Day 0 Developer Guide: hipBLASLt Offline GEMM Tuning Script#

This blog post focuses on optimizing the performance of a real model using the QuickTune script, illustrated with an example of offline GEMM tuning for the Qwen model on an AMD MI308 GPU. Developed by the AMD Quark Team, the QuickTune script delivers significant GEMM performance improvements with minimal time overhead. QuickTune is an advanced tool for hipBLASLt offline GEMM tuning. It allows users to complete offline tuning with one click, instead of using hipblaslt-bench to tune the model manually.
For more information about how to use hipblaslt-bench to perform offline tuning, please refer to the previous blog post hipblaslt offline tuning part 2. The previous blog post shows you how to use the tuning basic tool hipblaslt-bench on a single GEMM. In this blog post we will follow-up on that work and show you an advanced tuning script (based on hipblaslt-bench), which was developed to tune large amount of GEMMs in a model.
Background#
Matrix–matrix multiplication, or GEMM (General Matrix Multiply), is one of the most fundamental operations in AI workloads. GEMM operations dominate both training and inference time, often consuming the majority of total runtime. Because of this, even a small improvement in GEMM performance can translate into significant end-to-end speedups. A tremendous amount of research has gone into the optimization of matrix multiplication.
GEMM tuning is the process of optimizing how GEMM operations are executed on specific hardware to maximize performance. Modern software libraries offer multiple algorithms or kernel variants for computing GEMM on CPUs and GPUs, each with different tile and block sizes, memory layouts, thread configurations and instruction usage. The goal of tuning is to identify the implementation that yields the best performance for a given production scenario (e.g., on metrics such as throughput, latency, and goodput) for a specific matrix size, data type, and hardware architecture.
The types of GEMM tuning include:
Offline Tuning: Profile different solutions before deployment and adopt the best one.
Online Tuning: Tune on-the-fly during runtime to dynamically profile and choose the best performing one based on actual input characteristics.
Compared with online tuning, offline tuning has the following advantages:
High performance: Can exhaustively search and benchmark kernels ahead of time, often finding the best configuration.
No runtime overhead: Models use pre-tuned kernels directly, leading to faster startup and inference.
Stable & predictable: Once tuned, the performance is deterministic and reliable across runs.
Therefore, offline GEMM tuning has been commonly used in performance sensitive scenarios in recent years. AMD provides various GEMM tuning solutions to developers and customers. AMD’s GEMM tuning ecosystem is centered on hipBLASLt, which supports offline pre-tuning via hipblaslt-bench. Frameworks like PyTorch ROCm expose this seamlessly through TunableOp, giving both developers and end users optimized GEMM performance without having to manually pick kernels. In the recent AITER library, AMD also provides the gradlib tool which determines the GEMM parameters that yield the best performance on the specific hardware currently in use.
Offline Tuning#
Offline GEMM tuning refers to a performance optimization technique used in high-performance computing and deep learning frameworks. It allows developers to select the best-performing kernel solution from the existing solution pool for a given GEMM problem size (M, N, K). During the tuning process, it evaluates candidate solutions and records the optimal solution index in a tuning result text file. At runtime, this index allows the corresponding kernel to be directly dispatched for the specified GEMM shape. The process includes:
Benchmarking a set of candidate GEMM solutions on target matrix shapes and types.
Profiling their execution times or throughput using synthetic or real data.
Selecting the best-performing solution.
Saving the result to a cache or file.
Loading the optimal solution at runtime without re-tuning.
Offline tuning avoids runtime overhead and ensures deterministic performance, which is especially important for large-scale deployments or real-time systems.
hipblaslt-bench#
hipBLASLt provides a command-line benchmarking tool hipblaslt-bench, which measures performance and to verify the correctness of GEMM operations on AMD GPUs using the hipBLASLt API. The hipblaslt-bench is the core of hipBLASLt offline GEMM tuning. Recently, hipblaslt-bench has added support for the swizzle GEMM kernel, which is a specialized GEMM kernel implementation that greatly improves performance.
Swizzle GEMM#
Swizzle GEMM refers to a matrix multiplication optimization technique where input or output tensor layouts are intentionally rearranged (swizzled) in memory to improve hardware efficiency. The term “swizzling” generally describes permuting or reordering data in a structured way, often to enhance:
Memory coalescing
Cache locality
Thread-level parallelism
Load balancing across compute units
hipblaslt-bench API#
The hipblaslt-bench has many options and parameters, which can affect the performance and speed of the offline GEMM tuning. Refer to the README for API details, and to this blog for more information on tuning with hipblaslt-bench.
There are some key parameters:
-m / -n / -k
Define the problem size (m, n, k) of the GEMM to be tuned.–lda / –ldb / –ldc / –ldd
Define the leading dimension of the matrix A/B/C/D.–a_type / –b_type / –c_type / –d_type
Define the datatype of the matrix A/B/C/D.–transA / –transB
Specify whether the matrix A/B is transposed or not.–cold_iters / –iters
The “cold_iters” indicate the warm-up iterations before starting measuring. The “iters” specifies the iteration number during measuring.–algo_method
Specify the search mode. Options are heuristic, all, index. Using “heuristic” method will perform heuristic searching for certain number of candidates and then tuning. The “all” method is like “heuristic” method but tuning on all solutions in solution pool. The “index” method will benchmark the performance of the solution with a certain index.–solution_index
Used with “—algo_method index”. Specify solution index to use in benchmark.–requested_solution
Used with “–algo_method heuristic”. Specify the number of candidates in tuning searching range. Set to -1 to get all solutions. Set to 1 to benchmark the original solution of the given problem size.–swizzleA
Enable swizzle GEMM, in which the memory layout of matrix A (weights) will be rearranged.
Workflow of QuickTune#
The QuickTune script developed by AMD Quark Team is a python script tool to help developers and customers to perform hipBLASLt offline tuning. The hipBLASLt offline tuning consists of steps including input log processing, parameters setup, tuning, output analysis. QuickTune enables developers and customers to significantly boost hipBLASLt GEMM performance with minimal time cost and little required expertise. All offline tuning steps can be completed in a single click by running a Python script. Each main step of hipBLASLt offline tuning can also be executed separately by QuickTune.
The workflow of QuickTune is shown in Figure 1 below.
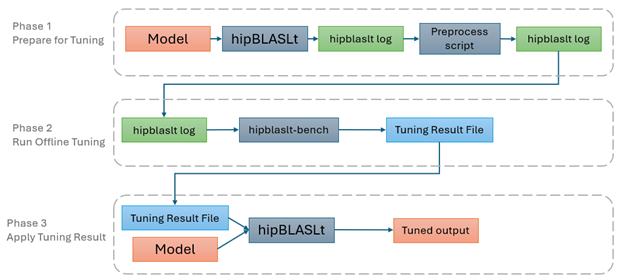
Figure 1. Flow of hipBLASLt offline tuning#
Before Tuning: Fetch Input hipBLASLt Log#
The hipBLASLt log is the input file of the QuickTune. Extracting the hipBLASLt log can be simply done by setting up the environment variables like below and then running the model.
export HIPBLASLT_LOG_MASK=32
export HIPBLASLT_LOG_FILE=<path/to/hipblaslt/log>
The hipBLASLt log file will be saved at the location of HIPBLASLT_LOG_FILE. It consists of the hipblaslt-bench command lines for each call of hipBLASLt GEMM kernel. The hipblaslt-bench command contains most of the required parameters for offline tuning. An example of hipBLASLt log is shown in figure 2.

Figure 2. hipblaslt log example#
Note: Please be aware that not all GEMM shapes will be collected in the hipblaslt log, only those GEMM that call the hipBLASLt kernel will be saved in the log.
Step 1: hipBLASLt log Remove Duplicate#
Since each hipBLASLt GEMM might be called many times when running the model, the hipBLASLt log contains many duplicate lines. The duplicate lines in the hipBLASLt log will be removed, and the parameters will be adjusted for baseline benchmark, and offline tuning w/o swizzle. Please check the README for details of hipblaslt-bench parameters.
python remove_duplicate.py
--input_file example/Qwen3_hipblaslt.log
--output_path tuning_test
Step 2: Tuning by One Click#
To run GEMM tuning with hipblaslt-bench on the Qwen3-32B model:
nohup python gemm_tuning.py --input_file example/Qwen3-32B_ali_hipblaslt.log --output_path test_tuning --requested_solution 128 --swizzleA > output.log 2>&1 &
input_file
The input_file refers to the hipBLASLt log with the GEMMs to be tuned. The duplicate lines in the log will be removed when running.output_path
The output_path refers to the directory defined by the user for saving the tuning result files.–swizzleA
Enabling swizzleA will rearrange the memory layout of matrix A to avoid bank conflict and boost the latency performance. To enable swizzle offline tuning, the transA also needs to be T.–requested_solution
The requested_solution defines the size of searching space for GEMM tuning. The default value of requested_solution is 128. To measure the baseline latency of the original kernel, just set the request solution to be 1. To expand searching space to the entire kernel library, just set the requested solution to be -1.–cold_iters and –iters
The “cold_iters” refers to the warm-up iteration, and the “iters” refers to the running iteration to measure kernel latency. The recommended value of cold_iters and iters will be: (200, 100) for relatively small GEMM (latency < 50 us) (50, 20) for medium GEMM (100 us < latency < 1000 us) (10, 2) for relatively large GEMM. (latency > 1000 us).–gpu_id
The gpu_id determines which GPU you choose to run GEMM tuning. It is recommended to use “rocm-smi” to find an idle GPU to run GEMM tuning for an accurate result, since the tuning is very latency sensitive.stablize_gpu
Enable stablize_gpu will provide a lower performance but more consistent GPU setting.
The tuning result will be saved at the location of the <output_path>/tuning.txt.
Step 3: Tuning Output Analysis#
To evaluate the performance gains from tuning, QuickTune generates a CSV file containing the baseline and tuned solution indices along with their corresponding latencies. It then calculates the improvement ratio based on this data.
Since the occurrences and latency percentages are different for each GEMM, the overall speedup of tuning cannot be simply represented by the average improvement ratio. We offer a script to help users to analyze the tuning result and calculate the overall speedup brought by GEMM tuning. The calculated overall speedup is only for hipBLASLt GEMMs, not the entire model.
python tuning_analysis.py --input_log <input hipblaslt log> --input_csv <tuning_csv> --output_csv <analysis csv file>
The analysis of tuning result is shown in Figure 3 below.
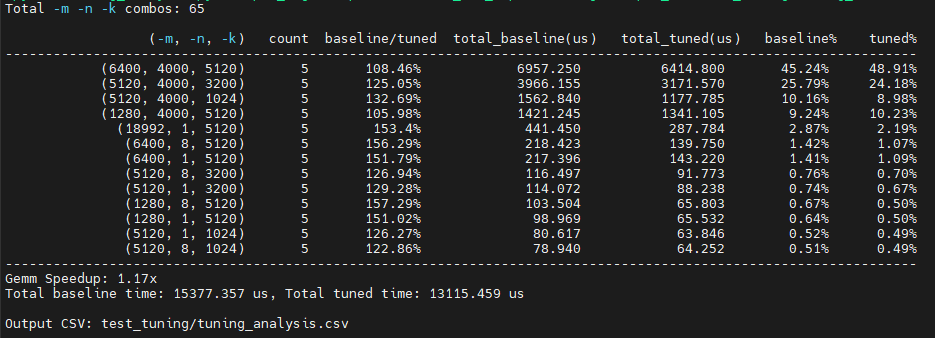
Figure 3. Analysis of Tuning Result#
After Tuning: Apply Tuning Result#
To apply the GEMM tuning result, you need to setup the environment variables as shown below and run the model again. With that the hipBLASLt will automatically pick the tuned kernel in the tuning result. The flow of applying the tuning result is shown in figure 4, below.
unset HIPBLASLT_TUNING_FILE
export HIPBLASLT_TUNING_OVERRIDE_FILE=<path/to/tuning/result>
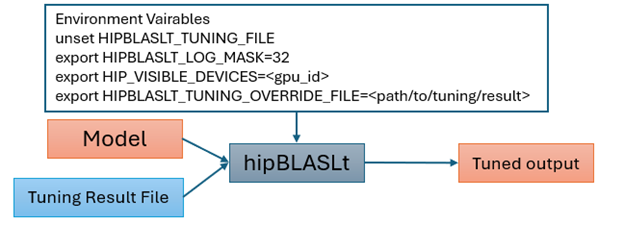
Figure 4. Flow for Applying the Tuning Result#
Optional Step: Verification#
Repeat phase 1 With the tuning result applied, run the model and collect the hipblaslt log. Check whether the solution index in the log matches with the tuning result file. If yes, the tuning result is successfully applied.
Example Offline Tuning for Qwen#
Let’s take the Qwen3-32B as an example and compare its baseline performance before tuning and performance after tuning w/o swizzle.
Table 1 below shows the latency data of hipBLASLt GEMM kernels in Qwen3-32B. Columns A, B, and C represent the (m,n,k) shapes of each GEMM. Column D lists the original latency before GEMM tuning. Columns E and G show the latency after applying hipBLASLt offline tuning w/o swizzling. Columns F and H show the ratio of the latency before offline tuning to the latency after offline tuning w/o swizzling — a larger value indicates better performance from offline tuning.
Table 1. Latency of hipBLASLt GEMM kernels in Qwen3-32B#
As shown in the table, the improvement from tuning without swizzling ranges from 100% to 139%. An improvement ratio of 100% means the tuning does not improve performance at all, which is normally seen when the original kernel selected for that GEMM is already the best-performing one within the search range. For GEMM tuning, a low ratio value does not necessarily mean that the tuning performance is poor—it may indicate that there is little room for further improvement for that GEMM. The performance of GEMM kernel has a roofline limit, and for kernels that are already highly optimized, the performance improvement from tuning will be very limited.
For offline tuning with swizzling, the improvement ratio is higher than tuning without swizzling for every GEMM shape. On average, offline tuning without swizzling yields a 110.43% improvement, while tuning with swizzling achieves 131.47%. We can conclude that swizzling is an effective optimization technique in GEMM tuning.
We also provide the end to end inference time data to show how hipBLASLt offline tuning improves the Qwen3-32B performance. As shown in Table 2, the end to end inference time before tuning is 9402.67 ms. After the offline tuning, the inference time has been improved to 8000.73 ms. The end to end performance of Qwen3-32B improves 14.91%.
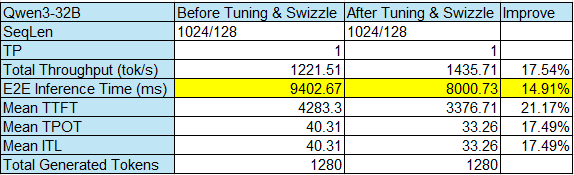
Table 2. End to End Performance of Qwen3-32B#
Information regarding the experimental environment is provided below to allow readers to reproduce this experiment:
HipBLASLt commit |
aed1757c26-dirty |
GPU card |
Mi308 |
Docker |
rtp-llm:rocm_6.4.1_hipblaslt_0.15_v2 |
Summary#
GEMM lies at the heart of large-scale AI workloads, and in LLMs like Qwen, it dominates both training and inference performance. This makes every optimization opportunity valuable. Through our exploration of hipBLASLt offline GEMM tuning, we’ve seen how tuning parameters—especially with advanced techniques like swizzling—can deliver substantial speedups.
The results highlight two key takeaways:
Offline tuning is an effective way to adapt GEMM performance to specific model shapes and hardware.
Swizzling consistently enhances tuning outcomes by improving memory access efficiency.
As models and hardware continue to evolve, systematic offline GEMM tuning will remain an essential tool for squeezing every drop of performance from GPU compute.
The previous blog post, hipblaslt offline tuning part 2 is recommended reading to learn more details about hipblaslt-bench.
Acknowledgement#
We would like to express our thanks to our colleagues Ethan Yang, Jiangyong Ren, Hang Yang, Yilin Zhao, Yu Zhou, Yu-Chen Lin, Jacky Zhao, Thiago Fernandes Crepaldi, Bowen Bao, AMD Quark Team, for their insightful feedback and technical assistance.