GEAK: Introducing Triton Kernel AI Agent & Evaluation Benchmarks#

At AMD, we are pioneering ways to accelerate AI development using AI itself, by generating accurate and efficient GPU kernels. Specifically, we are starting with the automatic generation of kernels in Triton, an open-source Python-like language for writing parallel programming code for GPUs. Today, AMD is excited to announce (a) Generating Efficient AI-centric Kernels (GEAK) for AMD GPUs, and results on (b) two Triton kernel evaluation benchmarks, where we show how AI agents can perform inference-time scaling with frontier LLMs to generate accurate and efficient kernels for AMD Instinct™ GPUs like MI250X and MI300X.
Key Takeaways:
Announcing GEAK Triton kernel generation framework, a library of various types of agentic AI and scaling methods to automatically produce Triton kernels from just brief instructions of its intended functionality.
Announcing corresponding GEAK Triton Kernel Evaluation Benchmarks, consisting of a modified set of 184 kernels originally sourced from TritonBench-G [1] and an additional set of 30 kernels from various open ROCm repositories.
Execution accuracy up to 54.89% on TritonBench-modified and 63.33% on ROCm benchmark (as compared to around 15% when directly prompting frontier LLMs) in producing correct kernels that pass all the unit tests.
Average Speedup of up to 2.59X with the AI-generated kernels over reference kernels from the TritonBench-modified benchmark.
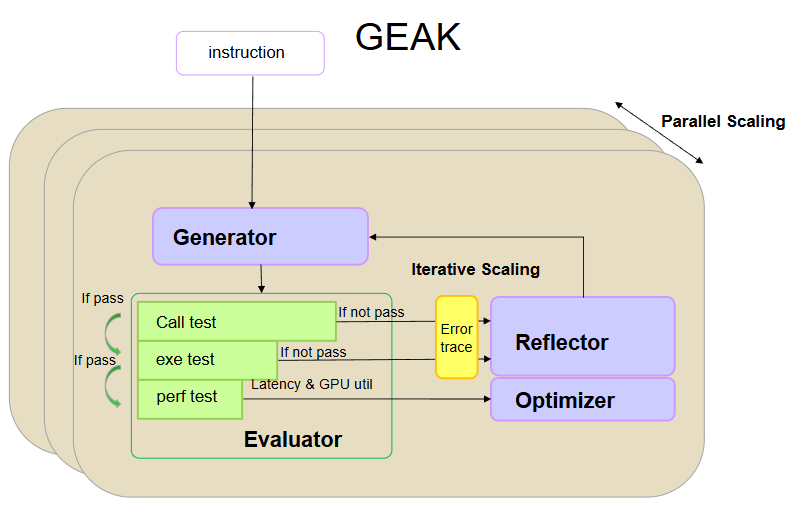
Figure 1. Overview of the GEAK kernel code generation AI agent#
As shown in Figure 1, the agentic AI system comprises four core modules: a generator, a reflector, an evaluator, and an optimizer.
The generator produces code based on user query and contextual information.
The evaluator follows a cascaded design: it first performs a functionality test to verify correctness. If the code fails this test, the corresponding error trace is fed back to the reflector for further analysis. If the code passes, the evaluator proceeds to assess its performance, including latency and memory efficiency.
If the generated code fails to execute correctly, the reflector analyzes both the code and the resulting error trace to identify potential issues.
Finally, the optimizer takes as input the functionally correct code and formulates strategies to enhance its performance with respect to latency and computational efficiency.
To improve the performance of our agent, we employ some composable and configurable techniques as mentioned below:
1-shot Prompting
To enable 1-shot prompting, the most similar Triton code from existing datasets is used in the prompt. The datasets used for 1-shot prompt do not overlap with the benchmark. We’ve observed that 1-shot sample retrieval from datasets is most effective when using code similarity rather than instruction similarity.
Knowledge Injection
We enhance the prompt with domain-specific knowledge on writing efficient Triton kernels, including detailed hardware specifications. This incorporation of low-level optimization principles significantly improves the accuracy and quality of LLM-generated code.
Reflexion
To enhance the system’s self-correcting capabilities, we leverage a reflexion [3] module that supports introspective debugging and iterative refinement. When an LLM-generated kernel fails the functionality test, the resulting error trace is provided as feedback to the reflector for further analysis and correction. The agent is tasked with analyzing the cause of failure and proposing a corresponding solution. We scale the number of iterations to improve kernel generation.
LLM selection for kernel agent
We have explored the use of multiple LLMs like GPT-4.1, GPT-o1, and Gemini 2.5 Pro. We observed notable variations in the output produced by different models, indicating that the capability of the underlying LLM can substantially influence the results. In this blog, we present results with GPT-4.1 only but the GEAK codebase allows developers to try different LLMs as per their choice.
LLM as Optimizer
The optimizer is tasked with identifying potential optimization directions based on previous code generations and their corresponding performance metrics. These historical records, which include the generated code and associated performance results, are sorted in ascending order of performance. This structured presentation [2] helps guide the LLM toward proposing more effective optimization strategies.
Debugging Trap
When LLM’s generated code has bugs, the error trace is provided to the Reflector for feedback generation for further correction. However, we’ve observed that sometimes code can undergo several reflection cycles while still being plagued by the same bug, which is what we refer to as the debugging trap. To prevent the agent from getting stuck in a debugging trap, we impose a limit on the number of debugging attempts per code snippet using a parameter max_perf_debug_num. If the code continues to fail after reaching this threshold, the agent is required to discard the current approach and generate a new strategy along with fresh code.
Parallel Scaling
To ensure reliable kernel generation, we run multiple instances of GEAK multiple times in parallel and independently. To introduce diversity in the generated code, the LLM output is sampled with the parameter temperature set to 1. Our experiments show that such diversity in generation can yield correct and faster kernels that are otherwise underexplored. Moreover, further experiments indicate that combining sequential and parallel scaling yields additional performance improvements. To obtain unbiased estimates of accuracy, we use the pass@k metric to estimate it [4].
Triton Kernel Evaluation Benchmark#
We conducted experiments using two benchmarks methods:
1. TritonBench-Modified Benchmark (184 Kernels):
The Triton kernels and corresponding evaluation codebase were adapted from TritonBench [1] with several modifications made:
Out of 184 kernels in TritonBench-G, we identified and corrected errors in 37 kernels that were encountered when running on AMD GPUs. These errors include shared memory errors, invalid HIP arguments, and ModuleNotFound errors.
We found that several kernels in the original TritonBench repository missed necessary call functions, which resulted in the accuracy checking code comparing empty strings as output. We corrected this and ensured that the correct common seed was used during test.
For some kernels, testbenches were written inconsistently that produced unexpected outputs. We have fixed these kernels to have consistent testbenches.
2. ROCm Repository Triton Benchmark (30 Kernels):
The benchmark contains 30 kernels chosen from various open ROCm repositories that have been written by Triton expert engineers and released publicly to help enable the ecosystem around running AI workloads efficiently on AMD GPUs. The entire list of kernels is outlined in Table 1. We also took assistance from frontier LLMs to put these kernels, as well as their corresponding unit tests, in the same format as the TritonBench-modified framework. It allows us to compare the accuracy and efficiency of our agent consistently.
ROCm Kernel |
Repository link |
|---|---|
1. test_tma_store_gemm |
|
1. mnsnorm_fwd |
|
1. test_triton_swizzle2d |
|
1. test_load_reduce.py |
|
1. test_random_int |
|
1. test_flashattention_fwd |
|
1. test_gemm_no_scf |
|
1. test_cast_matmul |
Table 1. List of kernels and their sources in the RoCM repositories Triton benchmark
The metrics that we evaluate are the same as how they are defined in TritonBench paper [1]:
Call Accuracy: Percentage of AI-generated kernels that can compile and run without any errors.
Execution Accuracy: Percentage of AI-generated kernels that satisfy unit tests.
Speedup: Relative execution time improvement of AI-generated kernels over reference ground truth kernels. It is the mean of latency of the reference kernel divided by the latency of the generated kernel over multiple test cases. We report the average speedup over multiple kernels in benchmarks.
Results#
Baselines#
We first establish our baseline by directly prompting frontier LLMs, such as GPT-4.1, Gemini 2.5 Pro, and Claude 3.7 Sonnet, to produce the kernels.
Model |
Call accuracy (%) |
Exec accuracy (%) |
Average Speedup |
|---|---|---|---|
TritonBench-modified benchmark |
|||
GPT4.1 |
14.67 / 19.02 |
8.70 / 14.13 |
0.52 / 0.53 |
GPT4o |
10.87 / 14.13 |
7.07 / 9.24 |
0.51 / 0.53 |
Gemini2.5pro |
20.65 / 21.74 |
14.13 / 16.85 |
1.33 / 0.96 |
Claude 3.7 Sonnet |
11.41 / 20.11 |
7.07 / 15.22 |
0.61 / 0.96 |
ROCm benchmark (0-shot results only) |
|||
GPT 4.1 |
0 |
0 |
0 |
Gemini-2.5 Pro |
40 |
16.66 |
0.91 |
Table 2. Evaluation of several frontier LLMs on TritonBench-modified benchmark using direct prompting only. For TritonBench-modified, numbers to the left of ‘/’ indicate 0-shot results and to the right are 1-shot prompting results.
As presented in Table 2, direct prompting of large language models (LLMs) does not result in significant improvements in accuracy or execution speed compared to the ground truth kernels. Among the evaluated frontier LLMs, Gemini 2.5 Pro demonstrated comparatively superior execution accuracy and performance.
GEAK#
We study GEAK and also conduct an ablation without the optimizer module (see Figure 1) that we refer to as GEAK-no-optim. For all the experiments in this section, we used GPT 4.1 as the LLM for generator, reflector, and optimizer. All the results in the tables below are shown for 10 sequential iterations and 10 parallel instances. We present results with evaluation done across AMD Instinct MI250X and MI300X GPUs.
Difficulty level |
Correctly generated kernels |
Total kernels in dataset |
Exec Accuracy (%) |
Average Speedup |
|---|---|---|---|---|
1 |
2 |
3 |
66.67 |
1.27 |
2 |
20 |
27 |
74.07 |
1.12 |
3 |
42 |
65 |
64.62 |
1.94 |
4 |
32 |
84 |
38.10 |
1.43 |
5 |
0 |
5 |
0.00 |
- |
overall |
96 |
184 |
52.17 |
1.61 |
Table 3. Evaluation of TritonBench-modified kernels on AMD Instinct MI250 GPUs using GEAK-no-optim on GPT4.1.
Difficulty level |
Correctly generated kernels |
Total kernels in dataset |
Exec Accuracy (%) |
Average Speedup |
|---|---|---|---|---|
TritonBench-modified benchmark |
||||
1 |
3 |
3 |
100.00 |
1.16 |
2 |
20 |
27 |
74.04 |
1.17 |
3 |
38 |
65 |
58.46 |
2.13 |
4 |
33 |
84 |
39.29 |
1.91 |
5 |
0 |
5 |
0.00 |
- |
overall |
94 |
184 |
51.08 |
1.81 |
ROCm benchmark |
||||
overall |
12 |
30 |
40.00 |
0.85 |
Table 4. Evaluation of both benchmarks on AMD InstinctMI300X GPUs using GEAK-no-optim on GPT4.1
The agent shows promising improvements over direct prompting for both generating correct kernels and improving their performance. Tables 3 and 4 show that the execution accuracy of the agent peaked at 52.17% as compared to just ~14% when directly prompted with GPT 4.1. GEAK-no-optim solves 100% of the level 1 problems with higher than baseline speedup. Execution accuracy reduces as the difficulty level rises, and this can be attributed to the complexity required in generating kernels with higher difficulty. However, speedup of the correctly generated kernels still improves with increasing difficulty till levels 3. On TritonBench-modified benchmark’s 184 kernels, GEAK-no-optim achieves 51.08% execution accuracy and 1.81x average speedup on MI300X GPUs.
ROCm repository Triton benchmark, on the other hand, is a harder benchmark in terms of efficiency since the kernels were written by Triton expert engineers and were specifically tuned for AMD GPUs. Thus, the average latency of AI generated kernels remains higher than that of expert written kernels (and thus we get a less than one average speedup of 0.85). Notably, GEAK-no-optim produced 5 kernels (among the 30 kernels) with lower latency (higher speedup) than their baseline counterparts. Nevertheless, GEAK-no-optim shows promising improvement in execution accuracy (40%) compared to directly prompting frontier LLMs (~16%).
Difficulty level |
Correctly generated kernels |
Total kernels in dataset |
Exec Accuracy (%) |
Average Speedup |
|---|---|---|---|---|
1 |
2 |
3 |
66.67 |
1.24 |
2 |
23 |
27 |
85.19 |
4.78 |
3 |
39 |
65 |
60.00 |
1.57 |
4 |
32 |
84 |
38.10 |
2.24 |
5 |
1 |
5 |
20.00 |
0.14 |
overall |
97 |
184 |
52.72 |
2.42 |
Table 5. Evaluation of TritonBench-modified kernels on AMD Instinct MI250X GPUs using GEAK on GPT4.1.
Difficulty level |
Correctly generated kernels |
Total kernels in dataset |
Exec Accuracy (%) |
Average Speedup |
|---|---|---|---|---|
TritonBench-modified benchmark |
||||
1 |
3 |
3 |
100.00 |
1.16 |
2 |
22 |
27 |
81.48 |
1.69 |
3 |
41 |
65 |
63.08 |
3.02 |
4 |
34 |
84 |
40.48 |
2.86 |
5 |
1 |
5 |
20.00 |
0.61 |
overall |
101 |
184 |
54.89 |
2.59 |
ROCm benchmark |
||||
overall |
19 |
30 |
63.33 |
0.92 |
Table 6. Evaluation of both benchmarks on AMD Instinct MI300X GPUs using GEAK on GPT4.1.
GEAK with the optimizer module shows more promise than GEAK-no-optim in improving both latency and correctness of the generated kernels. Table 5 shows results on evaluating TritonBench-modified benchmarks on MI300X and MI250X GPUs using GEAK with GPT4.1. The execution accuracy of GEAK peaked at 54.89% on MI300X GPUs. GEAK not only solves 100% of the level 1 easier problems with higher than baseline speedup but also demonstrates substantial improvement for all difficulty levels. Most notably, unlike GEAK-no-optim, GEAK can generate one level 5 difficulty kernel correctly. With respect to latency, on TritonBench-modified benchmark, GEAK achieves up to 2.59x average speedup on MI300 GPUs, which can be attributed to the role of Optimizer in finding more creative performance optimization strategies.
Table 6 presents the results from the ROCm repository Triton benchmark, which shows similar trends. GEAK outperforms GEAK-no-optim in generating correct kernels, achieving execution accuracy of 63.33% compared to 40%. Additionally, the average speedup improves to 0.92. Notably, 11 out of 30 kernels generated by GEAK have higher speedup than their corresponding human expert-written baselines.
Inference-time Scaling Patterns
Here we showcase how call and execution accuracy vary as we increase inference-time compute along the dimension of parallel scaling (that is increasing the number of independent experiments k to come up with pass@k).
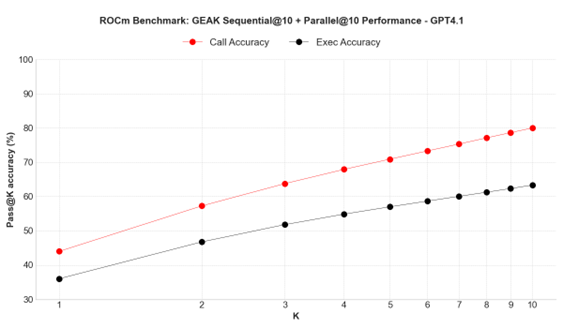
Figure 2. Inference time compute scaling study on ROCm benchmark.#
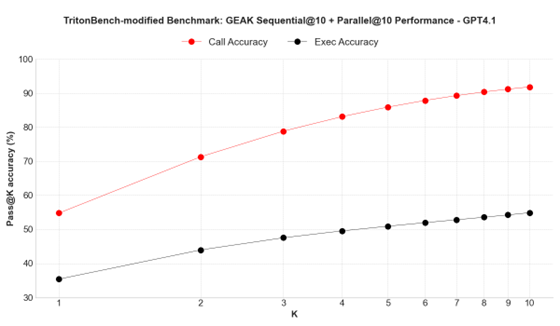
Figure 3. Inference time compute scaling study on TritonBench-modified benchmark.#
Figures 2 and 3 show inference time scaling patterns on ROCm and TritonBench-modified benchmarks respectively. Both call and execution accuracy scale almost log-linearly with respect to the number of parallel runs. The scaling characteristics support GEAK’s flexible architecture design, where parallel compute resources can be dynamically allocated based on task complexity and accuracy requirements.
Summary#
We observe that our agent, GEAK, is not only able to produce correct Triton kernels for various use cases but is also able to provide decent speedups over the reference kernels. Iterative test time compute scaling is instrumental in improving the performance of our agent. By fully open-sourcing the benchmarks and code for running the agent, we expect to engage the open-source community to accelerate the development of GPU kernels. We invite developers, researchers, and AI enthusiasts to explore the agent and benchmarks, and we hope this will foster innovation and collaboration within the AI community to develop with even better methods and final output kernels that can significantly improve the efficiency of training and inference for large-scale AI models.
References#
[1] TritonBench: https://arxiv.org/abs/2502.14752
[2] LLMs as Optimizers: [2309.03409] Large Language Models as Optimizers
[3] Reflexion: https://arxiv.org/abs/2303.11366
[4] HumanEval paper: [2107.03374] Evaluating Large Language Models Trained on Code
Additional Resources#
GEAK Triton Kernel Agent code: AMD-AIG-AIMA/GEAK-Agent
GEAK Triton Kernel Evaluation Benchmarks: AMD-AIG-AIMA/GEAK-eval
Technical Report (Arxiv): https://arxiv.org/pdf/2507.23194
Bias, Risks & Limitations#
The agent code is being released for research purposes only and is not intended for use cases that require high levels of factuality, safety-critical situations, health, or medical applications, generating false information, or facilitating toxic conversations.
Agent code is made accessible without any assurances of safety. Users must conduct comprehensive evaluations and implement safety filtering mechanisms as per their respective use cases.
It may be possible to prompt the agent to generate content that may be factually inaccurate, harmful, violent, toxic, biased, or otherwise objectionable. Such content may also be generated by prompts that were not intended to produce output as such. Users are therefore requested to be aware of this and exercise caution and responsible thinking when using it.
Multilingual abilities have not been tested; therefore, the agent may misunderstand and generate erroneous responses when prompted using different languages.
License#
Apache 2.0
Acknowledgements#
We would like to acknowledge the following folks for constructive discussions and feedback during this work - Alan Lee, Peng Sun, Vinayak Gokhale, Jason Furmanek, Sharunas Kalade, Graham Schelle, Sampsa Rikonen, Doug Lehr, Zhaoyi Li, Yonatan Dukler, Vikram Appia, Arseny Moskvichev, Stephen Youn, and Steve Reinhardt.
Citations#
@misc{wang2025geakintroducingtritonkernel,
title={Geak: Introducing Triton Kernel AI Agent & Evaluation Benchmarks},
author={Jianghui Wang and Vinay Joshi and Saptarshi Majumder and Xu Chao and Bin Ding and Ziqiong Liu and Pratik Prabhanjan Brahma and Dong Li and Zicheng Liu and Emad Barsoum},
year={2025},
eprint={2507.23194},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2507.23194},
}
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.