Avoiding LDS Bank Conflicts on AMD GPUs Using CK-Tile Framework#

LDS bank conflict is a common performance bottleneck in GPU kernel development. Composable Kernel (CK-Tile), a kernel development framework for AMD GPUs, provides a framework-level solution for LDS bank conflicts. Composable Kernel for ROCm is used to build portable high-performance kernels for accelerating computing, e.g. HPC, DL and LLMs for training and inference workloads. In this blog, we show you how to analyze, detect, and eliminate LDS bank conflicts using CK-Tile, AMD’s composable GPU kernel framework. A GEMM kernel serves as a classic example for analyzing how threads interact with LDS during both reads and writes. Starting with a naïve memory layout, we evaluate bank conflict behavior, explore mitigation techniques such as padding, and ultimately demonstrate how an XOR-based swizzle transformation achieves a bank conflict-free design.
What’s LDS and Bank Conflict#
Local Data Share (LDS) is a small but high-bandwidth memory region shared by all threads (also called work-items) within a workgroup on AMD GPUs. It acts like a programmable L1 cache, enabling fast and efficient data sharing among threads—crucial for performance in compute-heavy operations such as matrix multiplication, convolutions, and reductions.
On AMD MI-series GPUs, LDS is divided into 32 memory banks, each capable of handling a 4-byte access per LDS clock cycle. Ideally, each thread accesses a different bank, allowing full parallelism. However, if multiple threads try to access different addresses that map to the same memory bank, a bank conflict occurs. When this happens, the accesses must be serialized, which greatly reduces memory throughput and slows down performance.
Multiple threads access different addresses that fall into the same memory bank at the same time causing bank conflict. Bank conflicts most commonly arise when the memory access pattern uses a stride that’s a multiple of the number of banks. For instance, if 32 threads access memory with a stride of 32 elements, all will target bank 0, causing a 32-way conflict—a worst-case scenario that can significantly degrade kernel performance.
Problem Definition#
We are analyzing how Local Data Share (LDS) bank conflicts arise in a GEMM (General Matrix Multiply) kernel on AMD GPUs, and how different memory layouts and access patterns affect performance.
Let’s focus on
Understanding how matrix A (input to GEMM) is laid out in DRAM
Rules to check bank conflict
Let us consider a basic GEMM problem, with the key kernel configuration parameters:
kMPerBlock=64; kKPerBlock=32; kKPack 8
warpTile=16x16x32
BlockSize=256
mfma_fp32_16x16x32_fp16_fp16
Matrix Data Layout in DRAM#
Matrix A is stored in row-major layout in DRAM, which affects how it’s loaded into LDS. Each row is made up of 4 groups of 8 elements to align with 128-bit memory access. Matrix A is laid out in DRAM as [64 rows × 32 columns], stored row major. To align with kKPack, which is also well-aligned with 128-bit used as bank-group size, consider \([kMPerBlock, kKPerBlock] = [64, 32] = [64, 4*8]\), Each small box, as shown below in Figure 1, represents 8 contiguous elements with continuous indexes.
Figure 1. Element Layout in Matrix-A#
Bank Conflict Check Rule#
When working with AMD GPUs, it’s important to know how the threads access LDS memory as poor access patterns can lead to bank conflicts. With AMD MI GPUs, there are 64 lanes per Wavefront(warp), and 32 physical banks in LDS, each with 4Bytes access length. To fully occupy these 32 banks, different bank check rules are considered for different LDS read/write instructions. Let’s take ds_read_b128 and ds_write_b128 as examples here, as read/write in 128-bit is a common choice for efficiency.
ds_write_b128#
For ds_write_b128, when there is no bank conflict in 8 lane groups: lane0~lane7, lane8~lane15, lane16-lane23, lane24~lane31, lane32~lane39, lane40~lane47, lane48~lane55, lane56~lane63, then it is bank conflict-free for LDS writing.
ds_read_b128#
For ds_read_b128, when there is no bank conflict in these 8 lane groups: 0:3+20:23; 4:7+16:19; 8:11+28:31; 12:15+24:27; 32:35+52:55; 36:39+48:51; 40:43+60:63; 44:47+56:59; then it’s bank conflict-free for LDS reading.
Naïve Solution#
In the naive way, for the logical 2D tensor A_tile, shape as [64x32], it maps to a physical 3D LDS space [64x4x8], where the last dim 8 is for 128-bit alignment.
This mapping keeps things simple: it mirrors the DRAM layout directly, making it easy to implement and compatible with CK-Tile’s kernel setup. In this configuration:
LDS write operations using ds_write_b128 are bank conflict-free—ideal for storing data from threads into LDS.
LDS read operations using ds_read_b128 suffer from a 2-way bank conflict, due to overlapping access patterns within specific lane groups.
As shown in Figure 2, the naïve implementation is bank conflict-free for LDS writes but exhibits a 2-way bank conflict during LDS reads.

Figure 2. bank-conflict check for LDS write/read with naïve implementation#
XOR Solution#
While the naive layout is straightforward, it falls short when it comes to read efficiency due to bank conflicts. Padding can sometimes help, but it’s tricky to tune, consumes extra LDS space, and doesn’t guarantee a conflict-free solution. In the following section, we focus on the XOR solution-CK Tile natively supports this, which perfectly solves read/write LDS bank conflicts without requiring extra LDS buffer. This approach reorganizes how data is indexed in LDS, resulting in conflict-free reads and writes, without requiring additional memory.
XOR Transformation#
In CK-Tile, we support the XOR transformation as shown in Figure 3 below:
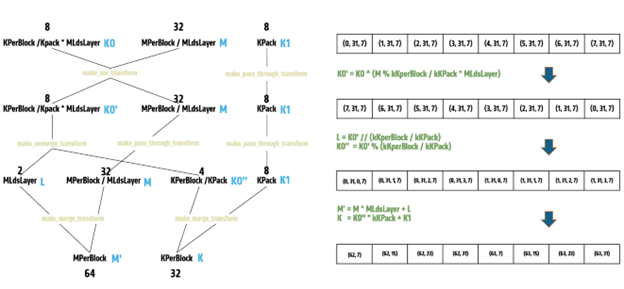
Figure 3. XOR coordinate transformation#
There are 3 steps during this XOR coordinate transformation, given the initial 3D LDS coordinate [K0, M, K1]:
Step 1. Update K0 with XOR transformation, i.e., K0' = K0 ^ (M % (KPerBlock / Kpack * MLdsLayer)), the intermediate 3D coordinate is [K0', M, K1]
Step 2. Split [K0', M, K1] into intermediate 4D coordinate [L, M, K0'', K1]
Step3. Merge intermediate 4D coordinate [L, M, K0'', K1] back to 2D coordinate [M', K]
With these coordinate transformations, logically tile_A is still [64, 32], but the underlying physical index is XOR-updated, which can avoid bank conflicts.
Re-Index Data/Lanes#
With XOR transformation, both lane index and element index are XOR-updated. Compared to the default case, now the elements to bank slots mapping is changed. The reindexed data and lane layout are shown in figure 4 and figure 5. This layout is now clearly bank conflict-free for both LDS writes and reads.
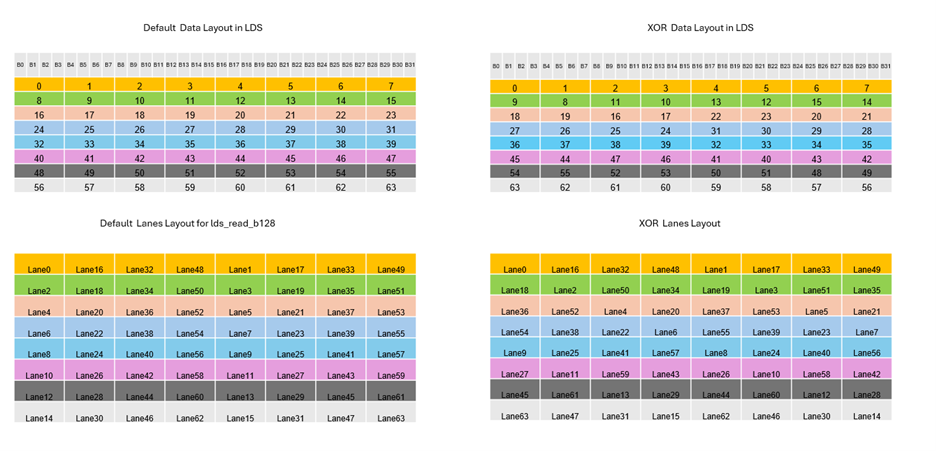
Figure 4. Reindex data and lanes layout#
Figure 5. Bank Conflict Check for LDS write/read with xor implementation#
Summary#
CK-Tile provides developers with powerful, flexible ways to take control of memory layout and fully unlock the bandwidth of LDS. By understanding how threads map to LDS banks and how the data flows through DRAM and shared memory, developers can design kernels which are bank conflict free. By understanding how LDS bank structure interacts with thread access patterns, developers can better utilize CK-Tile’s descriptors to ensure optimized shared memory usage. In this blog, we demonstrated these principles through a GEMM kernel case study, highlighting how different memory layouts affect bank conflicts and how an XOR-based swizzle transformation resolves them efficiently. If you’re building custom GPU kernels on AMD hardware optimize your shared memory usage try CK-Tile’s XOR-based swizzle to eliminate bank conflicts in your GEMM to get better performance without using extra resources.
Additional Resources#
Implementing FA-v2 with CK tile: From Theory to Kernel: Implement FlashAttention-v2 with CK-Tile — ROCm Blogs
Hands on with CK tile Hands-On with CK-Tile: Develop and Run Optimized GEMM on AMD GPUs — ROCm Blogs
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.