
Ashish Sirasao#
ASHISH SIRASAO is a Corporate Vice President at AMD. His research interests include hardware–software co-design, programming paradigms for domain-specific accelerators, and deep-learning algorithms. He received his M.Tech degree in electrical engineering from IIT Mumbai.
Posts by Ashish Sirasao

Serving NVFP4 Models on AMD Instinct™ MI355 Accelerators
Learn how to serve NVFP4 models on AMD Instinct™ MI355 using an emulation pipeline in vLLM — no format conversion needed.

QuickReduce INT3 Quantization and Benchmarking on MI355
Learn how QuickReduce uses INT3 quantization to accelerate all-reduce communication and evaluate its performance and accuracy on AMD Instinct MI355 GPUs.

Accelerating Diffusers and xDiT Image Generation with MXFP4 using AMD Quark on AMD Instinct™ MI350 GPUs
Accelerate Diffusers and xDiT FLUX.1-dev image generation on AMD Instinct MI350 GPUs using AMD Quark MXFP4 quantization.

Accelerating Large-Scale LLM Inference on AMD Instinct MI350X/MI355X with Eagle3 and AMD Quark
Learn how the AMD Quark team enables Eagle3 speculative decoding for Kimi-K2.5 and MiniMax-M2.5 on AMD Instinct MI355X GPUs with ROCm, vLLM, and InferenceX.

MXFP6 and MXFP4 Mixed Precision for Accelerating Dense LLMs on AMD Instinct MI355X
W_MXFP4_A_MXFP6 quantization on AMD Instinct MI355X improves LLM throughput and latency while recovering accuracy versus MXFP4.

Low Kruskal-Rank Adaptation
Learn how Kruskal rank can enhance LoRA by replacing the conventional matrix-rank formulation for more efficient training.

Productionizing TurboQuant on AMD GPUs for KV-Cache-Bound LLM Inference
Productionized TurboQuant 4-bit KV-cache quantization on AMD GPUs via vLLM, with custom kernels and accuracy analysis on agentic workloads.

QuickReduce FP4 Quantization and Benchmarking on MI355
Learn how QuickReduce uses FP4 quantization to accelerate all-reduce communication and evaluate its performance on AMD Instinct MI355 GPUs.

Programming Tensor Descriptors in Composable Kernel (CK)
Learn how to use TensorDescriptor in Composable Kernel (CK) to manage multi-dimensional data layouts and write efficient GPU kernels on AMD GPUs.
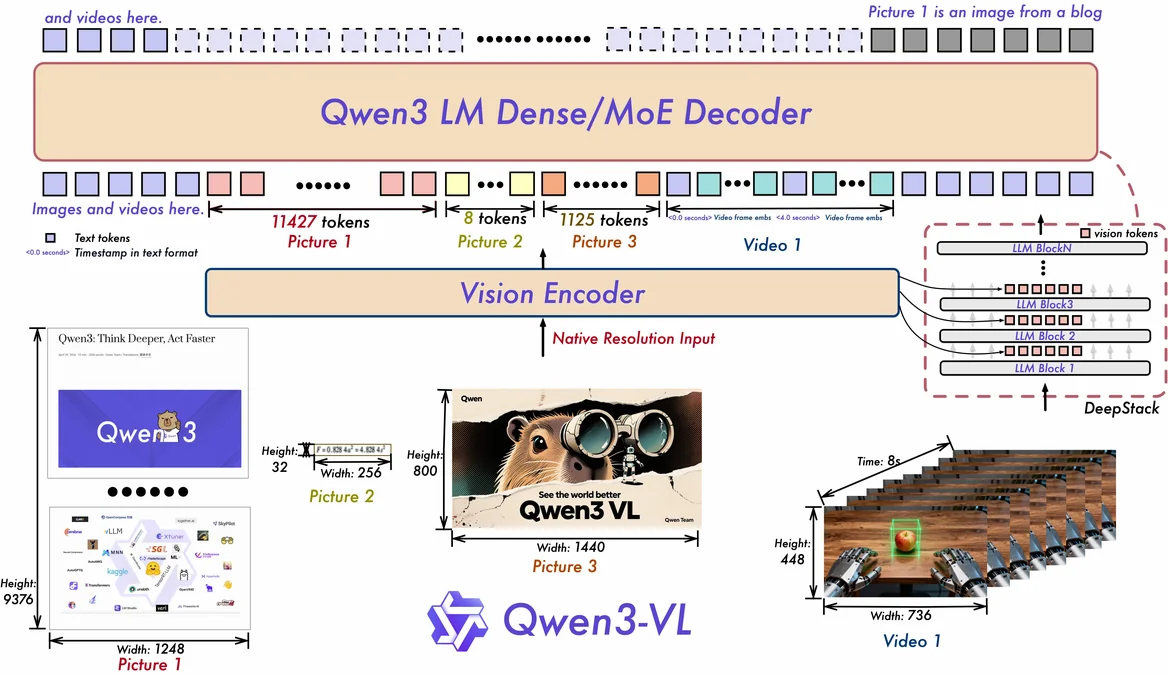
Engineering Qwen-VL for Production: Vision Module Architecture and Optimization Practices
Explore how to optimize Qwen-VL for production on AMD Instinct MI308X GPUs with ROCm, from vision module architecture to kernel fusion and deployment.

hipBLASLt Online GEMM Tuning
Learn how to improve model performance with hipBLASLt online tuning merged into LLM framework

Advanced MXFP4 Quantization: Combining Fine-Tuned Rotations with SmoothQuant for Near-Lossless Compression
Showcase advanced algorithms available in AMD Quark for efficient MXFP4 quantization on AMD Instinct accelerators with high accuracy retention.

Day 0 Developer Guide: hipBLASLt Offline GEMM Tuning Script
Learn how to improve model performance with hipBLASLt offline tuning in our easy-to-use Day 0 tool for developers to optimize GEMM efficiency

High-Accuracy MXFP4, MXFP6, and Mixed-Precision Models on AMD GPUs
Learn to leverage AMD Quark for efficient MXFP4/MXFP6 quantization on AMD Instinct accelerators with high accuracy retention.

QuickReduce: Up to 3x Faster All-reduce for vLLM and SGLang
Quick Reduce speeds up LLM inference on AMD Instinct™ MI300X GPUs with inline-compressed all-reduce, cutting comms overhead by up to 3×