QuickReduce: Up to 3x Faster All-reduce for vLLM and SGLang#

Advancements in large-scale language models (LLMs) have led to significant performance breakthroughs across various domains, especially in natural language processing. LLMs typically consist of billions of parameters, resulting in substantial computational, storage, and deployment challenges. Inter-GPU communication overhead often emerges as a key bottleneck limiting overall system performance. In tensor-parallel setups, every layer requires frequent all-reduce operations—synchronizing large amounts of data across GPUs. This introduces significant latency and strains interconnect bandwidth.
In this blog, we’re going to explore QuickReduce, a high-performance all-reduce library designed for AMD ROCm™ to boost LLM inference. We’ll break down why all-reduce communication is such a critical bottleneck in multi-GPU setups, how QuickReduce leverages inline compression and kernels to achieve up to 3× speedups on AMD Instinct™ MI300X GPUs, and how you can seamlessly integrate it into vLLM and SGLang without modifying a single line of code. We’ll share performance benchmarks, accuracy results, and practical tips for tuning quantization levels to get the best balance between throughput and model fidelity.
QuickReduce - A Faster All-reduce#
All-reduce stands out as one of the most critical communication patterns. It synchronizes data across multiple GPUs by aggregating (e.g., summing) values from all participating devices and broadcasting the result back to each one. Due to its central role in both distributed training and inference, all-reduce has become a major focus in the design and optimization of multi-GPU distributed systems.
QuickReduce is a performant all-reduce library designed for AMD ROCm that supports inline compression and kernel. The compression and decompression of data are performed directly within the thread-level data exchanges of the all-reduce kernel, rather than quantizing all the data upfront. The library implements an all-reduce algorithm using hardware-optimized kernels that leverage powerful CDNA3 vector instructions for fast compression and decompression, interleaving compute with network/memory access.
It supports the following small-block compression methods:
FP16: Vanilla FP16 for reference.
FP8: FP8 quantization with block size of 32.
Q8: 8-bit integer quantization with block size of 32.
Q6: 6-bit integer quantization with block size of 32.
Q4: 4-bit integer quantization with block size of 32.
These compression methods help reduce memory usage and communication bandwidth during all-reduce operations. FP16 preserves the original data format, FP8 uses a floating-point format, while Q8, Q6, and Q4 are integer-based quantization schemes. Each block contains 32 elements, allowing finer-grained compression and better thread load balancing.
For example, as shown in figure 1, consider 8 MB of FP16 data (A0) to be communicated from gpu0 to gpu1. Using the Q4 scheme, the original FP16 data is quantized into int4 by sharing a single scaling factor for every 32 values. As a result, the 8 MB of FP16 data is reduced to 2.25 MB—2 MB for the quantized data and 256 KB for the scaling factors.
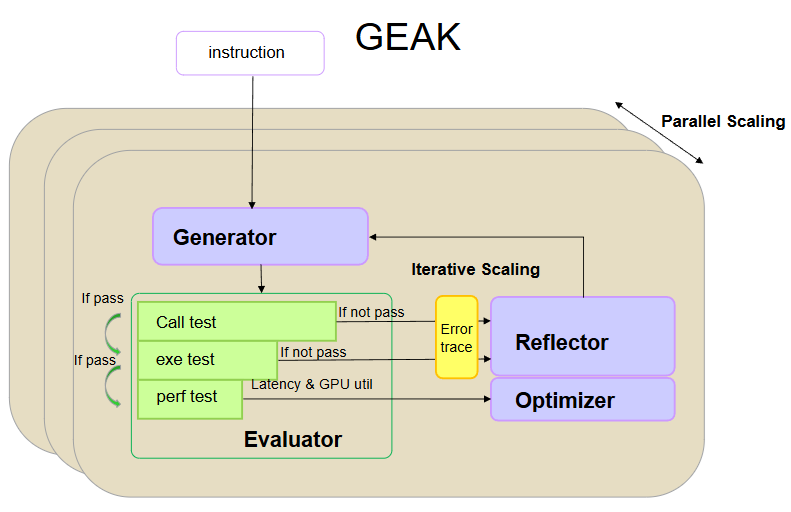
Figure 1. Quantization reduces the amount of data transmitted.#
QuickReduce Design#
QuickReduce adopts the TwoShot algorithm, a two-phase all-reduce method. In the first phase, each GPU sends partial data to a designated reducer; in the second, the reduced result is broadcast back to all GPUs. Compared to the OneShot algorithm—which merges reduction and broadcast in a single step and performs well at small scales—TwoShot delivers superior performance at larger world sizes by reducing overall network traffic. Inline compression further enhances efficiency. Although quantization and dequantization add overhead, they can be overlapped with network communication, hiding much of the cost and improving throughput.
The kernel is organized such that each thread works on 128B worth of data (i.e. 64 FP16 values), with each workgroup of 256 threads working on 32KB of the problem. The codec implementations use packed math instructions (e.g., v_pk_max_f16, v_cvt_pkrtz_f16_f32) and intrinsics to churn through the data with as few instructions as possible. All memory accesses attempt to use the widest possible 128b/thread vector read/write with exceptions when storing quantized shards of the block data.
The core steps when the TwoShot kernel of QuickReduce is run are as shown in Figure 2:
Split & Send – Each rank partitions its local data and transmits fragments to corresponding peers, with quantization applied before sending. (Network communication)
Local Reduction – Each rank dequantizes incoming data, then reduces it into partial sums. (Local compute)
Broadcast Partial Sum – Partial results are quantized and sent to all ranks. (Network communication)
Assemble Output – Ranks dequantize the received data and reconstruct the final result. (Local compute)
Figure 2. Twoshot QuickReduce Process (Example: TP=4)#
Integrating QuickReduce into vLLM and SGLang#
vLLM and SGLang are high-performance inference engines for LLMs, optimized for throughput, memory efficiency, and low latency. QuickReduce has been fully integrated into both vLLM[1] and SGLang[2] on AMD ROCm.
You don’t need to change any vLLM or SGLang commands—just set the right environment variable to turn on QuickReduce.
For vLLM: export VLLM_ROCM_QUICK_REDUCE_QUANTIZATION=[FP|INT8|INT6|INT4]
For SGLang: export ROCM_QUICK_REDUCE_QUANTIZATION=[FP|INT8|INT6|INT4]
Use vLLM as an example to illustrate the usage:
vLLM server launch command
VLLM_ROCM_QUICK_REDUCE_QUANTIZATION=INT4
vLLM serve /model_path/Qwen/Qwen2.5-72B \
--no-enable-prefix-caching \
--block_size=32 \
--disable-log-requests
vLLM client benchmark command
python /app/vllm/benchmarks/benchmark_serving.py \
--model /model_path/Qwen/Qwen2.5-72B \
--dataset-name random \
--num-prompts 500 \
--request-rate 10 \
--ignore-eos
We have selected Q8, Q6, and Q4 as the supported quantization schemes, considering acceleration performance, accuracy impact, and compilation issues. Additionally, QuickReduce originally supported only fp16 inputs. We extended it to support bfloat16 (bf16) as well.
Currently, on the AMD Instinct GPUs, vLLM and SGLang employ a custom all-reduce implementation for data sizes smaller than 16 MB, which is optimized for small-message efficiency. For data sizes larger than 16 MB, it falls back to using PyNccl (RCCL) for all-reduce operations.
Based on the following kernel benchmark results, QuickReduce is not the fastest option for small data sizes (below 2 MB). Therefore, in vLLM and SGLang, we implemented an adaptive algorithm that automatically selects the fastest among custom all-reduce, RCCL, and QuickReduce based on the communication volume.
QuickReduce Performance Insights#
Let’s take a deep dive into performance insights for Quickreduce across different parameters.
Performance Insights for Kernel Test#
The all-reduce implementations in vLLM and SGLang are nearly identical, we will focus on vLLM for the discussion. Figures 3, 4, and 5 present the speedup from QuickReduce under various quantization strategies and data sizes (in bytes). The results show that as parallelism decreases, QuickReduce delivers greater acceleration. Since all three figures share the same structure, we use Figure 3 as a representative example.
In vLLM, the baseline is defined as the faster result between the custom all-reduce and PyNccl all-reduce, shown as a straight line at value 1. “Fp16” and “bf16” indicate runs with QuickReduce but without quantization—keeping the original data type. “Fp16 to int8” represents the Q8 quantization scheme, where fp16 data is quantized to int8 before communication. For any given data size, a line above the baseline means QuickReduce provides acceleration; a line below means it performs worse, in which case QuickReduce is disabled. “Best_allreduce” refers to the aggregated approach that automatically picks the most efficient all-reduce method for different data sizes, and it serves as the foundation for vLLM’s adaptive all-reduce mechanism.
Figure 3: Speedup with tensor parallelism (Tp) = 2
Figure 4: Speedup with tensor parallelism (Tp) = 4
Figure 5: Speedup with tensor parallelism (Tp) = 8
Figure 3. Speedup achieved by QuickReduce under different data sizes with tp=2.[3]#
Figure 4. Speedup achieved by QuickReduce under different data sizes with tp=4.[3]#
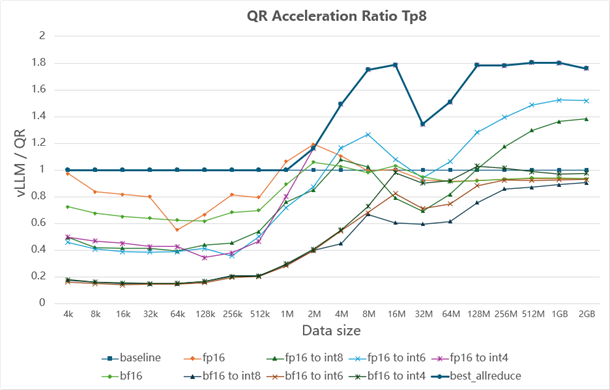
Figure 5. Speedup achieved by QuickReduce under different data sizes with tp=8.[3]#
In subsequent classical model experiments, where bfloat16-to-float16 conversion was enabled, QuickReduce demonstrated notable performance gains.
Performance Insight for End-to-End Test & Accuracy Test#
End-to-end (E2E) testing is used to validate the complete workflow of a system from start to finish. We use E2E tests to ensure that QuickReduce functions correctly across all components, modules, and interfaces in real-world scenarios, while also collecting the program’s execution time.
End to end test command:
For vLLM
Server: VLLM_ROCM_QUICK_REDUCE_QUANTIZATION=$Q_level VLLM_USE_V1=1 VLLM_USE_TRITON_FLASH_ATTN=0 vllm serve model_path --block_size=32 --disable-log-requests --no-enable-prefix-caching -tp $tp --dtype auto
Client: python benchmarks/benchmark_serving.py --model model_path --dataset-name sonnet --dataset-path benchmarks/sonnet.txt --num-prompts 500--request-rate 10 --ignore-eos
For SGLang
Server: ROCM_QUICK_REDUCE_QUANTIZATION=$Q_level python -m sglang.launch_server --model-path $model_path --tp-size $tp --port $port --disable-radix-cache
Client: python3 -m sglang.bench_serving --backend sglang --num-prompt 200 --port $port
QuickReduce employs quantization to compress data, which introduces some loss of precision. We conduct experiments to verify that this loss remains within acceptable limits.
Accuracy test command:
For vLLM
lm_eval --model vllm --model_args pretrained=$model_path,add_bos_token=True,tensor_parallel_size=$tp,gpu_memory_utilization=0.9 --tasks gsm8k --num_fewshot 5 --batch_size auto --limit 250 --seed 1
For SGLang
Server: ROCM_QUICK_REDUCE_QUANTIZATION= $Q_level python -m sglang.launch_server --model-path $model_path --tp-size $tp --port $port --disable-radix-cache
Client: python3 sglang/benchmark/gsm8k/bench_sglang.py --port $port --num-questions 400
We selected Llama-3.1-8B-Instruct, Llama-3.1-70B, Qwen2.5-72B-Instruct, and Llama-2-70B-hf as test models to cover a diverse range of parameter sizes and data types. During inference, we measured TTFT (Time to First Token), TPOT (Tokens Per Output Time), and ITL (Inter-Token Latency) under varying degrees of parallelism and different QuickReduce quantization schemes [3]. Each configuration was evaluated multiple times to ensure fairness.
We used GSM8K as the accuracy metric. GSM8K (Grade School Math 8K) is a benchmark containing roughly 8,500 grade-school-level math word problems that require multi-step reasoning. Accuracy is evaluated via exact match between the model’s predicted final answer and the actual output, with high scores indicating stronger reasoning capability and overall precision.
The results demonstrate that using QuickReduce in vLLM and SGLang significantly improves performance across the tested models. With the QuickReduce Q4, TTFT can be accelerated by over 1.2×, and for vLLM at a parallelism degree of 2, speedup can exceed 3×. More details on the performance insights numbers are in Endnotes 1 and 2. Accuracy tests show that most models experience no meaningful drop in performance, and in some cases, slight improvements are observed—consistent with expectations when applying activation quantization in LLMs.
Summary#
This blog not only introduced QuickReduce as a solution for overcoming all-reduce bottlenecks but also demonstrated its impact through benchmarks, integration workflows, and accuracy validation. QuickReduce enables you to accelerate LLM inference on AMD ROCm with zero code changes. Simply enable it in vLLM or SGLang, experiment with FP16, BF16, or INT4/6/8 quantization, and benchmark your models to find the optimal speed-accuracy trade-off. Integrate QuickReduce into production on MI300X GPUs to achieve higher throughput, lower latency, and efficient scaling for large-scale LLM deployments.
Acknowledgements#
This blog post summarizes efforts from several members of the AMD Quark team. We would like to express our thanks to the AMD Quark team members.
Endnotes#
[1] Integrate QuickReduce into vLLM
[2] Integrate QuickReduce into SGLang
[3] Configuration details
On average, results were obtained using a system configured with an AMD Instinct™ MI300X GPU. Tests for vLLM were conducted by AMD on July 10, 2025, while tests for SGLang were conducted on July 22, 2025. Actual results may vary depending on system configuration, usage, software version, and applied optimizations.
Software Setup for vLLM:
Base image: rocm/vllm-dev:nightly_main_20250607 HIPBLASLT_BRANCH: aa0bda7b TRITON_BRANCH: 3.2.0+gite5be006a TRITON_REPO: https://github.com/triton-lang/triton.git PYTORCH_BRANCH:2.7.0a0+git295f2ed PYTORCH_REPO: https://github.com/ROCm/pytorch.git PYTORCH_VISION_BRANCH:0.21.0+7af6987 PYTORCH_VISION_REPO: https://github.com/pytorch/vision.git AITER_BRANCH: 0.1.0 AITER_REPO: https://github.com/ROCm/aiter.git VLLM_BRANCH: 0.8.5.dev1652+ga7bab0c9e.d20250717.rocm641 VLLM_REPO: vllm-project/vllm: A high-throughput and memory-efficient inference and serving engine for LLMs Software Setup for SGLang: Base image: rocm/sgl-dev:20250525 HIPBLASLT_BRANCH: 0.13.0-15222f77 TRITON_BRANCH: 3.2.0+gitcddf0fc3 TRITON_REPO: https://github.com/triton-lang/triton.git PYTORCH_BRANCH: 2.6.0a0+git8d4926e PYTORCH_REPO: https://github.com/ROCm/pytorch.git PYTORCH_VISION_BRANCH: 0.19.1a0+6194369 PYTORCH_VISION_REPO: https://github.com/pytorch/vision.git AITER_BRANCH: 0.1.2 AITER_REPO: https://github.com/ROCm/aiter.git SGLANG_BRANCH: main+429bb0ef+(Integrate QuickReduce into SGLang) SGLANG_REPO: sgl-project/sglang: SGLang is a fast serving framework for large language models and vision language models. SYSTEM CONFIGURATION: AMD Instinct ™ MI300X platform System Model: Supermicro AS-8125GS-TNMR2 CPU: 2x AMD EPYC 9554 64-Core Processor NUMA: 2 NUMA node(s), 1 NUMA node per socket. NUMA auto-balancing disabled Memory: 1536 GiB (24 DIMMs x 64 GiB Micron Technology MTC40F2046S1RC48BA1 DDR5 4800 MT/s) Disk: 53.76 TB (7x INTEL SSDPF2KX076T 7.68 TB) GPU: 8x AMD Instinct MI300X 192GB HBM3 750W Host OS: Ubuntu 22.04.5 LTS System BIOS: 3.6 System Bios Vendor: American Megatrends International, LLC Host GPU Driver: (amdgpu version): ROCm 6.3.1
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.