Measuring Max-Achievable FLOPs – Part 2#

In our previous blog post, we explored the conceptual differences between Peak FLOPs and Max-Achievable FLOPs (MAF), explaining why the gap between these metrics has widened with modern ML-optimized hardware. This second installment provides a detailed methodology for measuring MAF on AMD GPUs, including the specific environmental conditions, matrix size optimization techniques, and tools required for accurate measurement. We present the actual MAF results for AMD Instinct MI300X and MI325X GPUs across different precision formats (FP16, BF16, and FP8) along with their corresponding median frequencies. We also explain how software efficiency and frequency management impact MAF, and demonstrate why boost clock capabilities remain important for latency-sensitive workloads such as LLM inference with small batch sizes.
Key Highlights in this blog#
Matrix Size Optimization: Specific guidance on selecting optimal matrix dimensions that evenly distribute work and maximize efficiency, with concrete recommendations for AMD MI300 GPUs
Frequency Measurement Tools: Practical instructions for using
amd-smiandhipBLASLt-benchto accurately measure operating frequencies during benchmarkingSoftware Efficiency Factors: How AMD balances software optimization and architectural design to achieve up to 94% efficiency while managing power and frequency
Boost Clock: Evidence showing how boost clock capabilities can improve performance by over 25% in lightly-loaded scenarios like LLM inference
Official MAF Results: Actual measured performance figures for AMD’s latest GPUs that developers can use as optimization targets If you are just interested in seeing the MAF numbers – skip ahead to the AMD MAF Results section.
Measuring MAF#
MAF is assessed through benchmarking in a carefully controlled environment, using an optimal matrix size for the target device. The following key factors help achieve reliable measurements:
Controlled Environment#
Initialize tensors with representative data. The power consumption and the processing frequency of the matrix multiplication are significantly influenced by the toggle rates of the input data. Running the exact same matrix multiply dimensions with a “low-toggle” pattern (such as zeroes, or even small ranges of integers with similar exponent values) can inflate the processing frequency by more than 50%[1]. Initializing tensors with a normal distribution provides a good approximation of the weight and activation values seen in real machine learning applications.
Ensure a thermally stable environment – allow the device to warm up and stabilize its operating temperature. Confirm the device has exited any idle states and is not in an unsustainable “boost” frequency state prior and that the GPU is approaching its operating threshold temperature. On some devices, this stabilization process may take several seconds.
Start the benchmark with cold caches to include the time and power needed to load initial values from memory. This can be done by flushing caches or rotating through a set of tensors larger than the target system’s caches.
Optimal Matrix Size#
This explanation assumes you are already familiar with the implementation and optimization tradeoffs of matrix multiplication on GPUs (e.g. tiling, quantization inefficiency). If you are new to this area, you may want to review the resources in Appendix A.
Optimize the matrix dimensions for the target hardware. Choose matrix dimensions that evenly distribute work across all compute units and maximize time spent in the compute-intensive inner loop.
Traditional GEMM algorithms divide the output space into rectangular tiles, assigning one or more tiles to each compute unit. For MAF GEMM, it is important that each compute unit performs an equal amount of work and avoids partial utilization in the final phase.
Each compute unit handles one tile at a time. Larger tiles may increase efficiency due to more re-use but need more internal storage in registers and shared memory. Common GPU tile sizes are 128, 192, and 256
Some specific tips for finding the optimal matrix size#
Large K values increase the time in the inner loop and will generally provide higher efficiency. Extremely large K values (i.e. >2MB) may create undesirable TLB (Translation Lookaside Buffer) miss activity. Avoid exact powers of 2 as this can sometimes create hotspots in the memory hierarchy. Our recommendation for a good value on modern processors is 32K + 128.
One technique to find the optimal M and N size is to explore a wide set of large matrices and select the fastest.
First choose a large K (as suggested above)
Sweep M and N in modest steps, e.g. 1K at a time.
Alternatively, focus the search on some likely candidates by using this technique:
Divide the number of CUs into two integer factors which are similar in value. These factors will be the M and N of the matrix, and the goal is to keep this rectangle as square as possible. For example, 304 CUs is a 19x16; 132 CUs is 12x11.
Multiply M and N by likely GEMM tile sizes – 128, 192, 256.
Note
A good size for the AMD Instinct™ MI300 GPU with its 304 CUs: M = 16*256 = 4096, N = 19*192 = 3648, K = 32768+128 = 32896
Measuring Frequency And Software Efficiency#
Frequency#
A simple but effective technique for measuring frequency is to run
amd-smi in a loop inside one terminal while running the benchmark in
another. As the benchmark runs, the SMI tool will print the current
clock on the device – typically you can expect to see it rise from a
low idle frequency (300 MHz on AMD Instinct GPUs). The clock sampling
interval can be hundreds of milliseconds - for these tests we ran a
large GEMM for 1000ms with approximately 25% warmup and 75% benchmark
time to help ensure a stable environment.
In addition to amd-smi, AMD provides a GEMM benchmarking tool called
hipBLASLt-bench.
This tool can query the clock frequency for all XCDs on the MI300
multi-GPU die and thus provides a more accurate measure of the
frequency. Here’s a sample command line showing how to enable this, as
well as other important knobs for the
environment:
HIPBLASLT_BENCH_FREQ=1 hipblaslt-bench -m 4096 -n 4864 -k 32896 --alpha 1 --beta 0 --transA N --transB N --initialization trig_float --iters 431 --cold_iters 87 --a_type bf16_r --b_type bf16_r --c_type bf16_r --d_type bf16_r --compute_type f32_r --function matmul --rotating 512 --use_gpu_timer
The key output statistic is the “lowest-median-freq”. AMD Instinct MI300X and MI350X are designed with multiple chiplets, each with an independent clock that can be tracked separately. These clocks are usually very close, but the lowest clock determines the performance. The median is used instead of the average to avoid skew from outliers. For more information, see this link: hipBLASLt-bench. The command-lines for all data-types, hipBLASLt branch information and sample output are shown in Appendix B below.
Software Efficiency#
The overall MAF performance is driven by two factors:
The actual frequency when running the dense GEMM – we just showed how to measure this. Note this frequency is typically lower than the boost frequency that is achieved for lighter computation loads.
The software efficiency – this is a property of the software optimization level (e.g. perhaps the code is not scheduled optimally or is not written to hide memory latency) as well as the architecture efficiency of the design (e.g. perhaps the architecture has built-in bottlenecks that make it impossible for software to 100% utilize the hardware).
These factors are strongly related – higher software efficiency increases the power and will predictably result in a lower frequency. For example, on the AMD Instinct MI300 Series GPUs the “MFMA 32x32x8” instructions have a bigger payload and would enable a higher software efficiency – but the “MFMA 16x16x16” instructions consume less power and thus deliver higher MAF even with the lower software efficiency. Other software changes can reduce power and increase frequency - for example using larger compute tiles (up to 256x256 on MI300X/MI325X), minimizing data movement through shared memory, and improving cache locality. The AMD math libraries balance these efficiency and frequency tradeoffs to maximize the MAF. In AMD internal testing, the MAF kernels on AMD Instinct MI325X GPUs generate a software efficiency of up to 94%[2].
Importance of Boost Clock#
The power management system reduces the clock speed when running dense tensor-core logic, which is designed to operate at a lower clock. However, we would also like the chip to recognize lightly loaded scenarios and boost into the maximum supported clock rate. This enables the system to deliver optimal performance in both dense computation and latency-sensitive scenarios. The chart below shows the performance sensitivity of a workload that benefits from the boost clock capabilities:
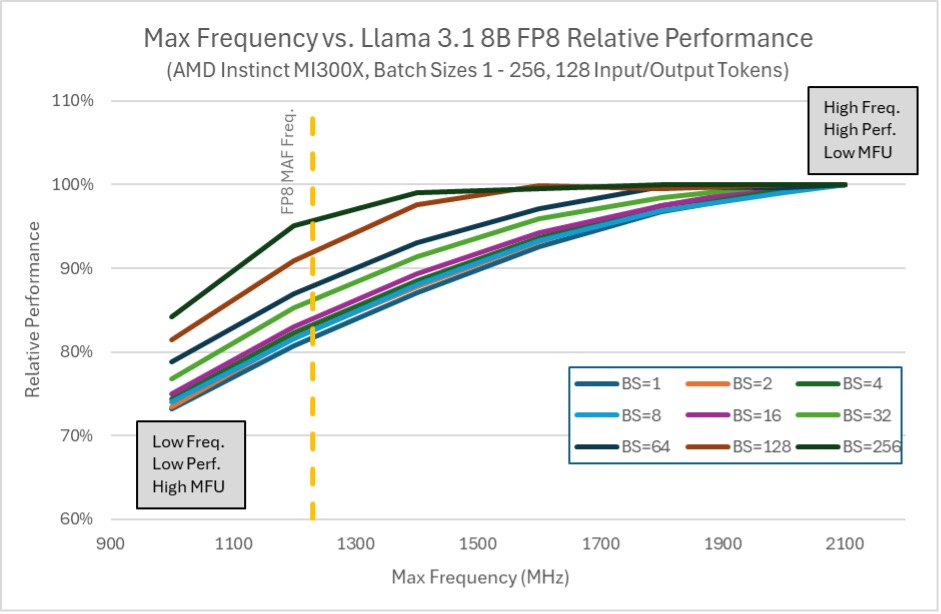
Figure 1: AMD Instinct MI300X Llama 3.1 8B FP8 relative performance vs. maximum GPU frequency[3]#
This workload (LLAMA-8B) represents a lightly loaded use case, benefiting significantly from the boost frequency, which enhances performance by over 25% (specifically at the BS=1 data point). Without this boost, performance would be limited to a relatively low level. While this limitation would increase efficiency, as indicated by MFU (Model Flops Utilization), it would adversely affect overall performance. Consequently, AMD advises prioritizing delivered performance and utilizing MAF flops when optimizing for efficiency.
AMD MAF Results#
Without further ado, here is a table of Max-Achievable FLOPS for AMD Instinct MI300X and MI325X GPUs[4]:
Product |
MAF FP16 (median freq.) |
MAF BF16 (median freq.) |
MAF FP8 (median freq.) |
|---|---|---|---|
AMD Instinct MI300X |
654 TFLOPs (1115 MHz) |
708 TFLOPs (1207 MHz) |
1273 TFLOPs (1230 MHz) |
AMD Instinct MI325X |
794 TFLOPs (1354 MHz) |
843 TFLOPs (1447 MHz) |
1519 TFLOPs (1464 MHz) |
Table 1: Max Achievable FLOPs (MAF) for AMD Instinct™ GPUs
As we have discussed, these numbers indicate the performance you can expect to achieve on AMD Instinct GPUs from our libraries and other highly optimized codes.
Summary#
We described a method for measuring MAF and shared measured numbers for AMD processors (in case you don’t want to measure it yourself). MAF requires some discipline to measure but is extremely useful for understanding realistic targets.
Appendix A : References for GPU GEMM Optimization#
Appendix B: hipBLASLt-bench commands#
Commands#
BF16:
hipblaslt-bench -m 4096 -n 4864 -k 32896 --alpha 1 --beta 0 --transA N --transB N --initialization trig_float --iters 431 --cold_iters 87 --a_type bf16_r --b_type bf16_r --c_type bf16_r --d_type bf16_r --compute_type f32_r --function matmul --rotating 512 --use_gpu_timer
FP16:
hipblaslt-bench -m 4096 -n 4864 -k 32896 --alpha 1 --beta 0 --transA N --transB N --initialization trig_float --iters 466 --cold_iters 94 --a_type f16_r --b_type f16_r --c_type f16_r --d_type f16_r --compute_type f32_r --function matmul --rotating 512 --use_gpu_timer
FP8:
hipblaslt-bench -m 4096 -n 3648 -k 32896 --alpha 1 --beta 0 --transA N --transB N --initialization trig_float --iters 1324 --cold_iters 265 --a_type f8_fnuz_r --b_type f8_fnuz_r --c_type f8_fnuz_r --d_type f8_fnuz_r --compute_type f32_r --function matmul --rotating 512 --use_gpu_timer
Branch Details for hipBLASlt#
Below are directions to clone and compile the hipBLASlt branch utilized in AMDs MAF measurements in this document. It includes the latest optimizations for performance at the time of testing and will be a target for the ROCm 6.5 GA software release.
git clone <https://github.com/ROCm/hipBLASLt>\
cd hipBLASLt/\
git checkout db8e93b4fd6c785d4ce6cac11cc3b0ad613ece8b\
./install.sh -dc -a gfx942\
cd build/release/clients/staging/\
./hipblaslt-bench --help
Sample Output#
HIPBLASLT_BENCH_FREQ=1 ./hipblaslt-bench -m 4096 -n 4864 -k 32896 --alpha 1 --beta 0 --transA N --transB N --initialization trig_float --iters 431 --cold_iters 87 --a_type bf16_r --b_type bf16_r -
-c_type bf16_r --d_type bf16_r --compute_type f32_r --function matmul --rotating 512 --use_gpu_timer
[0]:transA,transB,grouped_gemm,batch_count,m,n,k,alpha,lda,stride_a,beta,ldb,stride_b,ldc,stride_c,ldd,stride_d,a_type,b_type,c_type,d_type,compute_type,scaleA,scaleB,scaleC,scaleD,amaxD,activation_type,bias_vector,bias_type,rotating_buffer,lowest-avg-freq,lowest-median-freq,avg-MCLK,median-MCLK,hipblaslt-Gflops,hipblaslt-GB/s,us
N,N,0,1,4096,4864,32896,1,4096,134742016,0,32896,160006144,4096,19922944,4096,19922944,bf16_r,bf16_r,bf16_r,bf16_r,f32_r,0,0,0,0,0,none,0,bf16_r,512,1211,1210,900,900,709258,317.15,1848.09