Technical Dive into AMD’s MLPerf Inference v5.1 Submission#

In the rapidly evolving landscape of artificial intelligence, the demand for reliable and efficient model inference has never been greater. With advancements in large language models (LLMs) and a growing reliance on real-time applications, benchmarks are critical in evaluating how well AI systems perform under varying conditions. Enter MLPerf Inference: Datacenter v5.1 — a significant update to the well-respected benchmarking suite that assesses inference performance across a wide array of models and use cases, catering especially to data centers.
MLPerf Inference 5.1 was released on September 9th 2025 and for this round AMD has decided to showcase both hardware performance as well as capabilities and versatility of the ROCm software stack. To that end, AMD latest results bring improved performance on existing and new GPUs for standard MLPerf models alongside pruned models in the Open category. The highlights of the results include:
First-ever MLPerf results for MI355X on Llama 2 70B on 1, 4, and 8 nodes
Pruned Llama3.1-405b model on MI355X demonstrating versatility of AMD SW tools
First ever results for Mixtral-8x7b and Llama2-70b Interactive benchmarks
8 node multi-node submission on Llama2-70b
Improved performance on Llama2-70b and SD-XL on MI325X
Read on for optimizations and improvements that made those results possible. To learn how to replicate these results, see Reproducing the AMD Instinct™ GPUs MLPerf Inference v5.1 Submission. For specific insights into optimizing Llama 3.1 405B, check out Slim Down Your Llama: Pruning & Fine-Tuning for Maximum Performance.
MI355X Architecture#

Figure 1: MI355X architectural diagram#
The most exciting part of AMD’s submission is the inclusion of the MI355X GPU, a new generation of Instinct GPUs launched only a few weeks before the submission. This GPU represents a leap forward in data center acceleration, built specifically to deliver exceptional performance for AI workloads, high-performance computing (HPC), and large-scale cloud deployments. Based on AMD’s advanced CDNA architecture, it is engineered for both raw compute power and efficiency, making it a compelling choice for organizations looking to push the limits of AI model training and inference. The MI355X integrates tightly with AMD’s ROCm software ecosystem, providing developers with a mature, open platform for building and scaling AI applications.
The MI355X excels with its robust support for FP4 (4-bit floating-point) precision, delivering up to 20 petaflops of performance for this data type, a critical feature for deploying large-scale AI models. This high-performance FP4 computation, paired with 288 GB of high-bandwidth HBM3 memory and a memory bandwidth of 8TB/s, significantly reduces memory and compute overhead without compromising accuracy, as shown in Figure 1. These specifications make the MI355X ideal for modern generative AI models, supporting low-latency inference for large-scale model serving with many concurrent users, while also enabling efficient training on massive datasets.
Thermal efficiency is another hallmark of the MI355X, thanks to its support for liquid cooling. This advanced cooling solution ensures consistent peak performance under sustained heavy workloads while reducing data center energy demands. For operators managing dense GPU clusters, liquid cooling not only enables higher sustained clock speeds but also contributes to greater system reliability and longer hardware lifespan.
In short, the AMD Instinct MI355X delivers a blend of raw performance, efficient memory handling, scalability, and software ecosystem support, positioning it as a top contender in the rapidly evolving world of AI and HPC acceleration.
Results and Optimizations for MI355X#
The MI355X was launched on June 12, 2025, just six weeks before the MLPerf Inference v5.1 submission deadline. This tight timeline constrained our ability to fully optimize for the new GPU platform, which introduced significant hardware advancements and improvements. The results presented below are preliminary and expected to improve in future rounds. These findings represent the first MXFP4 results for an industry standard benchmark, confirming the performance and accuracy of this new GPU platform.
Llama 2 70B on MI355X in MXFP4#
For MLPerf Inference v5.1, we submitted Llama 2 70B in the open category with only the Offline scenario. Although the open division permits deviations from the standardized constraints of the closed division, we have complied with the closed division constraints to ensure rigor, comparability, and reproducibility. Interested readers can compare our results to those in the closed section to observe that our performance compares favorably to the results reported there.
This submission builds on our optimizations of this model on MI325X, which was covered in length in our blog on v5.0 submission. In particular, we have re-used optimizations for vLLM configuration tuning, load balancing and scheduler optimizations, etc., for MI355x.
GEMM Tuning#
Figure 2 shows that MXFP4 GEMMs account for about 62% of the end-to-end computation cost in Llama2-70B model. We profiled the workload to identify the performance critical GEMMs and optimized them with appropriate tile selection in AITER to achieve high TFLOPs. Since the workload is GEMM dominated, this is a high-impact optimization for improving the throughput.
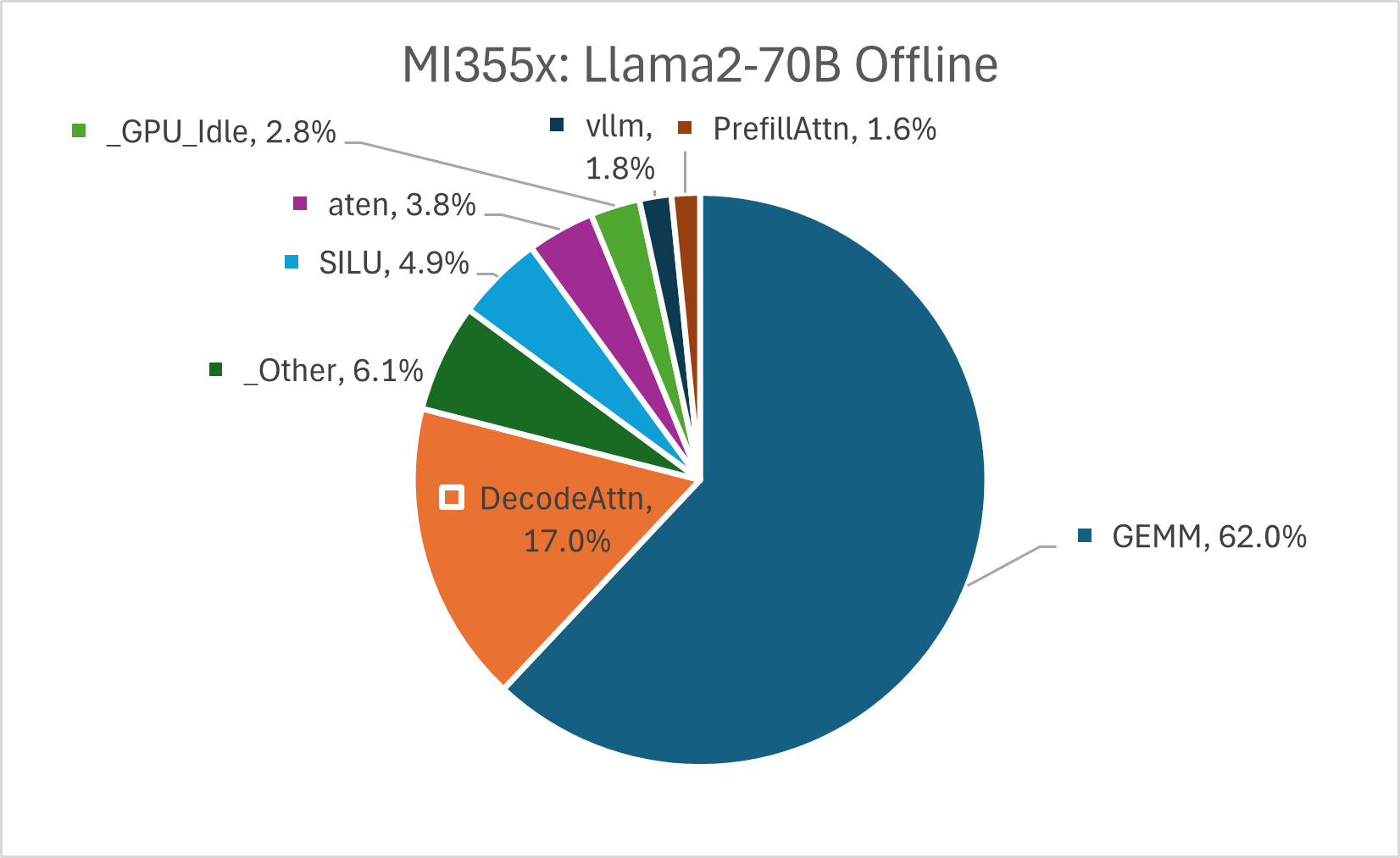
Figure 2: Breakdown of kernel execution times for Llama2-70B on MI355X#
Idle Time Reduction#
Utilizing the GPU’s compute capacity completely is essential for high performance. However, there are several factors that can limit the GPUs from being fully utilized. These show up as GPU idle times. We perform the following idle-time reduction techniques to improve the GPU utilization.
We pre-compile Triton kernel shapes to prevent JIT compilation overheads during the performance runs.
We use HipGraph mode to streamline kernel launches. This prevents any idle times between kernels in the same forward pass.
Finally, to reduce the CPU overhead while scheduling the GPU kernels, we compile vLLM using Cython and -Ofast flag. This minimizes the vLLM scheduling overhead.
Performance Comparison - Llama 2 70B#
Figure 3 shows the performance of Llama 2 70B offline scenario on MI355X and contrasts it with MI325X. MI355X shows 2.7 \(\times\) improvement over MI325X due to superior architecture and MXFP4 capabilities.
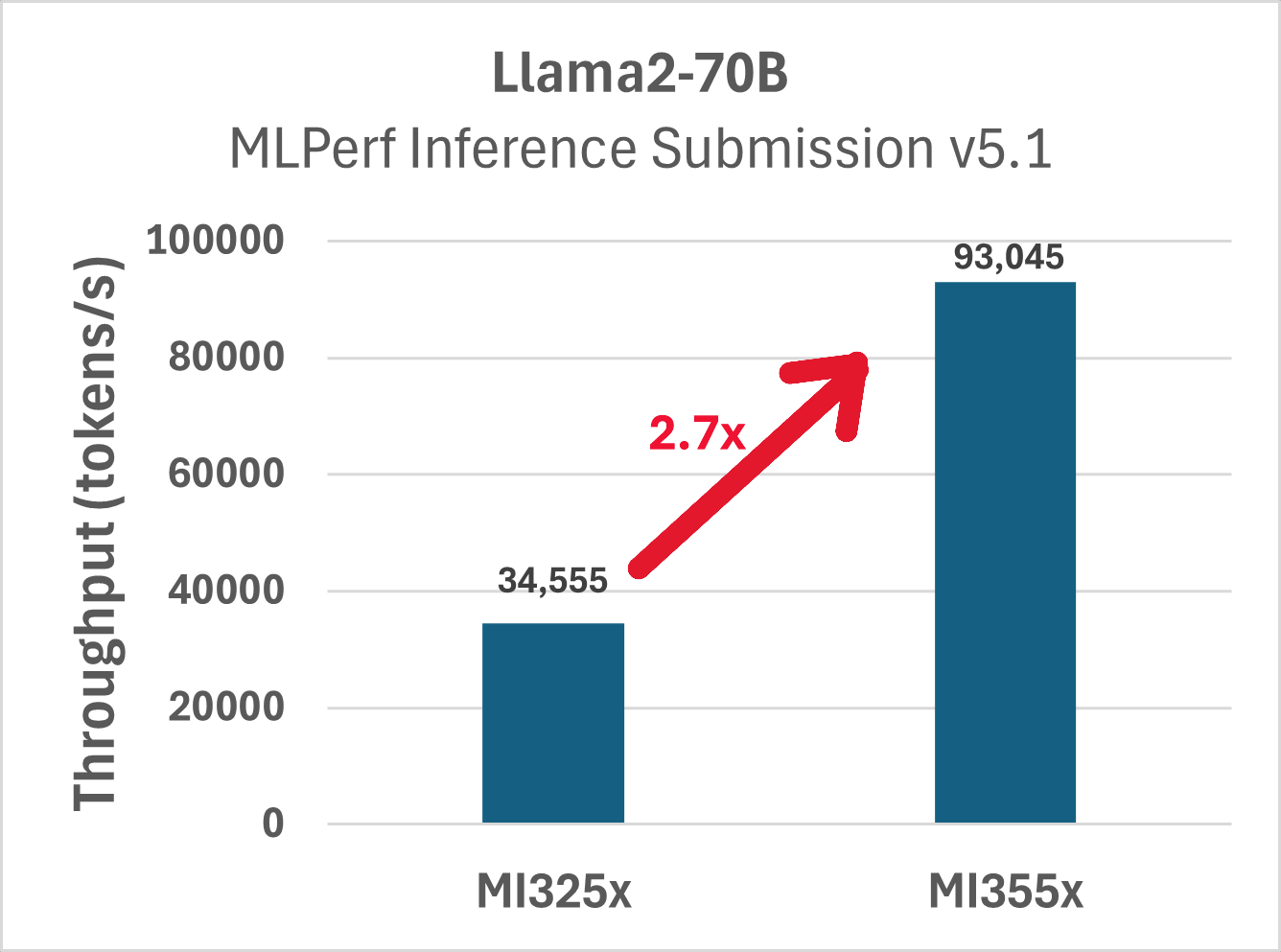
Figure 3: Performance comparison of MI355X (MXFP4) vs MI325X (FP8) for the Llama2-70B Offline workload#
Llama 3.1 405B#
For Llama 3.1 405B, our focus has been on model optimization rather than maximizing peak performance. Techniques such as pruning have proven effective for large models, delivering substantial performance gains while preserving accuracy. Our results validate these methods and showcase the robust capabilities and readiness of the ROCm software stack on the MI355X platform.
Model Pruning and Finetuning#
Our work shows that depth-pruning of the Llama 3.1 405B model can greatly enhance its performance. One benefit is decreasing the memory requirement to store the model weights. In addition to improving the speed of forward passes due to fewer layers, it further allows for larger KV-cache. Furthermore, we demonstrate that with supervised fine-tuning of the pruned model of Llama 3.1 405B, high inference accuracy can be achieved for both RougeL and Exact Match metrics for Llama-3.1-405B workloads in the MLPerf settings. A detailed description of our pruning work can be found in a dedicated blog post.
vLLM Tuning#
To improve performance of the Llama3.1-405b model we conducted extensive tuning experiments of vLLM parameters. In particular, the parameters max_model_len and max_seq_len_to_capture were found to be crucial for Hip graph capture to minimize GPU idle time. To further reduce GPU idle time (due to waiting for CPU operations) we tune the vLLM configuration parameter of num_scheduler_steps to use a multi-step vLLM scheduler. We also tune vLLM parameters max_num_batched_tokens, max_num_seqs, kv_cache_dtype and block size to maximize performance in terms of generated tokens per second given limited KV cache size.
Load Balancing#
The Llama 3.1 405B dataset input sequence lengths range from 476 to 19988 tokens with an average of 9428. The output sequence lengths range from 3 to 2000 tokens with an average of 684 tokens. We developed ZigZag sorting, where a contiguous range of samples sorted with ascending order is followed by a contiguous range of samples sorted with descending order, for load balancing among GPUs when allocating workloads to each GPU. We also present long-short interleaving, where long prompt and short prompt are arranged in an interleaving order for workloads on each GPU to facilitate better batching arrangement to maximize GPU utilization.
Performance Comparison - Llama 3.1 405B#
We show our main results in Table 1. In the first example, we pruned 26 layers out of 126 layers of the original model of Llama 3.1 405B, i.e., 20.6% of the layers being pruned. We obtain a performance of 1942 tokens/s while maintaining the RougeL and Exact Match accuracy both above 96% compared with MLPerf reference accuracy scores. In the second example, we pruned 42 layers out of 126 layers of the original model of Llama 3.1 405B, i.e., 33.3% of the layers being pruned. With supervised fine-tuning to bring the accuracy back, we see a performance of 2019 tokens/s while maintaining the RougeL and Exact Match accuracy both above 96.7% compared with MLPerf reference accuracy scores.
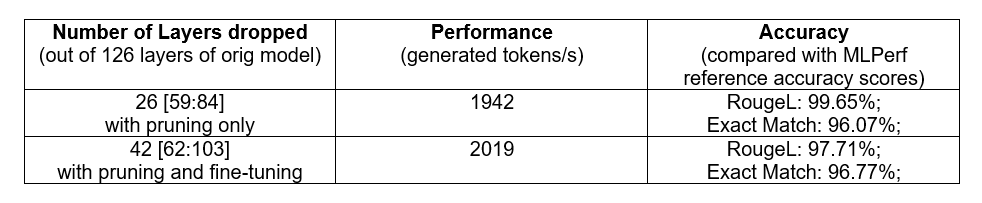
Table 1: Performance comparison with intelligent (a) depth-pruning only and (b) depth-pruning and fine-tuning for Llama 3.1 405B model.#
Optimization Strategies for MI325X#
Llama 2 70B on MI325X#
MI325x is the previous generation of AMD Instinct GPUs. We have demonstrated competitive performance on MI325x in MLPerf Inference v5.0 submission. For the MLPerf Inference v5.1 submission, we have improved the performance by about 2% and 4% in offline and server scenarios, respectively, over MLPerf Inference v5.0 submission. The technical deep dive for Llama 2 70b on MI325x for MLPerf Inference 5.0 can be found here: MI325x Llama2-70B technical blog
GEMM optimizations#
Since GEMMs account for the bulk of the total computation cost for the Llama2-70b model, we see a speedup with the Swizzle optimization. Swizzle is a GEMM optimization that converts the in-memory weight layout of the GEMMs to avoid Local Data Storage (LDS) on AMD GPUs. We integrated the swizzling technique using the torchao extension to swizzle the model weights after loading in vLLM followed by GEMM tuning to pick the optimal solution for a given m,n,k shape. We see a performance boost in both compute and memory bound GEMMs with this optimization. More information about Cross Lane Operations and Swizzle can be found here.
Interactive Scenario#
To evaluate the performance of LLMs in a high responsiveness environment, MLPerf has introduced an Interactive scenario where the TTFT and TPOT requirements are lowered to 450 ms and 40 ms, respectively. These latency constraints are much more stringent compared to the server scenario, where the TTFT and TPOT requirements are 2s and 200 ms, respectively.
Two key optimizations enable optimal performance under Interactive constraints: small GEMM tuning and the use of vLLM v1. The former is necessary because tight latencies require small batch sizes, resulting in smaller matrices. These require specific GEMM tuning for best performance, Additionally, vLLM v1 mixes decodes and prefills, which we find beneficial for Interactive performance.
Mixtral 8x7B#
MoE Sorting Kernel Optimization#
One of the core operations in the MoE is the sorting operation. The non-linear complexity of sorting creates performance bottlenecks for larger contexts (larger prefill and decode batches). We address this issue by parallelizing (a) histogram calculation and (b) sorting reduction operation.
MoE Kernel Optimizations#
We leverage the AMD Composable Kernel (CK) library’s FusedMoE block operator for implementing the MoE logic. The FusedMoE has the following key optimizations:
Fuse input gather, group-gemm1, activation and scaling into a single kernel
Atomic output scatter, group-gemm2 and scaling for gemm2 accumulation
Pre-shuffled weight matrix during weights loading to maximize memory throughput
Optimized pipelining and scheduling of memory and compute operations for improved performance
Utilized Matrix Fused Multiply-Add (MFMA) instructions to implement MoE GEMMs for maximizing computational throughput
The above optimizations resulted in a 23% end-to-end throughput improvement. These optimizations are available through the AITER package. AITER is AMD’s centralized repository that supports a variety of high performance AI operators for AI workloads.
In addition to kernel optimizations, vLLM config tuning was performed to obtain the best throughput
SD-XL#
For the MLPerf Inference v5.1 submission, we improved performance by approximately 8% in the offline scenario compared to our MLPerf Inference v5.0 submission. A significant contributor to the offline scenario gains was the use of Python 3.13’s free-threaded mode (python3.13t), with the Global Interpreter Lock (GIL) disabled via PYTHON_GIL=0. This enabled near-true asynchronous operation, boosting inference throughput by eliminating GIL-related bottlenecks in dispatching work from CPU to GPU. Minimal code adjustments were needed to address library compatibility with Python 3.13’s free-threaded mode. A detailed technical deep dive into SD-XL optimizations for MI325X, carried over from MLPerf Inference v5.0 to v5.1, can be found here.
Performance Comparison#
In our MLPerf Inference submission, we used AMD Quark, which is an open-source, state-of-the-art model optimization toolkit that brings together optimization techniques such as quantization and pruning. It comes with extensive documentation and usage examples, providing practical and production-ready solutions for a broad range of users. Quark also supports inference workloads through widely used frameworks such as vLLM and SGLang, enabling seamless deployment of optimized models at scale. In this submission, we significantly expanded our scope by introducing new model architectures, delivering the OCP MXFP4 format, and scaling up to ultra-large models. Building upon our previous submission of Llama-2-70B in OCP FP8-e4m3, we now deliver Llama-2-70B (OCP MXFP4), Mixtral-8x7B (OCP FP8-e4m3), and Llama-3.1-405B (OCP MXFP4). The following sections detail the quantization strategies behind these results.
Quantization Strategy#
For calibration, we used the full calibration dataset provided by mlcommons/inference for each model. Inputs from the dataset were tokenized and serialized into fixed-length sequences using dynamic padding and truncation as part of preprocessing.
We quantized weights and activations of all nn.Linear modules (from PyTorch) to OCP FP8-e4m3 or OCP MXFP4 formats. Additionally, KV caches were quantized to OCP FP8-e4m3. We apply specific post-quantization algorithmic techniques, namely AutoSmoothQuant and GPTQ, for MXFP4 quantization.
OCP FP8-e4m3 Quantization#
We applied per-tensor symmetric static quantization weights and activations of nn.Linear modules—using the following formula:
where \(x_q\) is the quantized form of value \(x\), scale is the maximum absolute value (absmax) of the tensor, the constant 448 represents the numerical range of values in OCP FP8-e4m3. The scaled value is rounded using the half-even method after clipping.
OCP MXFP4 Quantization#
For OCP MXFP4, we used static quantization for weights and dynamic quantization for activations. The quantization formula is:
MXFP4 encodes 32 values per micro‑block, with each block sharing one 8‑bit E8M0 (power‑of‑two) scale factor and each element stored as a 4‑bit E2M1 floating‑point number. \(x^{MXFP4}_q\) is the quantized form of value x, scale is a power‑of‑two value, stored once per block in 8‑bit E8M0 format. All values, x, are scaled such that x / scale falls within the representable FP4 range [−6, 6]. We apply even-rounding in calculating scales to obtain better accuracy.
System Tuning#
While GPUs drive the majority of performance, optimized server design and configuration also significantly enhance overall performance. Specifically, a high-frequency CPU, such as the AMD EPYC™ 9575F, delivers optimal results as an AI head node, executing the CPU software stack with minimal overhead to maximize GPU performance.
System optimizations and tuning can be grouped into the following categories:
BIOS Options:
High Performance mode & Core Performance boost (set to enable): Enables Core Performance Boost to reach up to 5GHz with AMD EPYC™ 9575F.
Determinism Control/Enable (set to Power): Maximum performance of any individual system by leveraging the capabilities of a given CPU to the maximum.
Nodes Per Socket (NPS – set to 1 or 4 based on workload affinity): This setting enables a trade-off between minimizing local memory latency for NUMA-aware (in our MLPerf Harness stack we do NUMA aware scheduling) vs. maximizing per- core memory bandwidth for non-NUMA-friendly workloads.
APBDIS (set to 1): Enable fixed Infinity Fabric P-state control.
DC C-states (set to Disabled): Prevent the AMD Infinity Fabric from entering a low-power state.
SMT Control (Disabled): Single hardware thread per core.
OS Configuration:
CPU Core States (C-states): Deeper sleep state (C2) is disabled and frequency governor is set to performance (e.g., using Linux cpupower utility)
Reduce any performance overhead of the CPU or memory:
echo 0 | sudo tee /proc/sys/kernel/nmi_watchdog
echo 0 | sudo tee /proc/sys/kernel/numa_balancing
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
echo ‘always’ | sudo tee /sys/kernel/mm/transparent_hugepage/enabled
echo ‘always’ | sudo tee /sys/kernel/mm/transparent_hugepage/defrag
For MI325X, we have set the GPU clock max to be 1600Mhz (Mixtral) and 1700Mhz (Llama2-70B) for optimal performance for the above system tuning. More optimization options are discussed in respective AMD product tuning guides.
Results Overview#
MXFP4 Submission of Llama2-70b on MI355X#
First ever MLPerf score using MXFP4 showed an excellent performance improvement over FP8 performance on our previous generation GPU. Theopen score following closed rules showed 2.7x performance improvement demonstrating capabilities of the new GPU.
Multinode scaling of Llama2-70b on MI355X in MXFP4#
We have further demonstrated MI355X capabilities by extending our single node Llama2-70b submission to 4 and 8 nodes. Compared to our internal baselines, the 4 node achieves 3.9x better performance and the 8 node submission shows 7.9x improvement over our single node baseline.
Compared to the 4 node submission on MI325X in the previous round, submission ID 5.0-0054, our current MI355X 4 node score, submission ID 5.1-0102, is 3.4x faster.
Depth-Pruning Acceleration of Large Models#
We have submitted two types of prunings:
A 21% depth-pruned model delivered up to an 82% increase in inference throughput, with a minimal accuracy loss
A 33% pruned model that was subsequently fine-tuned. This approach achieved 90% performance uplift while still maintaining high accuracy
New Models on MI325X#
An important part of our submission has been optimizing new models for Instinct GPUs. In this round we have added Llama2-70B Interactive and Mixtral-8x7B workloads on MI325X in FP8. The results show competitive performance when compared to the Nvidia H200, a GPU of the same generation and similar capabilities. Figure 4 below shows the comparison, in which an average of H200 results is used as a basis. Note the performance leadership of our Mixtral-8x7B Offline score.

Figure 4: Performance comparison of MI325X vs average of Nvidia H200 scores for the Llama2-70B Interactive and Mixtral-8x7b workloads#
Continued Performance Improvements on MI325X#
In this round, we improved the performance of Llama2-70B and SD-XL, previously submitted in v5.0. As shown in Figure 5, these results demonstrate highly competitive performance compared to GPUs of the same generation:

Figure 5: Performance comparison of MI325X vs average of Nvidia H200 scores for the Llama2-70B and SD-XL workloads#
First Ever Heterogeneous Submission#
This round marks an MLPerf first: a heterogeneous submission by our partner MangoBoost, combining four MI300X nodes and two MI325X nodes for Llama2-70B inference. This configuration achieves an impressive 94% efficiency compared to single-node submissions from these platforms, as shown in Figure 6.

Figure 6: First ever heterogeneous submission by AMD partner, MangoBoost#
Partners Submissions#
The MLPerf Inference v5.1 submission highlights the growing strength of the AMD Instinct GPU ecosystem, with partners delivering performance that is nearly identical to AMD reference results across both Instinct MI325X and MI300X platforms. On MI325X the partner submissions come from Asus, Giga Computing, MangoBoost, MiTAC, QCT, Supermicro, and Vultr. On MI300X our partners were Dell and MangoBoost.
Summary#
This blog provides a technical dive into the optimizations of AMD’s MLPerf Inference v5.1 submission. The flagship GPU in the AMD Instinct series, MI355x, was used for the Llama 2 70B and Llama 3.1 405B models. The MI325x was used for Llama 2 70B and Mixtral 8x7B models. For hands-on guidance on replicating these results, visit Reproducing the AMD Instinct™ GPUs MLPerf Inference v5.1 Submission. To explore our pruning and fine-tuning strategies for Llama 3.1 405B, see Slim Down Your Llama: Pruning & Fine-Tuning for Maximum Performance.
Acknowledgements#
We would like to sincerely thank Ali Zaidy, Willa Zhu, Huan Zheng, Lingpeng Jin and Carlus Huang for their valuable contributions.
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.