AMD-HybridLM: Towards Extremely Efficient Hybrid Language Models#

The rapid rise of deep learning applications has intensified the demand for language models that offer a balance between accuracy and efficiency—especially in settings constrained by memory, compute, or real-time requirements. While Transformer-based models have revolutionized natural language processing, their quadratic attention complexity and large key–value (KV) cache requirements pose serious challenges for deployment, particularly on edge devices or in latency-sensitive environments.
Simultaneously, the growing adoption of large language models (LLMs) has created a pressing need for customization—adapting powerful pre-trained models to diverse hardware setups and application needs. However, building or retraining LLMs from scratch for each use case is computationally prohibitive and environmentally unsustainable. Common strategies like model compression, architecture search, or custom pre-training offer partial solutions, but often come at the cost of reduced quality or substantial compute overhead.
In this blog, we introduce a practical and sustainable solution: AMD-HybridLM - a family of hybrid language models (1B, 3B, and 8B) that are directly composed from existing pre-trained Transformers without full retraining. AMD-HybridLM blends two complementary components: Multi-Latent Attention (MLA) and Mamba2. Together, these building blocks, along with our initialization and distillation strategy, allow AMD-HybridLM to dramatically reduce memory usage and inference cost—without sacrificing performance.
Takeaways#
AMD-HybridLM is a family of post-trained, highly efficient hybrid models composed of Mamba and MLA blocks, designed to combine performance with speed and memory efficiency. Our key contributions are:
Architecture: We propose a hybrid model combining MLA and Mamba2 layers, replacing classical Transformer blocks to reduce memory usage and address the quadratic bottleneck of attention.
Training: We develop an efficient post-training pipeline, including refined initialization, Intermediate Layer Distillation, and SMART layer selection for hybrid model composition.
Empirical Results: Our models match or exceed Transformer-level performance with a drastically reduced KV cache and significantly improved inference throughput. Overall, AMD-HybridLM strikes a strong balance between speed and accuracy, making it ideal for efficient inference on modern GPU hardware like the AMD Instinct™ MI300X GPU. Figure 1 shows that our 8B AMD-HybridLM achieves accuracy on par with strong baselines such as Llama 3.1-8B and MambaInLlama-8B [1], while requiring significantly smaller KV cache sizes and fewer training tokens—highlighting its exceptional efficiency and suitability for modern GPU deployment.
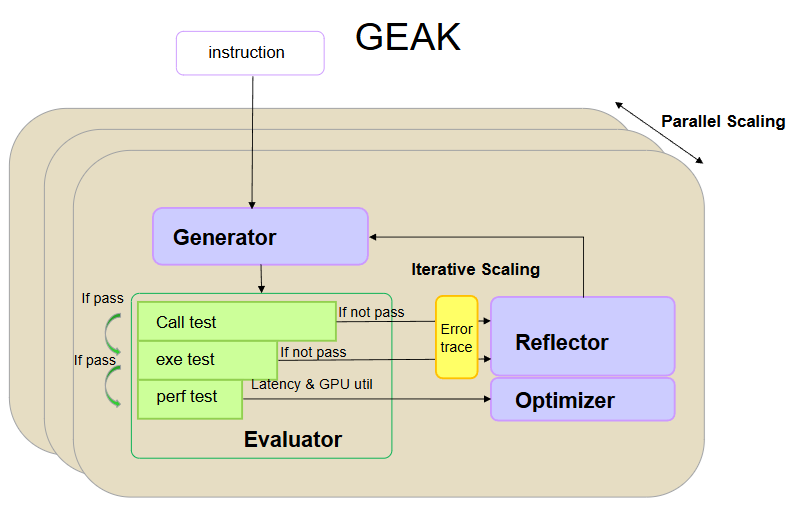
Figure 1: Overview of AMD-HybridLM-8B compared to Llama-3.1-8B and MambaInLlama-8B-50%. The AMD-HybridLM model achieves comparable accuracy while delivering up to 18x KV cache savings and 3x–1.5x higher throughput on MI300 GPUs, demonstrating strong efficiency–performance trade-offs for inference.#
AMD Hybrid Models#
We release AMD-HybridLM, a family of extremely efficient hybrid models (Table 1):
Model |
Base Model |
KV Cache Compression |
Training Token |
Training Time |
|---|---|---|---|---|
Llama3.2-1B-Inst |
12.8x |
7B |
~17 h (8x MI300) |
|
Llama3.2-1B-Inst |
25.6x |
7B |
~17 h (8x MI300) |
|
Llama3.2-1B-Inst |
25.6x |
10B |
~30h (8x MI300) |
|
Llama3.2-3B-Inst |
21.3x |
9B |
~40 h (8x MI300) |
|
Llama3.2-3B-Inst |
49.8x |
9B |
~40 h (8x MI300) |
|
Llama3.1-8B-Inst |
18.3x |
11B |
~100h (8x MI300) |
|
Llama3.1-8B-Inst |
36.6x |
11B |
~100h (8x MI300) |
Table 1: AMD family of extremely efficient hybrid models
AMD Hybrid Model Approach: Composing Extremely Efficient Hybrid Models#
Our goal is to design a hybrid model that’s more efficient without compromising on performance—ideal for real-world applications where both speed and intelligence matter.
Building Blocks#
To compose our hybrid model, we combine two complementary components: Mamba2 and MLA blocks. Each of these blocks contributes differently to efficiency and performance:
Mamba2 blocks are based on SSMs with zero KV cache usage, making them ideal for long-context or memory-constrained settings.
MLA blocks compress the standard attention process to reduce KV cache requirements while maintaining high performance. Yet, excessive compression can lead to noticeable performance drops.
Here’s how it works: We start by creating two separate versions of a powerful language model—one using only Mamba2 components, and another using only MLA components. We carefully tune both, so they retain the knowledge of the original model. Then, instead of simply mixing them randomly, we use a smart selection method that looks at how sensitive each part of the model is. This helps us decide which parts should use Mamba2 (great for speed and memory) and which should use MLA (great for precision).
Refined Initialization: How We Reuse Knowledge from Existing Models#
Training powerful AI models requires significant time, data and computational resources. So instead of starting over from scratch, our goal is to reuse as much of the knowledge from existing, pre-trained models as possible. This knowledge is captured in the model’s learned weights during pre-training. Since we’re changing the backbone architecture—from the standard Transformer to a more efficient design—it’s crucial that we transfer this learned knowledge into the new model architecture. To achieve this effectively, we use a structured two-step initialization process.
Step 1: Weight Initialization#
To build our new model efficiently, we start by initializing the Mamba2 and MLA components using a structured mapping from a pre-trained Transformer.
For initializing Mamba, recent research [1] has shown that there’s a mathematical connection between traditional attention mechanisms and the Mamba architecture. This insight allows us to transfer the learned weights from a Transformer’s attention blocks directly into Mamba’s internal structure. We use a method proposed in MambaInLLaMA to initialize Mamba2’s core parameters (A, B, C) from the original weights of the attention blocks.
To initialize MLA, we transform the Transformer’s attention layers into a more compact form called low-rank latent attention using singular value decomposition (SVD) [2]. This allows us to retain essential knowledge while making the model more efficient.
So far, we’ve explained how we initialize the weights of our model components. Using this process, we first create two separate models: a pure Mamba2 model and a pure MLA model. In each case, we replace all attention blocks in the original Transformer with either Mamba2 or MLA blocks and initialize them using the weights from the pre-trained base model (See Figure 2-left).
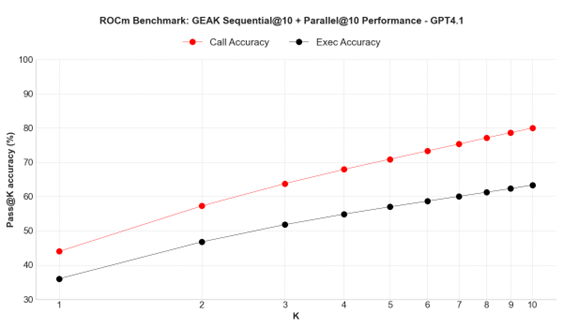
Figure 2: Overview of our hybrid model composition pipeline. Step 1) Weight Initialization – we initialize pure Mamba2 and MLA models from a pre-trained Transformer via structured mapping. Step 2) Refined Initialization through Intermediate Layer Distillation (ILD) – we refine both models by aligning their internal representations with the base model on a small dataset.#
Step 2: Refining the Initialization with Intermediate Layer Distillation (ILD)#
Once we’ve initialized the MLA and Mamba2 layers using the pre-trained Transformer, we take an extra step to fine-tune them—this is what we call Refined Initialization (See Figure 2-right). We use a lightweight technique known as Intermediate Layer Distillation (ILD), applied to a small subset of the training data. Inspired by the second phase of the MOHAWK method [4], this step helps the new model layers better match the behavior of the original Transformer. Unlike MOHAWK, which freezes the MLP components within each layer during distillation, our approach allows all parameters in the Mamba2 and MLA layers to be updated during ILD. This flexibility allows the new architecture to better adapt and align with the original model’s behavior.
SMART: Sensitivity Measure-Aware Replacement of Transformer Layers#
The final step in our initialization process is assembling the hybrid model—a thoughtful mix of MLA and Mamba2 layers, built from the fully initialized MLA and Mamba2 models. But how do we decide which layers should be MLA and which should remain Mamba2? That’s where our SMART strategy comes in—short for Sensitivity Measure-Aware Replacement of Transformer Layers. Figure 3 shows how it works:
We start by analyzing the full Mamba2 model (after ILD) and comparing it to the original Transformer. Using a technique called KL divergence, we measure how much each layer contributes to the model’s difference from the original. Then, we test the effect of replacing each layer individually with an MLA layer—one at a time—while keeping the rest as Mamba2. The sensitivity score for each layer is defined as how much this replacement reduces the KL divergence. In simple terms, a higher score means that swapping in MLA for that layer brings the model closer to the original Transformer. We then use these scores to choose the most impactful layers to assign as MLA, ensuring that our hybrid model strikes the best possible balance between efficiency and performance.
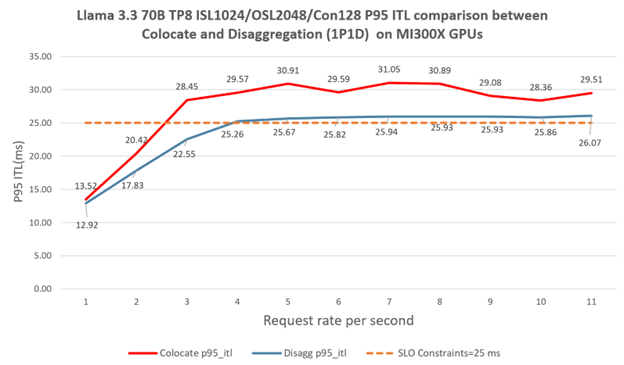
Figure 3: Overview of our hybrid model composition pipeline. Step 3) SMART Layer Selection – we compose the final hybrid model by selecting MLA and Mamba2 layers based on sensitivity analysis.#
Training Pipeline#
Once our hybrid model is initialized and assembled, we further refine it through a two-stage training process to boost both accuracy and efficiency:
Stage 1: End-to-End Knowledge Distillation#
In this stage, we train the hybrid model (the student) to closely mimic the behavior of a more powerful, pre-trained teacher model. This is done using supervised fine-tuning (SFT) with a special loss function that minimizes the difference between the teacher and student’s predictions at every step. This phase is key to transferring the deep, rich understanding from the teacher model into the more efficient hybrid student.
Stage 2: Direct Preference Optimization (DPO)#
Finally, we apply DPO, a method that fine-tunes the model based on preference data. DPO adjusts the model’s responses to better align with desired outputs by using a binary classification loss.
Experiments and Results#
Training Setup#
All of our AMD-HybridLM models are distilled from the Llama family, specifically Llama3.2-1B-Instruct, Llama3.2-3B-Instruct, and Llama3.1-8B-Instruct. For Intermediate Layer Distillation (ILD) and Supervised Fine-Tuning (SFT), we use the same dataset as in [1], which combines several public sources including OpenHermes-2.5, GenQA, and Infinity-Instruct, totaling 6.8 billion tokens. This dataset is split into 20% for ILD and 80% for SFT. To meet the target token budget, we repeat the training data across multiple epochs. For Direct Preference Optimization (DPO), we use three preference datasets: Llama3-ultrafeedback, orca_dpo_pairs, and ultrafeedback_binarized. All models were trained on a single node equipped with eight AMD MI300 GPUs.
Evaluation Tasks#
We adopt the LM Harness Eval benchmark [5] to perform zero-shot and few-shot evaluations on language understanding tasks.
Zero-shot Results#
Figure 4 summarizes our zero-shot evaluations, comparing AMD-HybridLM models against both the original Llama baselines and several recent distillation-based approaches: MambaInLLaMA [1] (a hybrid Mamba2-GQA model), X-EcoMLA [2] (a pure MLA model), and Llamba [3] (a pure Mamba2 model). For the 8B models, we have the addition of Mamba2-8B [6], Mamba2-Hybrid-8B [6] and Minitron [7] baselines. Across each model size, we experimented with different combinations of MLA and Mamba2 layers to find the best trade-off between efficiency and performance. Summary of key results:
Extreme KV Cache Compression with Strong Accuracy
1B model: 3.91% KV size (25.6× smaller), higher accuracy than base Llama.
3B model: 2.01% KV size (49.8× smaller), slightly better than Llama3.2-3B.
8B models: 5.47% and 2.73% KV size (18.3× and 36.6× smaller) with <3% accuracy drop.
Outperforms other Distillation Methods (e.g., MambaInLlama and Llamba)
Highly Efficient Training: Achieves top-tier results using just 7–11B training tokens
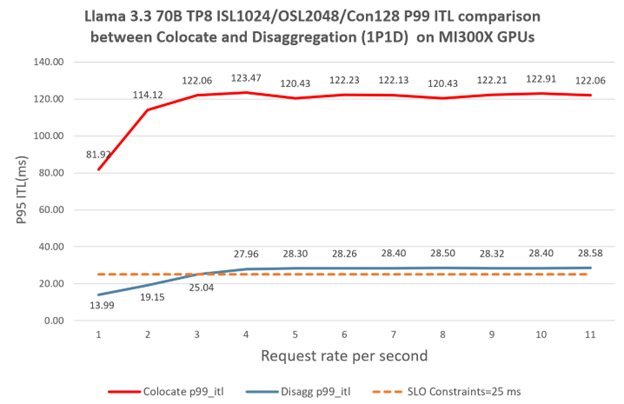
Figure 4: Zero-shot evaluation of AMD-HybridLM models on the LM Harness Eval benchmark across eight tasks: ARC-Challenge, ARC-Easy, HellaSwag, MMLU, OpenBookQA, PI, RACE, and WinoGrande. For more details refer to [8].#
Few-shot Results#
We present few-shot evaluation results for our AMD-HybridLM-8B models across five challenging tasks: 25-shot ARC-Challenge (ARC), 10-shot HellaSwag (HS), 5-shot Winogrande (WG), 5-shot MMLU (MM), and 0-shot TruthfulQA (TQ) in Table 2.
AMD-HybridLM (16MLA–16M2) achieves the best overall performance with an average score of 66.78, while using only 5.47% of the KV cache - a dramatic compression without sacrificing accuracy.
The closest competitor, MambaInLlama-50%, performs slightly worse (66.60) while consuming 9.14× more KV cache and requiring 1.8× more training tokens.
Pure Mamba2 models like MambaInLlama-0% and Llamba have zero KV cache, but this comes at the cost of significantly lower performance.
Model and Setting |
KV % |
Avg. |
ARC |
HS |
MM |
WG |
TQ |
|---|---|---|---|---|---|---|---|
Llama3.1-8B-Inst |
100% |
67.36 |
60.75 |
80.12 |
68.23 |
73.72 |
53.99 |
MambaInLlama-50% |
50% |
66.60 |
60.41 |
77.97 |
56.67 |
71.35 |
66.60 |
MambaInLlama-0% |
0% |
55.85 |
53.51 |
70.31 |
44.21 |
58.91 |
52.31 |
Llamba |
0% |
63.44 |
57.94 |
77.13 |
59.89 |
72.77 |
49.46 |
X-EcoMLA-8B (rkv=128) |
9.37% |
65.51 |
59.64 |
76.90 |
58.73 |
71.43 |
60.86 |
AMD-HybridLM (16MLA–16M2) |
5.47% |
66.78 |
60.49 |
78.29 |
58.84 |
71.98 |
64.28 |
AMD-HybridLM (8MLA–24M2) |
2.73% |
64.74 |
60.41 |
76.11 |
55.06 |
71.11 |
61.01 |
Table 2: Few-shot evaluation on the LM Harness Eval benchmark across five tasks.
Inference Evaluation (Throughput vs. Context Length)#
We benchmarked inference throughput vs. context sequence length for various 8B models at batch size 48 and with the output length=1024 tokens on AMD MI300X GPU, and the results are presented in Figure 5. Throughput drops with longer contexts for all models, but AMD-HybridLM models degrade much more gracefully.
Figure 5: Inference throughput vs. output sequence length of various 8B-size models on MI300X (BS=48, output_len=1024).#
Inference Evaluation (Throughput scaling with Batch Size)#
Figures 6 and 7 show the throughput and peak memory usage of the 8B models for different batch sizes on MI300X when input and output sequence lengths are 1K and 8K respectively:
Our AMD-HybridLM model shows the best throughput consistently across all batch sizes. Llama 3.1 8B hits the memory limit beyond BS=128 which makes it less suitable for high throughput scenarios.
Considering these inference results alongside the previously presented accuracy metrics, we conclude that our hybrid models (AMD-HybridLM family) offer a highly promising balance between accuracy and inference efficiency.
Figure 6: Inference throughput vs. batch size of various 8B-size models. We measure the throughput with output sequence length 8K on a single MI300X.#
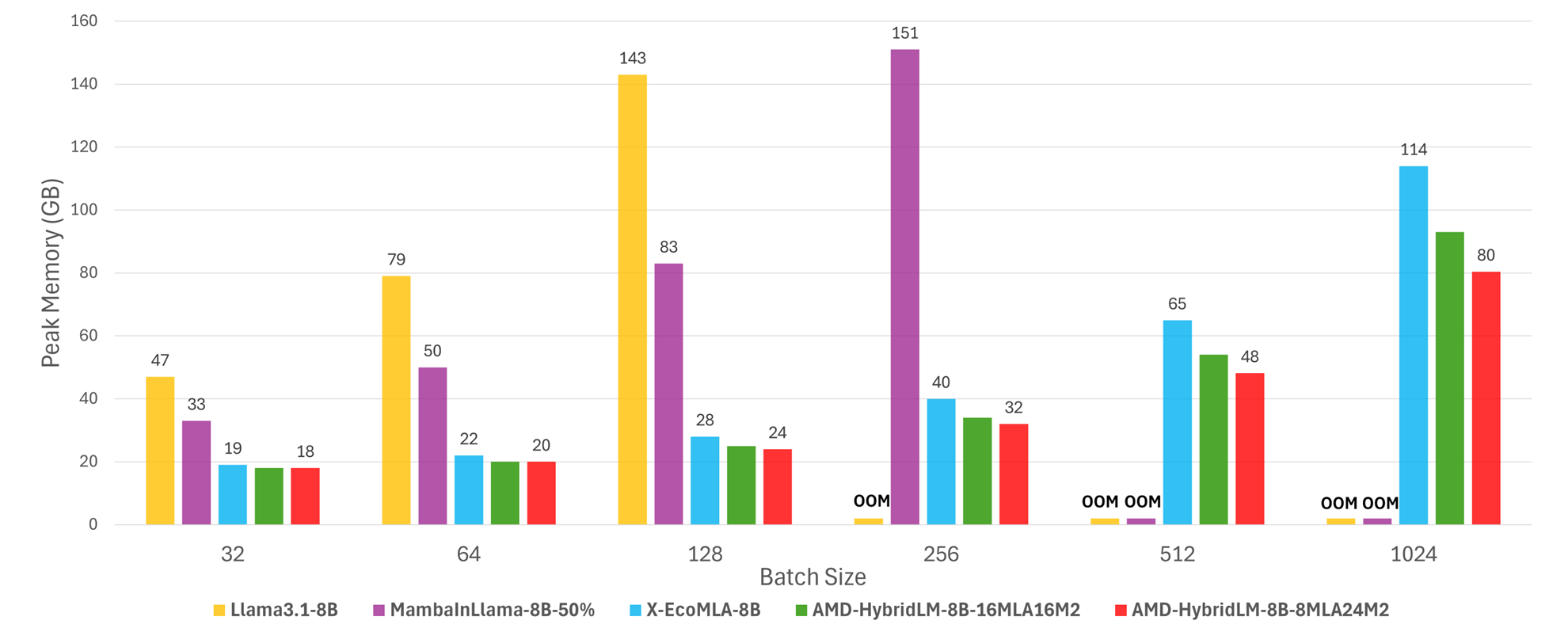
Figure 7: Peak memory usage during inference vs. batch size of various 8B-size models. We measure the memory footprint with output sequence length 8K on a single MI300X.#
Training Long-Sequence Hybrid Models#
Lately, we extended AMD-HybridLM with improved long-context and reasoning abilities by adding ~3B extra tokens of long-context SFT (ChatQA2-Long-SFT-data) and math reasoning data (OpenThoughts-114k-math, OpenMathInstruct-2, OpenR1-Math-220k). Using a single-stage SFT approach on 10B data with 8K context, the models were evaluated on LM-Harness, RULER, and GSM8K. As shown in Table 3, the long-sequence AMD-HybridLM improves math reasoning significantly (GSM8K), while retaining competitive performance on LM-Harness and RULER benchmarks.
Model/config |
LM-Harness |
RULER-4K |
RULER-8K |
GSM8K |
|---|---|---|---|---|
LLaMA3.2-1B-Inst |
51.93 |
66.12 |
60.54 |
38.51 |
AMD-HybridLM-1B, 4MLA-12M2-Long-8K (SFT) |
50.48 |
59.41 |
52.16 |
42.67 |
Table 3: Performance of long-sequence AMD-HybridLM (8K SFT) compared to the baseline.
Summary#
In this work, we introduce AMD-HybridLM - a family of highly efficient hybrid models developed by AMD, built from existing pre-trained Transformers. Spanning 1B, 3B, and 8B sizes, AMD-HybridLM combines Mamba2 and MLA layers to drastically reduce memory usage without compromising performance. To achieve this, we designed a novel initialization strategy and a lightweight post-training distillation pipeline that transfers knowledge from larger teacher models with minimal overhead. Our results show that AMD-HybridLM matches or even outperforms strong baselines in accuracy, while requiring significantly less KV cache and compute - highlighting hybridization as a powerful and eco-friendly alternative to full retraining.
References#
[1] Wang, Junxiong, Daniele Paliotta, Avner May, Alexander M. Rush, and Tri Dao. “The mamba in the llama: Distilling and accelerating hybrid models.” arXiv preprint arXiv:2408.15237 (2024).
[2] Li, Guihong, Mehdi Rezagholizadeh, Mingyu Yang, Vikram Appia, and Emad Barsoum. “X-ecoMLA: Upcycling pre-trained attention into mla for efficient and extreme kv compression.” arXiv preprint arXiv:2503.11132 (2025).
[3] Bick, Aviv, Tobias Katsch, Nimit Sohoni, Arjun Desai, and Albert Gu. “Llamba: Scaling distilled recurrent models for efficient language processing.” arXiv preprint arXiv:2502.14458 (2025).
[4] Bick, Aviv, Kevin Li, Eric Xing, J. Zico Kolter, and Albert Gu. “Transformers to ssms: Distilling quadratic knowledge to subquadratic models.” Advances in Neural Information Processing Systems 37 (2024): 31788-31812.
[5] Leo Gao, Jonathan Tow, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Kyle McDonell, Niklas Muennighoff, Jason Phang, Laria Reynolds, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. A framework for few-shot language model evaluation. 2023.
[6] Waleffe, Roger, Wonmin Byeon, Duncan Riach, Brandon Norick, Vijay Korthikanti, Tri Dao, Albert Gu et al. “An empirical study of mamba-based language models.” arXiv preprint arXiv:2406.07887 (2024).
[7] Muralidharan, Saurav, Sharath Turuvekere Sreenivas, Raviraj Joshi, Marcin Chochowski, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro, Jan Kautz, and Pavlo Molchanov. “Compact language models via pruning and knowledge distillation.” Advances in Neural Information Processing Systems 37 (2024): 41076-41102.
[8] Yang, Mingyu, Mehdi Rezagholizadeh, Guihong Li, Vikram Appia, and Emad Barsoum. “Zebra-Llama: Towards Extremely Efficient Hybrid Models.” arXiv preprint arXiv:2505.17272 (2025).
Additional Resources#
Citations#
The content presented here is based on the two papers listed below. We encourage you to reference these works if they contribute to your research or applications.
@article{li2025x_ecomla,
title={{X-EcoMLA}: Upcycling Pre-Trained Attention into {MLA} for Efficient and Extreme {KV} Compression},
author={Li, Guihong and Rezagholizadeh, Mehdi and Yang, Mingyu and Appia, Vikram and Barsoum, Emad},
journal={arXiv preprint arXiv:2503.11132},
year={2025},
url={https://arxiv.org/abs/2503.11132}
}
@article{yang2025zebra,
title={Zebra-Llama: Towards Extremely Efficient Hybrid Models},
author={Yang, Mingyu and Rezagholizadeh, Mehdi and Li, Guihong and Appia, Vikram and Barsoum, Emad},
journal={arXiv preprint arXiv:2505.17272},
year={2025},
url={https://arxiv.org/abs/2505.17272}
}
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.