Stability at Scale: AMD’s Full‑Stack Platform for Large‑Model Training#

Training large AI models on AMD GPUs demands unwavering stability and robust debugging capabilities at cluster scale. Yet today’s ROCm-based multi-node GPU deployments often rely on brittle scripts and disjointed tools to launch distributed jobs, monitor performance, and recover from failures. This patchwork approach makes troubleshooting difficult and undermines cluster-wide reliability as model sizes and run times grow.
Building on AMD’s Primus training framework – which provides unified YAML-based configuration and modular backend support for training large models – and Primus-Turbo – our high-performance acceleration library for transformer models – we recognized that production deployments needed more than efficient training code. They needed a complete platform for managing cluster infrastructure, ensuring stability, and maintaining visibility across hundreds or thousands of GPUs.
To address these challenges, Primus‑SaFE was introduced as AMD’s full-stack, full-lifecycle training platform built for stability and debuggability at scale. Running atop Kubernetes and deeply integrated with the ROCm software stack, Primus‑SaFE automates everything from cluster provisioning and intelligent job scheduling to real-time monitoring and hardware health validation. Its observability module – Primus‑Lens – provides full-stack telemetry and visualization across nodes, GPUs, and training jobs, enabling engineers to pinpoint issues quickly and optimize performance. By unifying these capabilities (alongside the Primus training framework and Primus‑Turbo libraries), Primus‑SaFE transforms AMD GPU clusters into resilient, self-monitoring environments ready for the next generation of large-model training.
In this blog, you’ll deploy Primus‑SaFE on a ROCm‑ready Kubernetes cluster, step by step. You’ll bootstrap the platform, enable end‑to‑end telemetry with Primus‑Lens, and run resilient multi‑node training on AMD GPUs. By the end, you’ll have a working stack and a repeatable recipe to stabilize large‑model training and accelerate your workflows.
Primus‑SaFE Architecture: Four Core Modules#
Primus‑SaFE is built around four tightly integrated modules, as illustrated in Figure 1 below. Each module addresses a critical aspect of large‑scale training: deployment, scheduling, observability, and validation.
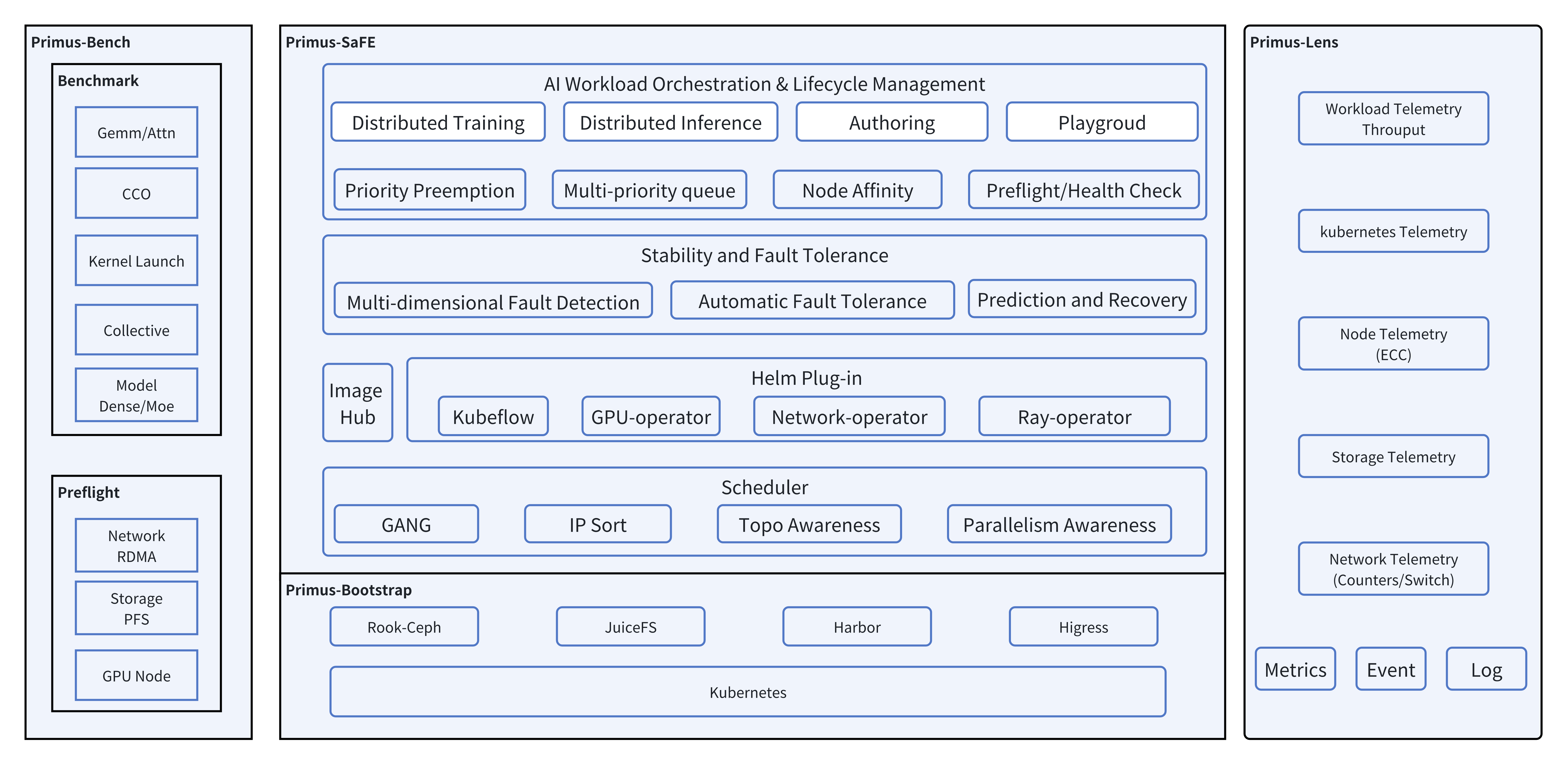
Figure 1: Primus-SaFE Full-Stack Architecture — The platform integrates four key modules for comprehensive training management.#
Primus‑Bootstrap: Rapid Cluster Deployment#
Large‑scale training requires a robust, high‑performance cluster foundation. Primus‑Bootstrap automates the deployment of a production‑grade Kubernetes cluster on bare‑metal servers, provisioning key components optimized for AI workloads:
Highly Available Kubernetes: Using Kubespray, Primus‑Bootstrap sets up a Kubernetes cluster with redundant control‑plane and etcd nodes for high availability. This ensures the cluster can tolerate failures without downtime.
Unified High‑Throughput Storage (JuiceFS): It deploys JuiceFS as a distributed file system for the cluster. JuiceFS decouples metadata from data by storing file metadata in a fast database (for example, Redis or MySQL) and the actual file contents in an object store (for example, Amazon S3). A client‑side cache accelerates access to millions of small files, providing the high throughput needed for massive datasets and eliminating storage bottlenecks during model training.
Secure Image Management (Harbor): A private Harbor registry is installed for container images. Harbor provides role‑based access control, image scanning and cryptographic signing, ensuring that all training containers used in the cluster are secure and verified.
High‑Concurrency API Gateway (Higress): Primus‑Bootstrap integrates Higress (built on Istio and Envoy) as a gateway for serving APIs. This gateway can handle high request volumes and supports WebAssembly plug‑ins for custom authentication, routing and rate limiting. It allows teams to expose training or inference services to users without worrying about traffic spikes or security issues.
With these components preconfigured, Primus-Bootstrap converts bare-metal servers into a ready-to-use AI training infrastructure. Teams can focus on model development instead of spending weeks on cluster setup and integration work.
Primus‑SaFE Platform: Intelligent Job Scheduling and Fault Tolerance#
Once the cluster is running, efficiently allocating GPU resources and keeping long training jobs running smoothly becomes critical. The Primus‑SaFE Platform extends Kubernetes scheduling with AI‑specific capabilities to maximize throughput and reliability, as shown in Figure 2 below:
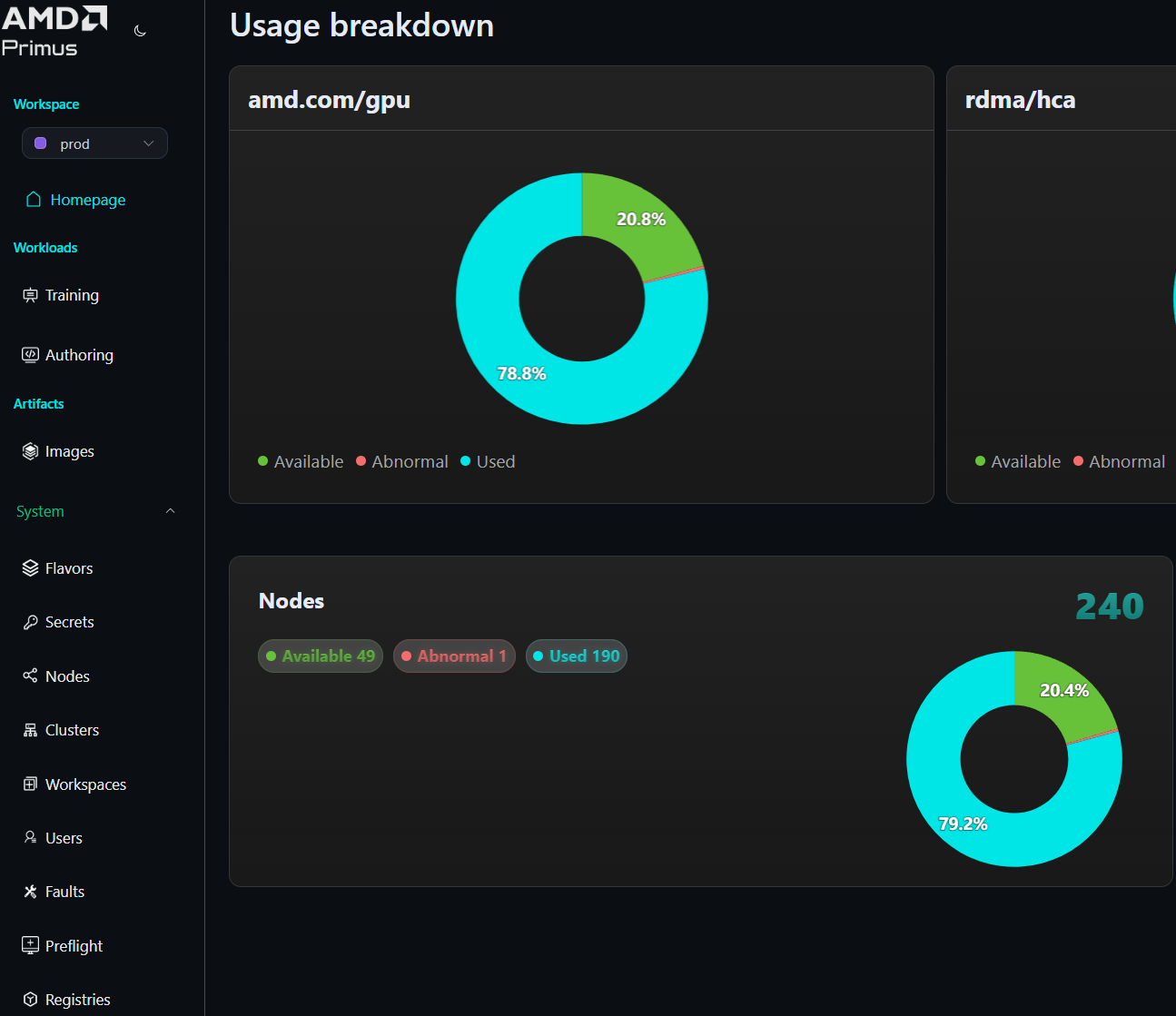
Figure 2: Primus-SaFE Feature Overview — Key capabilities for intelligent job scheduling and fault tolerance.#
Multi‑priority queues with preemption: The platform supports multiple job priority levels. High‑priority jobs can preempt lower‑priority jobs when GPU resources are limited, ensuring that urgent experiments start promptly without waiting behind less critical tasks.
Automatic failover and retry: The platform continuously monitors node and GPU health. If a node goes down or a GPU encounters errors, the affected training tasks are automatically rescheduled to healthy nodes and resumed from the last checkpoint. Jobs that were waiting in the queue are automatically retried when resources free up. This automation minimizes manual intervention and keeps week‑long training runs going even if hardware issues arise.
Topology‑aware placement: The
topologyIPSortplug‑in sorts nodes based on IP address and presumed network topology. By preferring nodes that are closer in the network (for example, within the same subnet or data‑center cluster), it improves network locality for communication‑intensive workloads. The platform also integrates advanced mechanisms like gang scheduling to handle groups of pods together.Health checks and preflight validation: Whenever new nodes are added to the cluster or when system software is updated, the platform triggers a battery of health checks before scheduling real workloads. Leveraging Primus‑Bench’s preflight system, it verifies environment variables, network connectivity and runs small end-to-end training tests to ensure the node can handle the target model’s scale and parallelism. Nodes that underperform or otherwise fail these preflight tests are quarantined for investigation, preventing them from disrupting actual training jobs.
These features enable high GPU utilization and robust fault tolerance. Even if certain nodes fail or restart, the Primus‑SaFE platform ensures that training jobs make progress, achieving stability for multi‑week runs without constant babysitting.
Primus‑Lens: Full‑Stack Observability & Visualization#
Primus‑Lens is the observability and visualization module of the Primus‑SaFE platform. It gives teams a structured, real‑time view of both cluster infrastructure and training workloads:
Cluster‑wide monitoring: Primus‑Lens aggregates metrics from every node and GPU, including compute utilization, memory usage, network throughput, I/O, temperatures and power consumption. These data points are displayed on an interactive dashboard, making it easy to identify idle GPUs, overloaded nodes or other anomalies.
Job‑level telemetry: In addition to system metrics, Primus‑Lens tracks the progress of each individual training job – such as iterations completed, throughput (samples per second), loss trends and checkpoint status. It correlates these events with system metrics, enabling quick diagnosis of issues like sudden drops in performance or spikes in I/O.
Interactive visualizations and alerts: Users can set thresholds and notifications (for example, GPU utilization below 50% or memory usage exceeding a limit). The dashboard supports comparing metrics across nodes or jobs and linking them to relevant log events. This reduces the time spent sifting through logs and helps engineers pinpoint root causes more efficiently.
As you can see in Figure 3 below, the Primus‑Lens dashboard provides comprehensive visibility into cluster health and training progress:
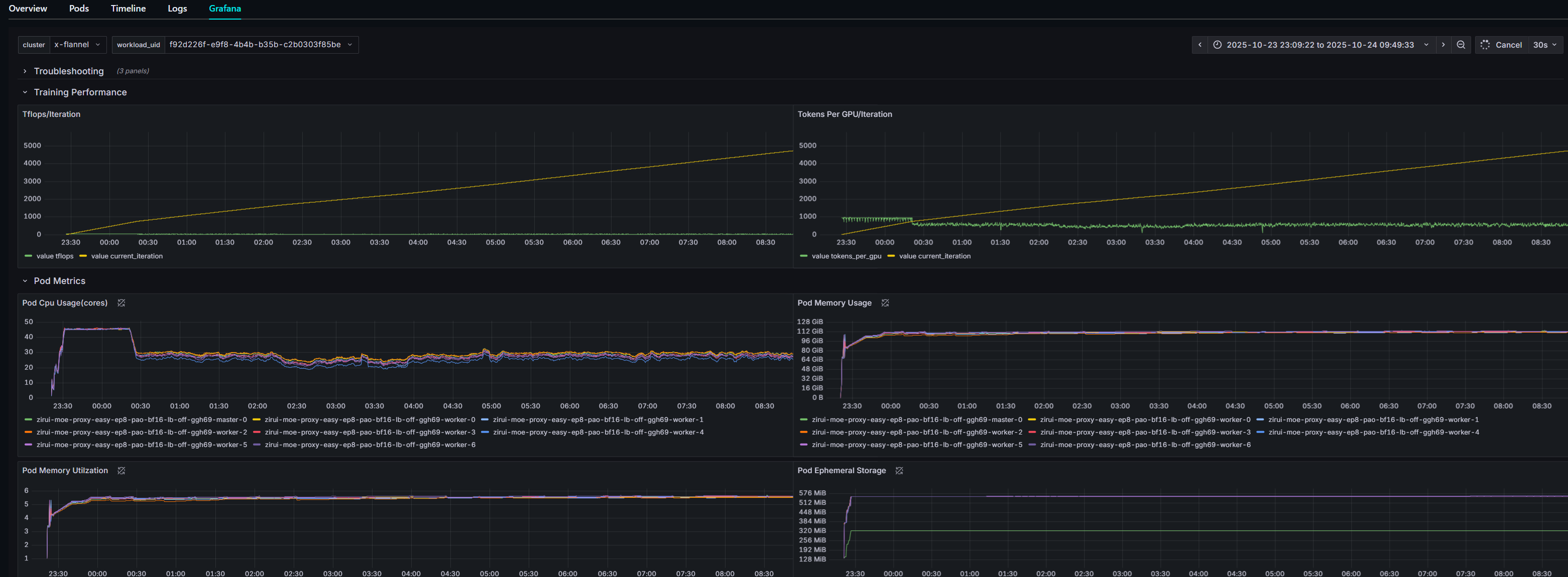
Figure 3: Primus-Lens Observability & Visualization — Interactive dashboard for full-stack monitoring and performance insights.#
By turning raw telemetry into actionable insights, Primus-Lens helps MLOps teams optimize resource usage, resolve bottlenecks quickly, and ensure that large GPU clusters run efficiently and reliably.
Primus‑Bench: Node Health Checks and Performance Benchmarking#
Before launching multi-node training jobs, it’s vital to ensure every GPU node is in good shape and performing as expected. Primus‑Bench is a module dedicated to rigorous health checking and benchmarking of each node in the cluster:
Hardware and network diagnostics: Primus-Bench runs low-level diagnostics to verify that each node’s GPUs, drivers, and network interfaces are functioning properly. It can catch issues like misconfigured network settings or faulty GPU connections upfront, before those nodes are allowed into the training pool.
Micro‑benchmarks for AI workloads: The module executes a suite of standard operations used in AI training (for example, matrix multiplications and distributed communication patterns like all-gather). By measuring the throughput of these operations on each node, Primus-Bench can detect if any server is significantly slower than others. This helps identify underperforming hardware or misconfigurations that could bottleneck a distributed job.
Trial training runs: As a final check, Primus-Bench can run a small-scale training job (a few iterations of a known model) on each node to validate end-to-end training functionality. This simulates a real training workload on the node and verifies that all components (compute, memory, and networking) work together under actual training conditions.
Nodes that fail any of these tests or show subpar performance are flagged for maintenance or replacement before they are added to the main cluster. By preemptively isolating underperforming hardware, Primus-Bench prevents a slow or flaky node from dragging down large distributed training jobs. In short, it ensures that all nodes in the cluster meet a baseline performance standard and that the overall training environment is as robust as possible.
Key Features and Advantages#
Primus-SaFE’s integrated approach brings several key benefits to teams running large-model training on AMD GPU clusters:
High‑availability, high‑performance infrastructure: Primus-Bootstrap rapidly provisions a production-grade Kubernetes environment with all the necessary services for AI workloads. The use of JuiceFS for storage (separating metadata and data with caching) removes I/O bottlenecks that typically plague large-model training. Harbor ensures that only trusted, optimized container images run on the cluster, while Higress provides a scalable entry point to handle user requests. Together, these technologies deliver a stable, high-throughput platform for training and fine-tuning large models.
Intelligent scheduling and resilience: The Primus-SaFE Platform’s multi-level priority and preemption mechanism guarantees that high-priority jobs are not stuck waiting, which is crucial in shared research environments. Its automatic failover and retry capabilities keep training jobs running despite node failures or GPU errors, significantly improving experiment completion rates. Comprehensive health checks catch problems early, ensuring that long-running jobs do not crash unexpectedly due to undetected system issues.
Comprehensive monitoring and insight: With Primus-Lens, engineers and administrators have real-time insight into the entire training stack. The ability to visualize cluster-wide metrics and per-job details helps in quickly diagnosing performance issues or inefficiencies. This means less time searching through logs and more time optimizing model performance and system usage. Bottlenecks (whether CPU, GPU, memory, or I/O) can be identified at a glance and addressed promptly.
Preflight validation and performance consistency: Built-in preflight checks and benchmarking (via Primus-Bench and the scheduler) ensure that any new node or software configuration is vetted before it joins a large training job. This preemptive validation prevents a scenario where a single bad node could crash a multi-node run or slow it down. It also provides quantifiable performance data across nodes, so that workloads can be distributed evenly and any outliers can be tuned or fixed, leading to consistent training performance.
End‑to‑end large‑model training solution: Perhaps most importantly, Primus-SaFE combines high-availability infrastructure, smart scheduling, secure management, and deep observability into one cohesive platform. This holistic solution enables organizations to treat large-model training as a reliable service. Primus-SaFE supports scaling to hundreds or even thousands of AMD GPUs, paving the way for “training-as-a-service” offerings and making the process of developing giant AI models on AMD hardware much more manageable and efficient.
Extreme scalability: Primus-SaFE can scale from small lab setups to massive deployments. The platform has been tested on clusters ranging from just a few GPUs up to tens of thousands of GPUs. The architecture is designed to handle clusters on the order of 100,000 GPU accelerators. In short, Primus-SaFE can turn an AMD GPU pod of any size into a cohesive, fault-tolerant training engine for giant models.
Installing the Full‑Stack Primus‑SaFE Platform#
The Primus-SaFE platform combines the Kubernetes bootstrap, observability, and stability layers into a single codebase. Instead of cloning multiple repositories, you can clone a single unified repository and then install each component from its respective subdirectory.
1. Clone the unified repository#
git clone https://github.com/AMD-AGI/Primus-SaFE.git
cd Primus-SaFE
The repository contains:
bootstrap/— Kubernetes cluster bootstrapLens/— Observability (Primus-Lens)SaFE/— Stability & scheduling layer (Primus-SaFE)
2. Bootstrap the Kubernetes cluster#
Enter the bootstrap directory
cd bootstrap
Configure your hosts
Edit
hosts.yamlto list node IPs/hostnames and roles (e.g., control-plane, worker).Save the file.
Run the bootstrap script
bash bootstrap.sh
Once this completes, a production-grade Kubernetes cluster and base services will be running.
3. Deploy observability with Primus-Lens#
Enter the Lens bootstrap directory
cd ../Lens/bootstrap
Install Primus-Lens
bash install.sh
Once completed, the monitoring dashboards and logging backends are now available.
4. Install the Primus-SaFE platform layer#
Enter the SaFE bootstrap directory
cd ../../SaFE/bootstrap
Deploy Primus-SaFE
bash install.shThis installs the stability/scheduling layer (sanity checks, topology-aware scheduling, fault tolerance).
Primus-SaFE extends Kubernetes by adding cluster sanity checks, topology-aware scheduling, and fault tolerance. Once all components are installed, the full stack is ready for large-scale AI training workloads.
Roadmap and Future Work#
Primus-SaFE is an evolving platform, and several exciting enhancements are on the roadmap to further broaden its capabilities:
Next‑generation AMD hardware and networking: As new hardware becomes available, Primus‑SaFE will add support for upcoming AMD Instinct GPUs (such as the MI450 series) and adapt to the latest ROCm software stack. The platform is also being tuned for advanced interconnects like 400 Gbps AI NICs to accelerate inter-GPU communications, further leveraging technologies such as RCCL for faster all-reduce operations and data exchange.
Agentic platform: The team is exploring integration of AI agents to manage and optimize the platform. Using multi-agent systems (for example, LangGraph or CrewAI), future versions of Primus-SaFE could automate complex operations through natural-language instructions. For instance, an engineer might simply request, “Deploy 20 nodes and start training model X,” and an AI agent orchestrating Primus-SaFE would then carry out the deployment, scheduling, and monitoring steps automatically. This could greatly simplify user interaction with large clusters.
Finer‑grained fault tolerance: Currently, Primus-SaFE handles failures at the node or pod level. The roadmap includes research into more granular fault tolerance – such as process-level failover, where an individual GPU process could be restarted without stopping the entire job. Asynchronous checkpointing mechanisms are being evaluated to allow parts of a training job to save and restore state independently. Additionally, strategies like running redundant training processes or gracefully degrading the workload when a component fails are being explored to make training jobs virtually uninterruptible.
Summary#
You now have Primus‑SaFE up and running on a ROCm‑ready Kubernetes cluster, complete with full‑stack telemetry via Primus‑Lens and robust multi‑node training on AMD GPUs. This setup stabilizes your large‑model training workflows, surfaces issues early, and helps you recover quickly when failures occur.
Together with the Primus training framework and Primus-Turbo acceleration libraries, Primus-SaFE completes AMD’s end-to-end solution for large-model development – from optimized training kernels and streamlined experiment management to production-grade cluster orchestration and observability. We invite you to explore the complete Primus ecosystem and experience how AMD is making large-scale AI training more accessible, reliable, and performant on ROCm.
Additional Resources#
Primus: A Lightweight, Unified Training Framework for Large Models on AMD GPUs
An Introduction to Primus-Turbo: A Library for Accelerating Transformer Models on AMD GPUs