demonstrate the improvements of Turbo over the baseline under the same conditions.
Comprehensive Functionality#
In large-scale model development, high-performance operators alone are not enough. Many existing acceleration libraries, while strong in performance, often fall short in functionality: some only provide forward implementations without backward support, while others cover a limited set of operators but miss equally critical components. As a result, developers are forced to patch together or re-implement missing pieces during training or inference, which increases complexity and limits overall efficiency.
Primus-Turbo is designed to be a feature-complete acceleration library for large models, with a particular focus on core architectures such as Transformers.
In its first release (v0.1.0), Primus-Turbo already includes the following key components:
Components |
Features |
|---|---|
GEMM |
- Supports FP16/BF16 |
AllGather-GEMM |
- Overlap GEMM computation with communication |
GEMM-ReduceScatter |
- Supports FP16/BF16 |
Attention |
- Supports FP16/BF16 |
Grouped GEMM |
- Supports FP16/BF16 |
Ease of Use#
The third design principle of Primus-Turbo is ease of use. Our goal is to allow developers to accelerate their models with high-performance operators and components without adding extra burden.
The current release already provides a PyTorch API, enabling developers to seamlessly use Turbo’s implementations just like native operators. At the same time, we are working on JAX support, which will offer JAX users the same developer-friendly interface experience.
On the PyTorch side, Turbo components are fully integrated with torch.compile. Users do not need to worry about potential compilation failures, nor disable compilation or lower optimization levels to avoid issues. Turbo integrates reliably into existing large-model training and inference workflows, allowing developers to directly benefit from the additional performance gains brought by torch.compile.
Getting Started#
Install#
We provide prebuilt Docker images that already include Primus-Turbo:
rocm/megatron-lm:v25.8_py310
rocm/pytorch-training:v25.8
You can start a container with one of the above images. For example:
docker run -it \
--device /dev/dri \
--device /dev/kfd \
--network host \
--ipc host \
--group-add video \
--cap-add SYS_PTRACE \
--security-opt seccomp=unconfined \
--privileged \
-v /home:/workspace \
--ulimit memlock=-1 \
--ulimit stack=67108864 \
rocm/megatron-lm:v25.8_py310 \
sleep infinity
docker exec -it <container_id> bash
(Optional) If your environment does not include Primus-Turbo, you can install it manually:
# Clone repo
git clone https://github.com/AMD-AGI/Primus-Turbo.git --recursive
cd Primus-Turbo
# Install
pip3 install -r requirements.txt
pip3 install --no-build-isolation -e .
Minimal Example#
import torch
import primus_turbo.pytorch as turbo
dtype = torch.bfloat16
device = "cuda:0"
a = torch.randn((128, 256), dtype=dtype, device=device)
b = torch.randn((256, 512), dtype=dtype, device=device)
c = turbo.ops.gemm(a, b)
print(c)
print(c.shape)
For more example use cases, please refer to the Primus-Turbo Examples
Using Turbo in Primus#
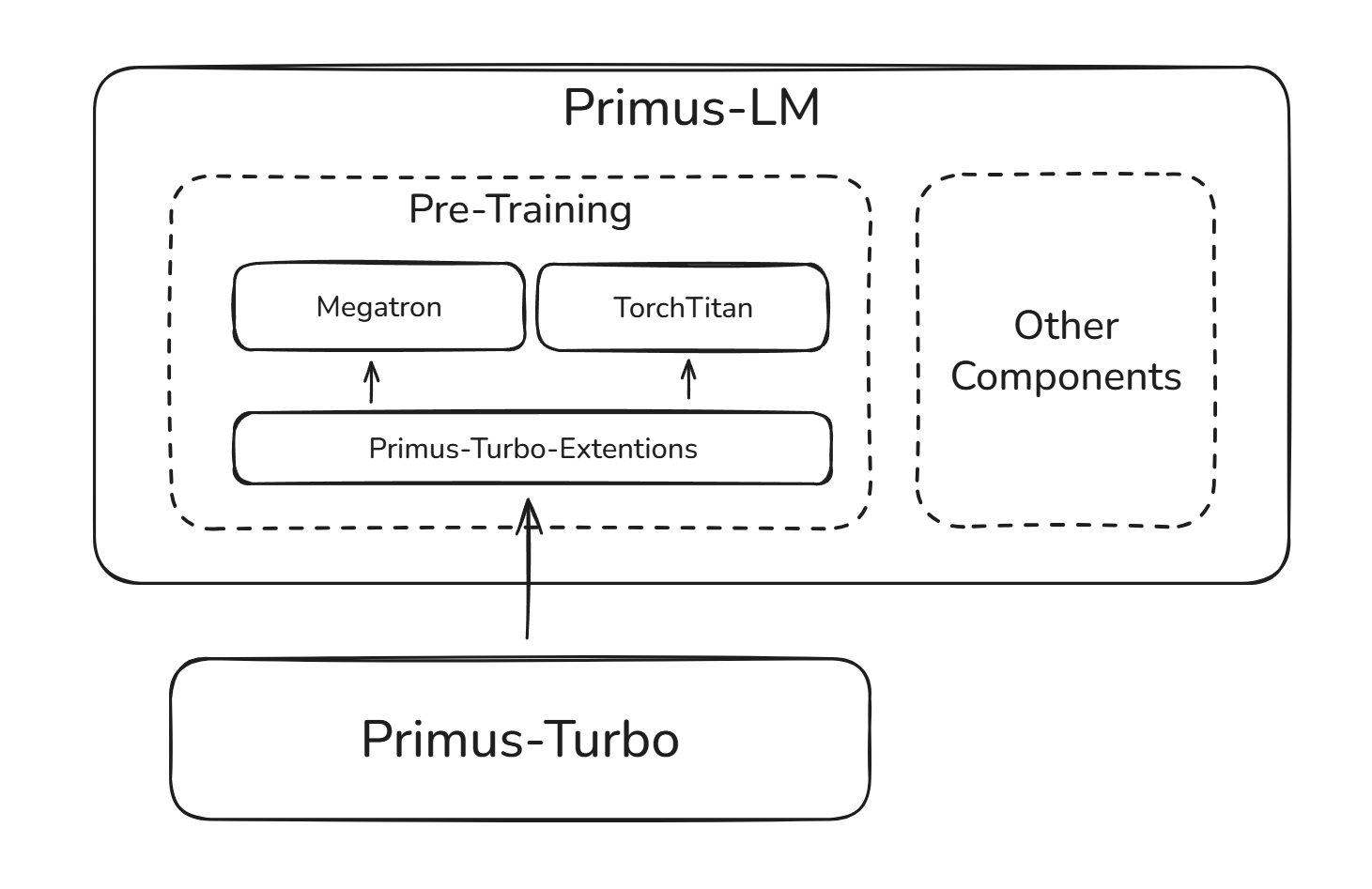
Figure 4. Primus-Turbo with Primus-LM#
In Primus, Primus-Turbo has already been integrated with internal frameworks such as Megatron and TorchTitan, as shown in Figure 4 (above), covering operators including GEMM, Attention, Grouped GEMM, and communication primitives. During training, these operators are automatically replaced with Primus-Turbo implementations through Primus-Turbo-Extensions.
Notably, Primus-Turbo-Extensions does not directly modify the source code of Megatron or TorchTitan. Instead, it performs module replacement via patching or model conversion. This design ensures non-intrusiveness to the upper frameworks while allowing Turbo to be flexibly integrated into different components of Primus.
To enable Turbo in Primus, simply set the following parameters in the YAML configuration file:
Megatron:
enable_primus_turbo: true
# enable attention
use_turbo_attention: true
# if run moe model
use_turbo_grouped_mlp: true
moe_use_fused_router_with_aux_score: true
TorchTitan:
primus_turbo:
enable_primus_turbo: true
Through this deep integration, Turbo becomes the high-performance acceleration backend of Primus, delivering end-to-end (e2e) optimization capabilities for large-scale model training on the AMD ROCm platform.
Roadmap#
The vision of Primus-Turbo is to become a general-purpose acceleration library for large-scale models in the AMD ROCm ecosystem. Following the initial release, we will continue to iterate, focusing on the following directions:
Operator Expansion: Cover a more complete training and inference pipeline for large-scale models.
Performance Optimization: Further refine key operators to push performance closer to hardware limits.
Low-Precision Support: Extend beyond FP8 to support formats such as FP6 and FP4, along with multiple quantization strategies.
Framework Integration: Complete full JAX support to enhance cross-framework usability.
Deep Integration with Primus: Enable Turbo more broadly within components like Megatron and TorchTitan to deliver end-to-end optimization.
In upcoming releases, Primus-Turbo will gradually expand to include more modules and features:
Components |
Features |
|---|---|
GEMM |
- Support for FP8 (E4M3/E5M2) with tensor-wise, row-wise, and block-wise quantization |
Attention |
- Support for FP8 (E4M3/E5M2) with block-wise quantization |
Grouped GEMM |
- Support for FP8 (E4M3/E5M2) with tensor-wise, row-wise, and block-wise quantization |
DeepEP |
- Intra-node support |
All2All |
- Support for FP8 (E4M3/E5M2) with tensor-wise, row-wise, and block-wise quantization |
Elementwise Ops |
- Support for normalization, activation functions, RoPE, and more |
… |
… |
Through these initiatives, we aim for Turbo to be more than a collection of standalone operator implementations — it will serve as the acceleration backend for large-scale training and inference on the ROCm platform.
In addition, the detailed roadmap will be published and continuously updated in the GitHub repository.
Summary#
The first release of Primus-Turbo is just the beginning. Guided by the principles of high performance, comprehensive functionality, and ease of use, we aim to provide a reliable acceleration foundation for large-scale model training and inference on the AMD ROCm platform. In future iterations, Primus-Turbo will continue to expand its module coverage, further optimize performance, support additional low-precision formats, and integrate with more frameworks — gradually becoming a vital component of the ROCm ecosystem for large-scale model development.
We invite developers and community partners to try it out, provide feedback, and contribute to Primus-Turbo. Together, we can accelerate the advancement of large-scale models on ROCm — delivering higher performance, greater stability, and improved usability.
References#
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.