Nitro-E: A 304M Diffusion Transformer Model for High Quality Image Generation#

We present Nitro-E, an extremely lightweight diffusion transformer model for high quality image generation. With just 304M parameters, Nitro-E is designed to be resource-friendly for both training and inference. For training, it only takes 1.5 days on a single node with 8 AMD Instinct™ MI300X GPUs. On the inference side, Nitro-E delivers a throughput of 18.8 samples per second (batch size 32, 512px images) on a single AMD Instinct MI300X GPU. The distilled version can further increase the throughput to 39.3 samples per second. On a consumer iGPU device Strix Halo, our model can generate a 512px image in only 0.16 seconds. A more detailed comparison can be seen in Figure 1, where our models achieve promising scores on GenEval while showing clearly higher throughputs.
In line with AMD’s commitment to open source, we are releasing our model weights and full training code for easy reproducibility. We hope our model can serve as a strong and practical baseline for future research and further contribute to the democratization of generative AI models. In this blog, we provide a general introduction to our model designs and other technical details.
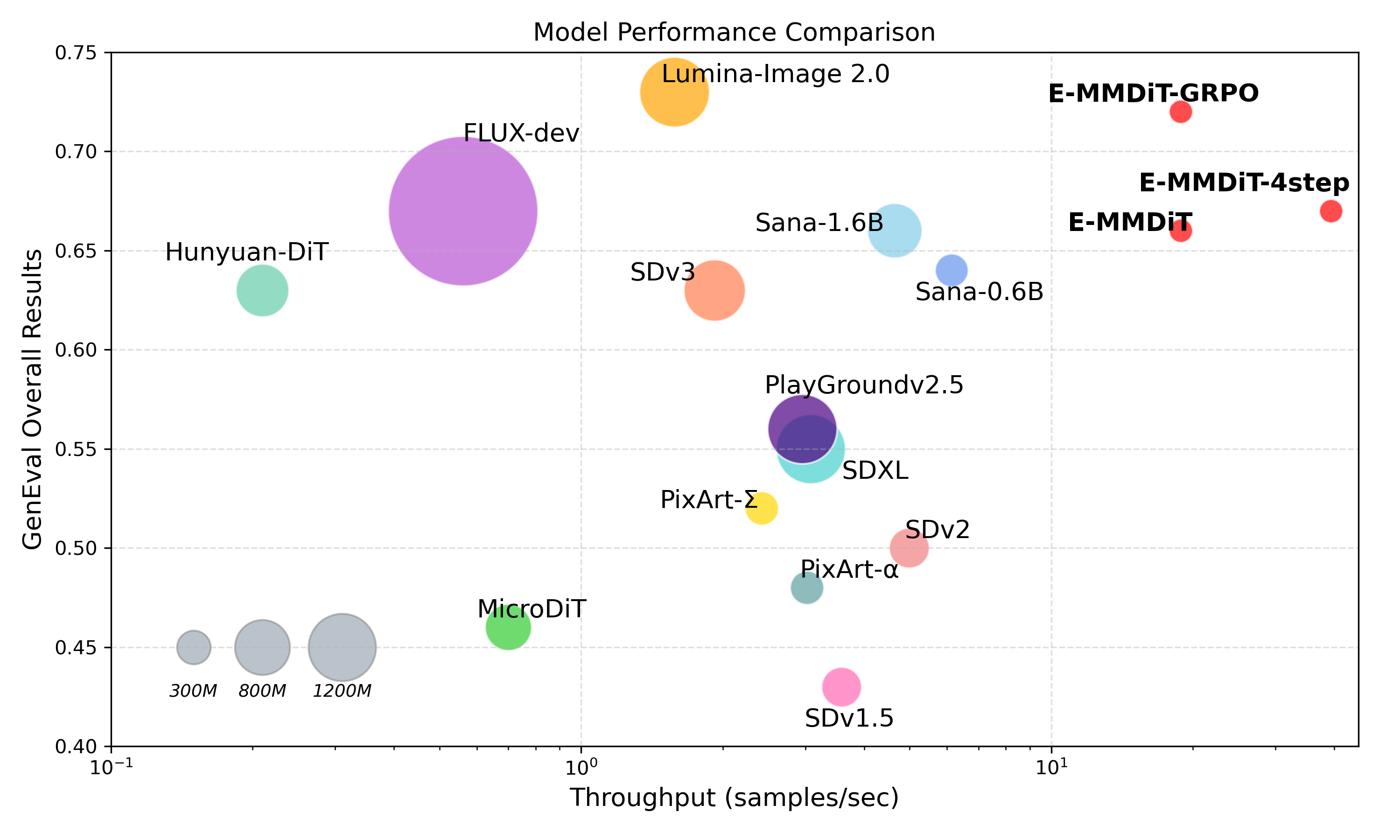
Figure 1. Comparison with other models on GenEval and throughput.#
Nitro-E Model#
AMD previously released Nitro-1 and Nitro-T for fast inference and efficient training. Here we explore a novel efficient model architecture termed E-MMDiT, which is what E in Nitro-E stands for. Nitro-T provides two variants based on two architectures DiT and MMDiT. The E-MMDiT is an improved MMDiT architecture with some novel designs (shown in Figure 2). We provide more details in the following sections.
Key Takeaways:
Low Training cost: Only 304M parameters, with training completed in just 1.5 days on a single node of 8 Instinct™ MI300X GPUs.
Deployment-friendly: Our model is highly lightweight, generating a 512 px image on a consumer-grade Strix Halo iGPU in just 0.16 seconds.
Fully supported by AMD ROCm™ Software.
Open & reproducible: Trained from scratch entirely on public datasets, with full training code and pre-trained weights available on Hugging Face.
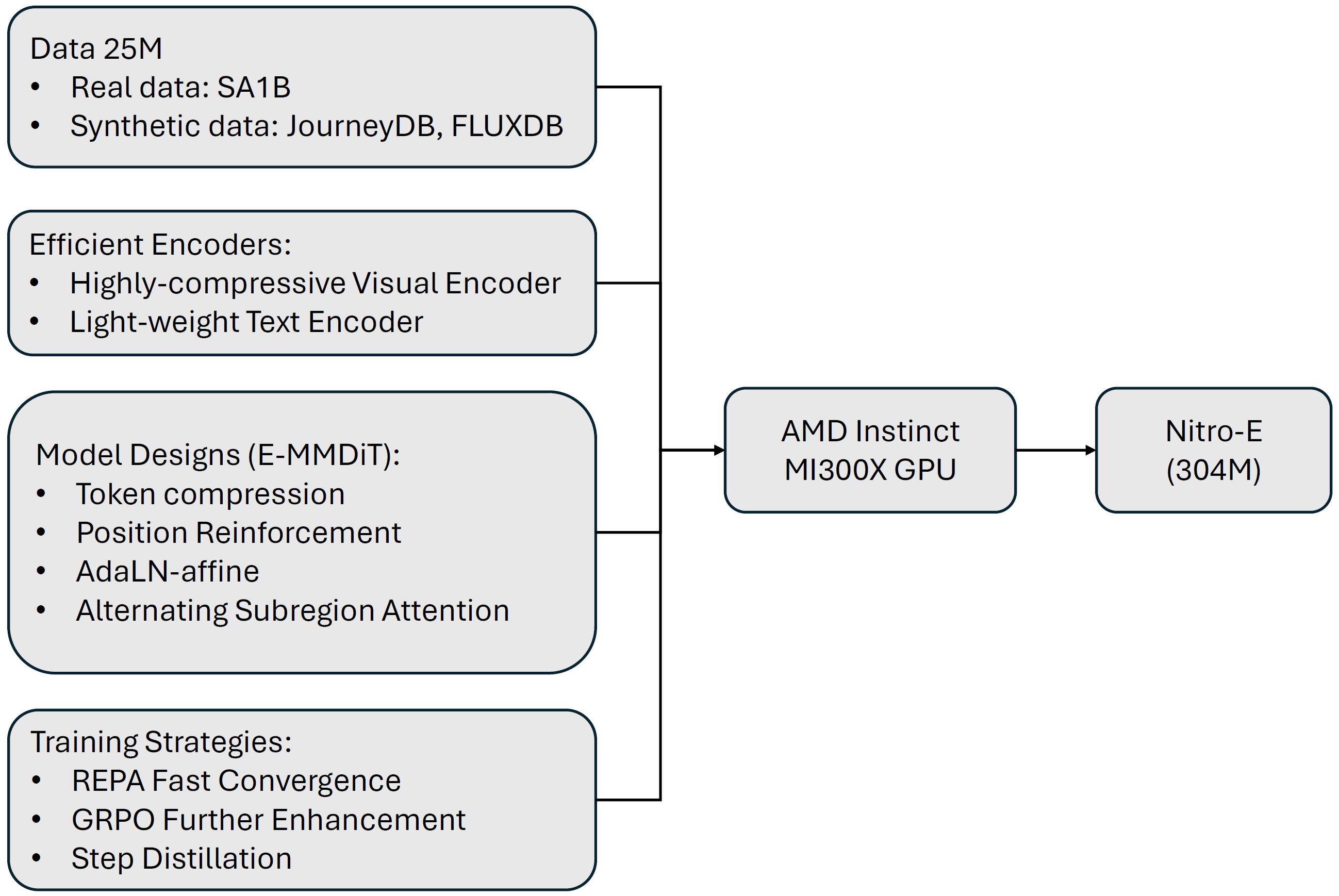
Figure 2. The Nitro-E model is achieved through multiple important design choices, which are listed in the figure.#
Efficient Encoders#
For both the visual and text encoder, we follow the designs of Nitro-T. Specifically, we use a highly compressive visual encoder, DC-AE [1] and a lightweight LLM, Llama 3.2 1B, as the text encoder. The DC-AE provides a much more compact representation, with a downsampling ratio of 32x. This largely reduces the image tokens, a key factor in improving efficiency. Meanwhile, for the text encoder, compared with the widely used T5 with 4.7B parameters, Llama 3.2 1B is far more cost-efficient and deployment-friendly, while still providing sufficient capability to understand prompts.
Model Designs (E-MMDiT)#
Our architecture, E-MMDiT, builds upon MMDiT [2], a variant of the Diffusion Transformer (DiT) [3] designed for handling multi-modality. MMDiT uses separate sets of weights for processing different modalities and fuses features through a joint attention mechanism in a unified framework. E-MMDiT extends MMDiT with several novel designs, described in detail in the following sections.
Token Compression#
Visual information is highly redundant, even with the highly compressive visual encoder. We found that further compressing image tokens can boost efficiency. To this end, we propose a novel multi-path compression module that compresses tokens using two ratios, 2x and 4x. The two sets of tokens are jointly processed by the subsequent blocks and finally recovered by the reconstructor. This approach reduces the number of visual tokens in transformer blocks by 68.5%, resulting in both training and inference being more efficient.
Position Reinforcement#
Positional Embeddings (PE) are crucial for transformers, as they encode each token’s spatial information in the image. However, the process of compression and reconstruction in the multi-path module can weaken or distort this positional information. To alleviate this, we introduce Positional Reinforcement, which explicitly re-attaches positional information to the reconstructed tokens. Experiments have shown that this strategy helps maintain spatial coherence and improve quality.
AdaLN-affine#
Adaptive LayerNorm (AdaLN) layers are essential for computing modulation parameters in each transformer block, but their linear projections contribute substantially to total parameters. Previous work [4] proposed AdaLN-single, which saves the computation and reduces the parameters by having a global vector as reference and only adding a bias term as trainable parameters for each block to get block-specific modulation parameters. Building on this, our AdaLN-affine reinforces the adaptability of the layers by adding a scale term, making it an affine transformation. This addition brings negligible cost while offering more flexibility for block-specific modulation.
Alternating Subregion Attention#
Attention is the core mechanism in transformers, enabling interactions between tokens. However, this operation is expensive due to its quadratic complexity with respect to the token count. We propose a simple, yet effective design called Alternating Subregion Attention (ASA), where tokens are divided into subgroups for computing attention in parallel to avoid full attention. To maintain inter-region communication, grouping patterns are alternated across blocks, preventing them from being restricted to fixed regions.
Training Strategies#
REPA#
Following Nitro-T, we also incorporate Representation Alignment (REPA) [5] in our training process. REPA aligns the intermediate features of the diffusion model with those from a pretrained vision model, such as DINO v2 [6]. This auxiliary objective helps the model learn faster and effectively accelerates convergence.
GRPO#
To further enhance generation quality, we also adopt Group Relative Policy Optimization (GRPO) [7] as a post-training strategy. It is a reinforcement learning technique to align the model with a desired generation preference defined by some rewards, for example, GenEval for image-text alignment, or HPSv2.1 for human preference performance. The basic idea is that given a prompt, we generate a group of candidate samples using the model and update the model to be closer to those desired samples determined by the rewards. An additional regularizer ensures the updated model stays close to the original reference model, maintaining stability.
Few-step Distillation#
To further accelerate inference speed, we perform step distillation following Nitro-1. By aligning the generation distribution of the teacher model and the student model using adversarial training, we can clearly reduce the inference steps from 20 to 4 while retaining similar performance. This distillation process does not involve extra data, where only synthetic data is required, which is generated by the teacher model.
Experiments#
Data#
We curated a dataset of 25M images containing both real and synthetic images. The details are described in Table 1. All the data are publicly available without any internal private data.
Source |
Number of Images |
Type of Images |
Generation Method |
|---|---|---|---|
Segment Anything 1B (SA1B) |
11.1M |
Real |
Real images annotated via LLaVA |
JourneyDB |
4.4M |
Synthetic |
Midjourney generated images |
FLUXDB |
9.5M |
Synthetic |
Generated using FLUX.1-dev with prompts from DataComp |
Table 1. Details of our training data. It consists of a mix of real and synthetic images and captions totaling 25M text-image pairs.
Implementation Details#
Our experiments are conducted using the PyTorch for ROCm training Docker image [8], which provides an optimized PyTorch environment for training models on AMD Instinct™ MI325X and MI300X accelerators. Our implementation is built on the training engine Accelerate with mixed precision training using the Bfloat16 datatype. Leveraging the large memory capacity of MI300X, we train the model with a batch size of 2048 using the native distributed data parallel.
Training Strategy
Stage 1 – REPA Pretraining The model is trained for 100k iterations using the full data as well as the REPA loss for accelerating convergence.
Stage 2 – High-Quality Data Fine-tuning We removed the SA1B dataset and finetune the model only on high-quality data for 50k iterations. Exponential Moving Average (EMA) is enabled for more stable convergence.
Optional Stage – Post-training with GRPO This optional phase applies GRPO for 2k iterations, optimizing the model with a combined reward from GenEval and HPSv2.1 to improve text-image alignment and human preference scores.
Optional Stage – Step Distillation This is also an optional phase where we distill the model to a 4-step model using a combined loss of adversarial loss and diffusion loss. The discriminator is composed of a feature extractor initialized by the same E-MMDiT model with frozen parameters and a prediction head that is randomly initialized. It is trained for 20k iterations.
For metrics, we adopt four widely used benchmarks:
ImageReward and HPSv2.1 measure human preference quality.
Results#
We compare our model with some popular open-sourced diffusion models, as shown in Table 2. For fair comparison, we divide the models into two groups based on their model size and inference cost. Our model achieves competitive results on all four metrics in the group of light-weight models and is comparable to those of larger models. More importantly, our models achieve much larger throughput outperforming other models by a large margin, which shows great potential for deployment on devices or in real-time applications. Last but not least, our model is trained solely on public datasets, which makes it easily reproducible and thus becomes a solid baseline for future development. Some visual results are shown in Figure 3.
| Methods | Throughput (samples/s) |
Latency (ms) |
Parameters Main network (M) |
TFLOPs Main network |
Dataset Size (M) |
GenEval↑ | IR↑ | HPS↑ | DPG↑ | |||||
| Large-scale Models | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SDXL | 3.08 | 1036 | 2567 | 1.59 | - | 0.55 | 0.69 | 30.64 | 74.70 | |||||
| SDv3 | 1.92 | 819 | 2028 | 2.11 | 1000 | 0.63 | 0.87 | 31.53 | 84.10 | |||||
| Sana-1.6B | 4.64 | 435 | 1604 | 0.84 | 50 | 0.66 | 1.04 | 27.41 | 85.50 | |||||
| MicroDiT | 0.70 | 1849 | 1160 | 1.13 | 37 | 0.46 | 0.81 | 27.23 | 72.90 | |||||
| FLUX-dev | 0.56 | 2943 | 11901 | 21.50 | - | 0.67 | 0.82 | 32.47 | 84.00 | |||||
| Lumina-Image 2.0 | 1.58 | 1243 | 2610 | 4.99 | 110 | 0.73 | 0.69 | 29.53 | 87.20 | |||||
| Hunyuan-DiT | 0.21 | 5356 | 1500 | 14.37 | - | 0.63 | 0.92 | 30.22 | 78.90 | |||||
| PlayGroundv2.5 | 2.95 | 1126 | 2567 | 1.58 | - | 0.56 | 1.09 | 32.38 | 75.50 | |||||
| Light-weight Models | ||||||||||||||
| SDv1.5 | 3.58 | 642 | 860 | 0.80 | 2000 | 0.43 | 0.19 | 24.24 | 63.18 | |||||
| SDv2 | 4.98 | 498 | 866 | 0.80 | 3900 | 0.50 | 0.29 | 26.38 | 64.20 | |||||
| PixArt-α | 3.02 | 625 | 610 | 1.24 | 25 | 0.48 | 0.92 | 29.95 | 71.60 | |||||
| PixArt-Σ | 2.42 | 668 | 610 | 1.24 | 33 | 0.52 | 0.97 | 30.37 | 80.50 | |||||
| Sana-0.6B | 6.13 | 424 | 592 | 0.32 | 50 | 0.64 | 0.93 | 27.22 | 84.30 | |||||
| E-MMDiT | 18.83 | 398 | 304 | 0.08 | 25 | 0.66 | 0.97 | 29.82 | 81.60 | |||||
| E-MMDiT-GRPO | 18.83 | 398 | 304 | 0.08 | 25 | 0.72 | 0.97 | 29.82 | 82.04 | |||||
| E-MMDiT-4step | 39.36 | 99 | 304 | 0.08 | 25 | 0.67 | 0.99 | 30.18 | 78.77 | |||||
Table 2. Comparison of our Nitro-E with other diffusion models.
More Visual Examples#

Figure 3. Images generated by Nitro-E.#
Summary#
In this blog post, we present an efficient model Nitro-E with only 304M parameters for diffusion image generation. Together with the latest ROCm software stack on AMD InstinctTM MI300X GPUs, we train our model from scratch with only 1.5 GPU days on a single machine with 8 GPUs, demonstrating efficiency and low cost of our model. In addition, our training data are all collected from the public datasets, making it easily reproducible, and we hope it can serve as a solid baseline and help advance the field.
Resources#
Model: amd/Nitro-E · HuggingFace
Code: AMD-AIG-AIMA/Nitro-E
Related Work from AMD team:
AMD Nitro Diffusion: One-Step Text-to-Image Generation Models
Nitro-T: Training a Text-to-Image Diffusion Model from Scratch in 1 Day — ROCm Blogs
Other useful Links
Use the public PyTorch ROCm Docker images that enable optimized training performance out-of-the-box.
PyTorch Fully Sharded Data Parallel (FSDP) on AMD GPUs with ROCm — ROCm Blogs
Accelerating Large Language Models with Flash Attention on AMD GPUs — ROCm Blogs
Accelerate PyTorch Models using torch.compile on AMD GPUs with ROCm — ROCm Blogs
References#
Chen, J., et al. Deep Compression Autoencoder for Efficient High-Resolution Diffusion Models. arXiv, 2025.
Esser, P., et al. Scaling Rectified Flow Transformers for High-Resolution Image Synthesis. arXiv, 2024.
Xie, S., Peebles, W., & Xie, S. Scalable Diffusion Models with Transformers. arXiv, 2022.
Li, J., et al. PixArt-α: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis. arXiv, 2023.
Yu, S., et al. Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think. ICLR, 2025.
Oquab, M., et al. DINOv2: Learning Robust Visual Features without Supervision. arXiv, 2023.
Guo, H., et al. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv, 2024.
System Configuration#
Our testbed system was configured with an AMD Instinct™ MI300X GPU running tests done by AMD on 05/17/2025, results may vary based on configuration, usage, software version, and optimizations.
AMD Instinct™ MI300X platform System Model: Supermicro AS-8125GS-TNMR2 CPU: 2x AMD EPYC 9575F 64-Core Processor NUMA: 1 NUMA node per socket. NUMA auto-balancing disabled Memory: 2304 GiB (24 DIMMs x 96 GiB Micron Technology MTC40F204WS1RC48BB1 DDR5 4800 MT/s) Disk: 16,092 GiB (4x SAMSUNG MZQL23T8HCLS-00A07 3576 GiB, 2x SAMSUNG MZ1L2960HCJR-00A07 894 GiB) GPU: 8x AMD Instinct MI300X 192GB HBM3 750W Host OS: Ubuntu 22.04.4 System BIOS: 3.5 System Bios Vendor: American Megatrends International, LLC. Host GPU Driver: (amdgpu version): ROCm 6.3.4 Docker image: rocm/pytorch-training:v25.5
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.