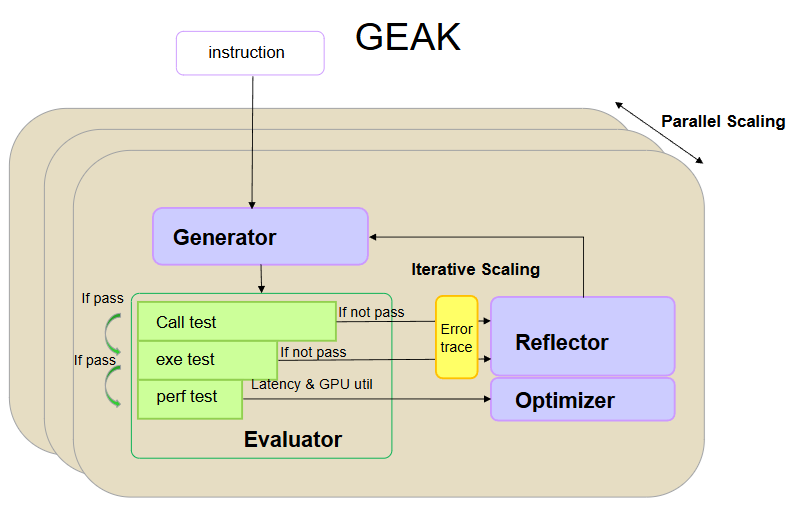
Gumiho: A New Paradigm for Speculative Decoding — Earlier Tokens in a Draft Sequence Matter More#

Speculative decoding has emerged as a promising approach to accelerate large language model (LLM) inference, yet existing methods face a tradeoff: parallel designs achieve higher speed but lose accuracy, while serial designs gain accuracy at the cost of efficiency. In our recent paper Gumiho: A Hybrid Architecture to Prioritize Early Tokens in Speculative Decoding, we introduce a new paradigm that addresses this bottleneck by prioritizing accuracy on the earliest draft tokens, which matters most for downstream acceptance. In this blog, we will discuss the motivation behind Gumiho, the theoretical foundation showing why early-token accuracy dominates, and the novel hybrid architecture that combines serial and parallel decoding to realize these insights. Our goal is to demonstrate both the scientific contributions and practical benefits of Gumiho, showing how it delivers state-of-the-art performance on AMD GPUs using the ROCm software stack, ensuring that the method is widely accessible and optimized for real-world deployment.
Crucially, Gumiho is co-designed with the AMD ROCm™ software stack to fully exploit the parallel compute capabilities of AMD Instinct™ GPUs. The parallel MLP heads in Gumiho are specifically optimized to leverage ROCm’s high-throughput tensor operations and memory bandwidth, enabling near-linear scaling when generating multiple draft tokens simultaneously. Meanwhile, the serial Transformer heads benefit from ROCm’s low-latency kernel execution for autoregressive steps. This hardware-aware design ensures that Gumiho not only achieves theoretical gains but also delivers real-world, production-ready acceleration on AMD’s open, standards-based AI ecosystem.
What Is Speculative Decoding (SPD)?#
Large-language models (LLMs) usually generate text in an auto-regressive fashion, emitting tokens one by one. This inherently limits throughput. Speculative Decoding (SPD) tackles this bottleneck losslessly by introducing a lightweight draft model that “guesses” a short future segment. The stronger—but slower—LLM then verifies that whole segment in parallel, accepting every token that matches its own prediction. When the acceptance rate is high, the amortised time per token drops sharply, yielding substantial speed-ups.
Core Theory – Early Tokens Are Crucial#
Because the verifier inspects the draft from left to right, the first mismatch causes that token and every subsequent one to be rejected. Consequently, an error early in the sequence has a much larger destructive effect than an error near the end.
To illustrate this more intuitively, we present a simple example: suppose the draft model predicts 3 tokens, and at each position the probability of being accepted by the target model is 0.8. Then the expected number of tokens accepted (τ) is:
Now let’s adjust the model’s “capability allocation” so that it focuses more on the first token, changing the acceptance probabilities at the three positions to 0.85, 0.8, and 0.75 (the sum of these remains the same as before). In this case, the expected number of accepted tokens (τ) becomes:
By simply boosting the accuracy of the earlier tokens a bit and lowering that of the later ones slightly, the overall expectation increases.
This example clearly shows that, when the model’s total capability budget (e.g., its “compute budget”) is fixed, tilting accuracy toward the front of the sequence—i.e., allocating more compute to the earliest tokens—yields a higher final payoff.
Furthermore, we propose the following theorem:
Theorem Under the improved probability distribution, the average number of accepted tokens per draft exceeds that under the original distribution.
We provide detailed proof of this theorem in Appendix A of our original paper. The theorem makes it explicit that, while keeping the overall acceptance probability unchanged, any reallocation of accuracy from later tokens to earlier ones will increase the average number of tokens accepted.
ROCm — Powering Gumiho’s Hybrid Acceleration#
All our experiments and benchmarks for Gumiho were conducted on AMD Instinct™ GPUs using the ROCm™ software stack, which plays a crucial role in realizing the architecture’s full potential. The parallel MLP heads in particular benefit greatly from ROCm’s highly optimized GPU runtime and compiler stack, which are designed to maximize fine-grained parallelism and memory bandwidth utilization. This allows Gumiho to execute parallel token predictions at scale with minimal latency overhead, while the serial transformer components also leverage ROCm’s advanced kernel scheduling to maintain high throughput. As a result, Gumiho is not just a theoretical improvement, it is engineered to deliver production-grade performance on ROCm-enabled systems, making it ideal for real-world deployment in enterprise and cloud-scale AI inference.
Gumiho — A Hybrid Architecture Prioritising Early Tokens#
Figure 1. Left: Differences between our proposed Gumiho and existing methods: Unlike existing approaches that use similar models to predict every token in a sequence, we propose that initial tokens are more critical than later ones. So we employ a larger model with a serial structure to generate the early tokens, while leveraging smaller parallel models for the later ones. Right: Overview of Gumiho. Given an LLM input Describe a beautiful scene., Gumiho predicts the next 7 draft tokens (sun rose above the mountains through the). The first two tokens (sun and rose) are deemed critical and are produced sequentially using the Transformer for higher accuracy. The remaining tokens are generated simultaneously through the MLP heads, optimizing for computational efficiency. Source: [4]#
As shown in Figure 1, to embody the theorem, Gumiho mixes a serial and a parallel module:
Serial Transformer (2 layers): It autoregressively generates the first two draft tokens, dedicating more parameters and computation where accuracy matters most.
Five Parallel MLP Heads: Sharing the Transformer’s outputs as input, they predict the remaining five tokens concurrently, maximizing efficiency.
This asymmetric resource allocation yields higher τ while cutting wall-clock draft time, striking a better accuracy/efficiency balance than single-mode designs.
Full Tree Attention (FTA)#
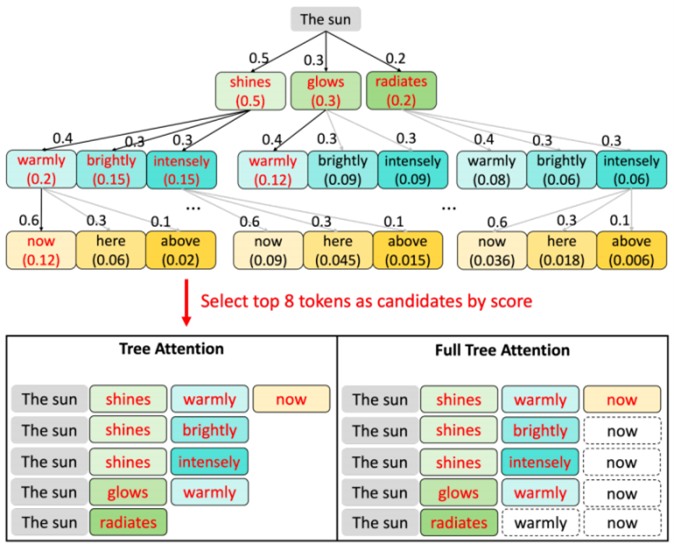
Figure 2. Our proposed Full Tree Attention enhances shorter candidate paths by borrowing tokens from other tree nodes, thereby increasing the likelihood that candidates achieve longer acceptance lengths. Source: [4]#
Serial methods such as Eagle-2 build a candidate tree but often select many very short paths because high-score tokens accumulate early. Gumiho’s parallel heads are mutually independent, letting us freely recombine their tokens, as shown in Figure 2. FTA therefore “borrows” tokens from deeper, higher-score paths to extend shorter candidates for free—all queries, keys and values have already been computed. This zero-overhead augmentation raises average path length and thus τ.
Experimental Validation—SOTA Throughput#
Table 1. Speedup ratios and mean accepted tokens (τ) of different methods. V represents Vicuna, L2 represents LLaMA2-Chat, and L3 represents LLaMA3-Instruct. We present the results of different methods across six datasets. Mean represents the average performance across these six datasets. Source: [4]#
As shown in Table 1, across six benchmarks (dialogue, code generation, maths, general instructions, summarization, and QA) and nine target LLMs ranging from 7B to 70B parameters, Gumiho consistently outperforms Medusa, Hydra and Eagle-2. Overall speed-up gains over Eagle-2 lie between 4.5 % and 15.8 %, with the advantage growing for larger (70 B) models owing to more effective parallel-MLP amortization.
Summary#
In this blog, we rigorously prove that early-token accuracy dominates later-token accuracy in SPD, thereby justifying asymmetric resource allocation. Building on this theoretical foundation, the serial-plus-parallel Gumiho head design realizes this idea in practice and delivers state-of-the-art acceleration. Moreover, Full Tree Attention further enhances performance by recycling parallel-head outputs to lengthen candidates at zero extra cost, and thus further boosts speed-up ceilings. To learn more and experiment with Gumiho, please check out our ICML 2025 paper and try the open-source implementation on GitHub. Finally, we welcome researchers to explore Gumiho on AMD ROCm-enabled GPUs and to share feedback with the community.
References#
[1] Cai, T., Li, Y., Geng, Z., Peng, H., Lee, J. D., Chen, D., and Dao, T. Medusa: Simple llm inference acceleration framework with multiple decoding heads. arXiv preprint arXiv:2401.10774, 2024.
[2] Ankner, Z., Parthasarathy, R., Nrusimha, A., Rinard, C., Ragan-Kelley, J., and Brandon, W. Hydra: Sequentially dependent draft heads for medusa decoding. arXiv preprint arXiv:2402.05109, 2024.
[3] Li, Y., Wei, F., Zhang, C., and Zhang, H. Eagle-2: Faster inference of language models with dynamic draft trees. arXiv preprint arXiv:2406.16858, 2024b.
[4] Li, J., Xu, Y., Huang, H., Yin, X., Li, D., Ngai, E. C., & Barsoum, E. Gumiho: A Hybrid Architecture to Prioritize Early Tokens in Speculative Decoding. In Forty-second International Conference on Machine Learning.
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.