Engineering Qwen-VL for Production: Vision Module Architecture and Optimization Practices#

Vision–language models (VLMs) have rapidly evolved from research prototypes into foundational components of modern AI systems, enabling unified reasoning over images, videos, and text. As model scale and application complexity increase, the focus of VLM development has shifted from isolated benchmark performance toward architectural efficiency, multimodal alignment, and production readiness. Within this landscape, Qwen-VL stands out as a practical and extensible vision–language model that emphasizes modular visual encoding, flexible multimodal integration, and scalability in real-world deployments. Rather than treating vision as a peripheral add-on, Qwen-VL adopts a tightly integrated design that allows visual representations to participate deeply in language reasoning, making it particularly well suited for both large-scale inference and domain-specific customization.
To bring this capability into production, we deploy Qwen-VL on AMD Instinct™ MI308X GPUs, leveraging the ROCm open software ecosystem for optimized kernels and framework integration. Drawing on this deployment experience — developed in collaboration with enterprise customers — this blog covers four main aspects: first, an in-depth look at the architecture of the Qwen-VL visual module; second, a detailed examination of the interaction mechanism between the visual module and the LLM, with particular emphasis on how visual tokens are aligned, injected, and processed during multimodal inference; third, our practical optimization work on integrating Qwen-VL with the inference framework RTP-LLM; and fourth, a summary of representative commercial deployments of Qwen-VL in real-world production scenarios.
We place particular emphasis on the vision module of Qwen-VL and its interaction with the LLM module. While the language backbone itself has been extensively analyzed in existing literature and technical blogs, the visual component and its integration with the language model are often discussed at a much higher level of abstraction. To avoid redundancy, we do not revisit the internal design of the LLM in detail. Instead, we focus exclusively on the architecture and implementation details of the vision module. Other components of the model, including the language backbone and the interaction between the language model and the vision model, are not discussed in depth here and can be referred to in the official documentation.
Visual Module Architecture#
The official architecture diagram of the Qwen-VL visual module provides a high-level overview, but lacks sufficient implementation-level detail. Building on this, we conducted a thorough code-level analysis of the visual module and reconstructed a more detailed architecture diagram based on the Qwen3-VL-235B-A22B-Instruct model, which reflects the actual data flow, module boundaries, and design choices in the visual module implementation. The resulting architecture is shown in Figure 1.
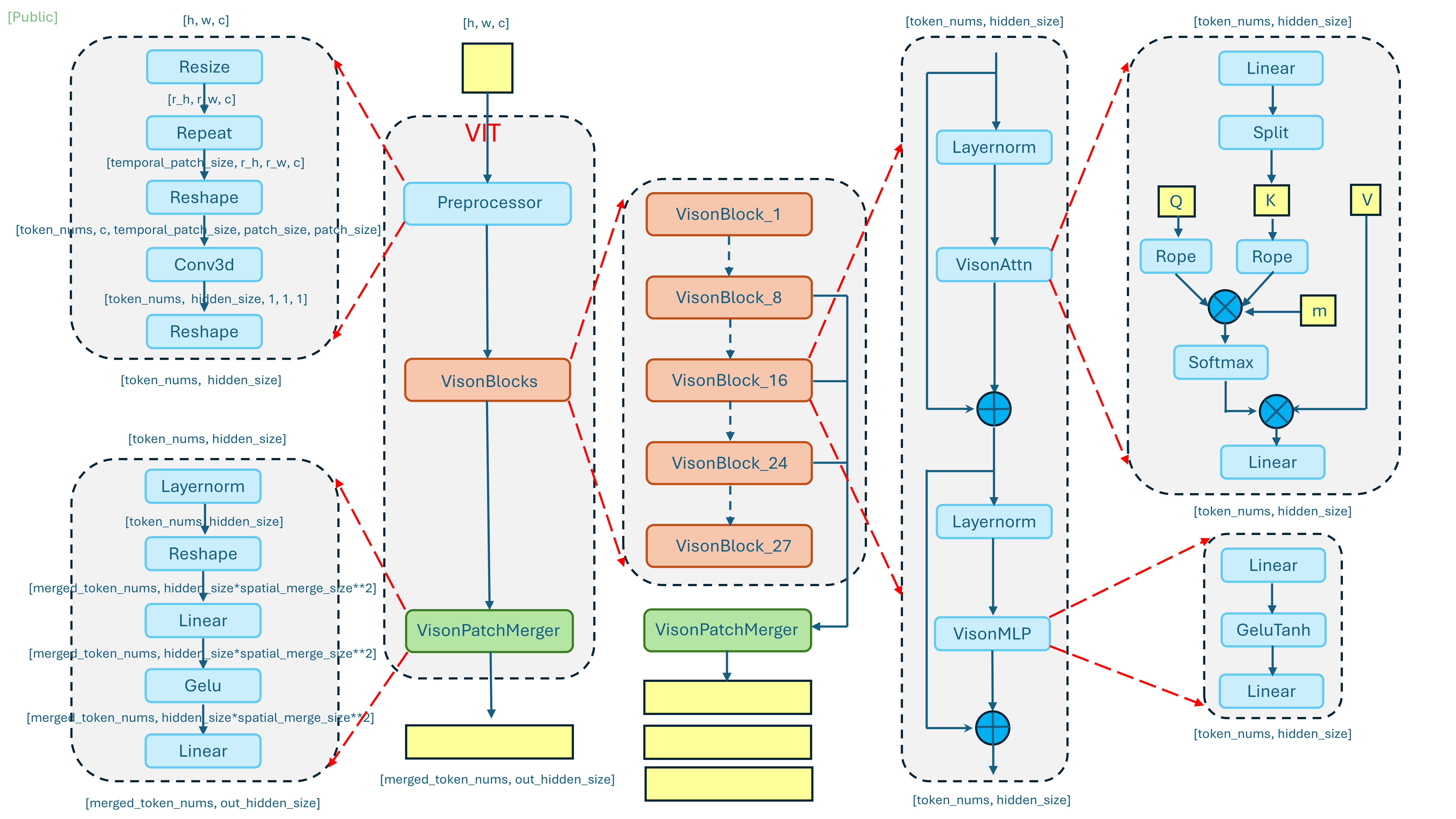
Figure 1. Detailed architecture of the visual module.#
The visual module of Qwen3-VL is designed as a three-stage processing pipeline, consisting of a preprocessor, a stack of vision blocks, and a patch merger. Together, these components transform raw visual inputs into compact, semantically rich representations that can be efficiently consumed by the language model.
Preprocessor#
The preprocessor is responsible for converting raw visual inputs—such as images or video frames—into a standardized tensor representation, as illustrated in Figure 2.
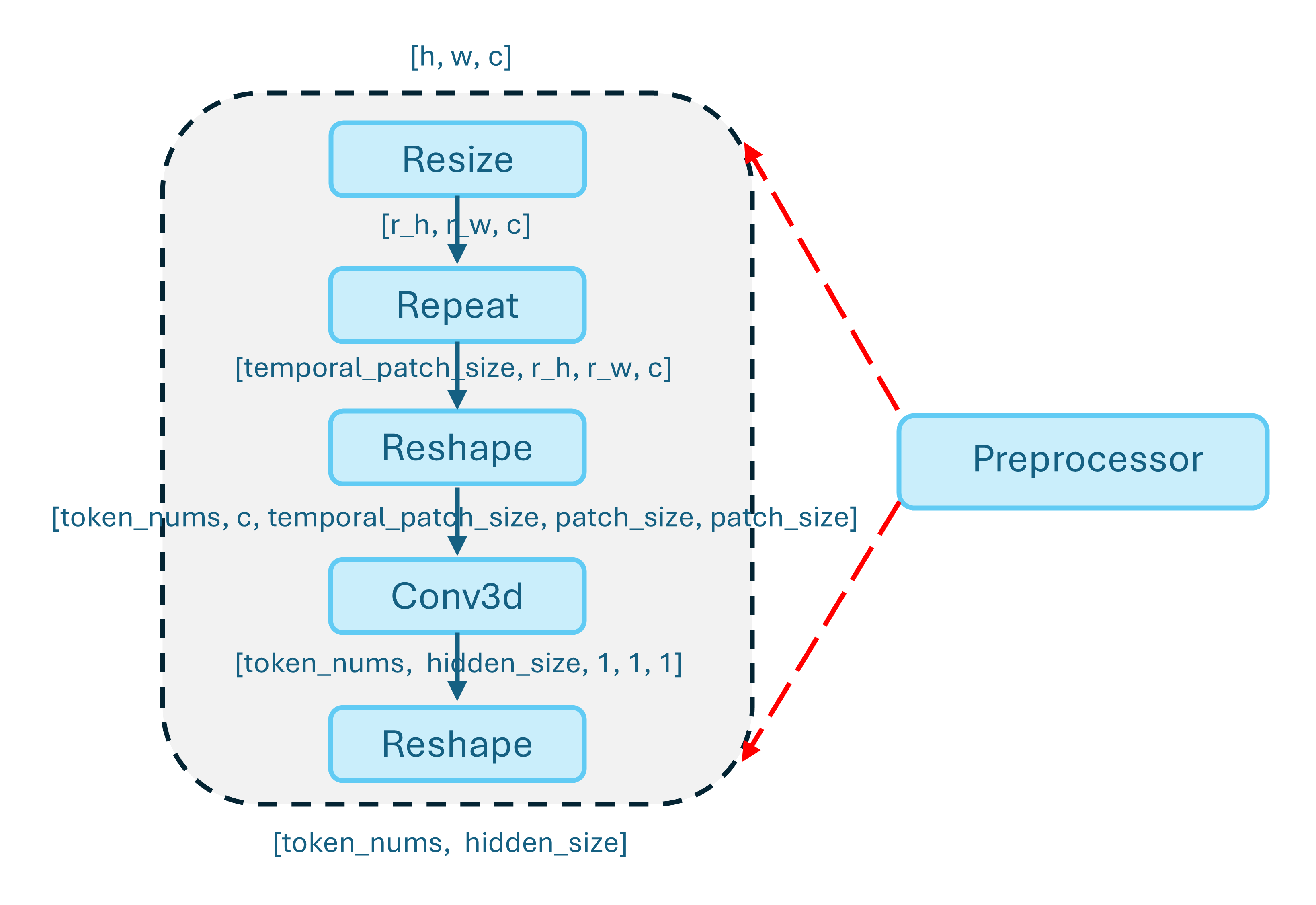
Figure 2. Architecture of the preprocessor.#
This stage handles input normalization, resizing, and patchification, ensuring that visual data conforms to the expected spatial resolution and channel layout. By performing these operations upfront, the preprocessor establishes a consistent token structure for subsequent vision blocks, regardless of input modality or source.
Vision blocks#
Following preprocessing, visual tokens are passed through a sequence of vision blocks that form the core of visual feature extraction, as shown in Figure 3.
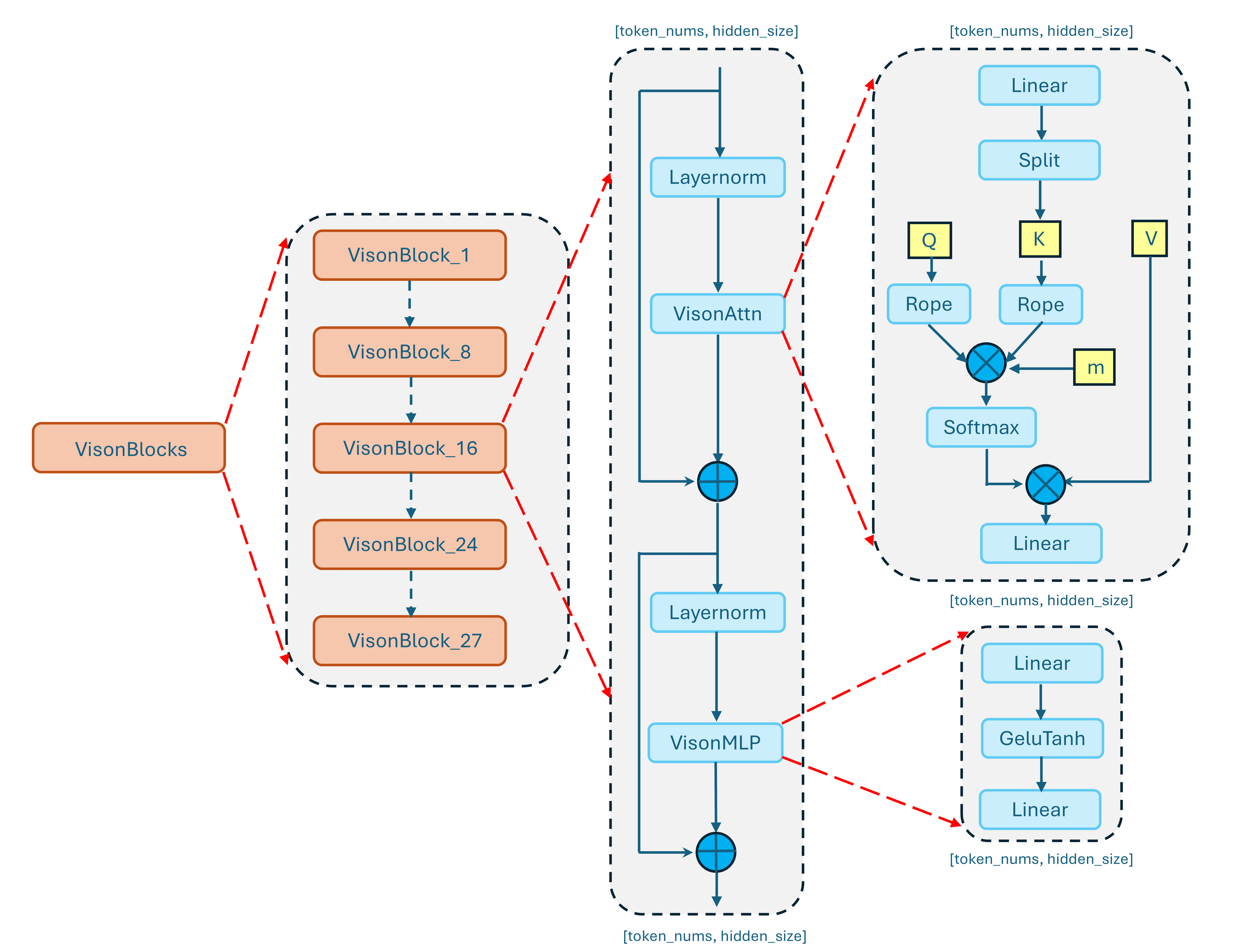
Figure 3. Architecture of the vision blocks.#
These blocks typically consist of multi-head self-attention and feed-forward layers, enabling the model to capture both local spatial patterns and global semantic relationships across patches. Through progressive transformation, the vision blocks refine low-level visual signals into higher-level representations that are aligned with downstream multimodal reasoning tasks.
Patch merger#
The patch merger serves as the interface between the visual encoder and the language model. Given the potentially large number of visual tokens produced by the vision blocks, this component reduces and aggregates patch-level features into a more compact representation. By merging spatially or semantically related patches, the patch merger effectively balances representational richness with computational efficiency, making large-scale multimodal inference practical in production settings. The detailed structure is shown in Figure 4.
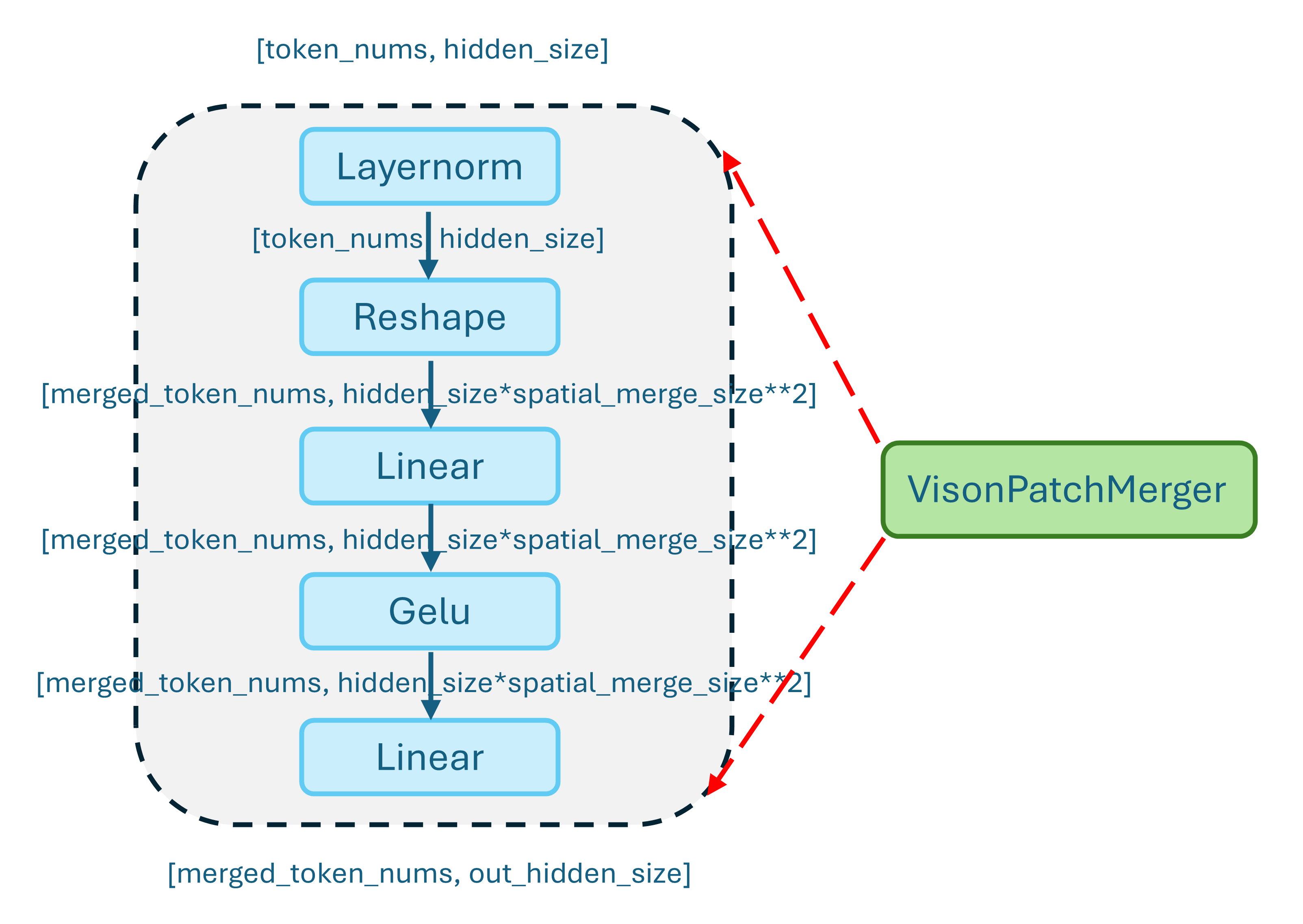
Figure 4. Architecture of the patch merger.#
Qwen-VL Engineering Optimization on MI308#
To fully leverage the computational characteristics of MI308, we conducted a series of targeted engineering optimizations when deploying Qwen-VL on RTP-LLM. These optimizations can be broadly categorized into two types: kernel replacement and kernel fusion, each addressing different performance bottlenecks observed in real-world inference workloads.
Kernel Replacement#
The first class of optimizations focuses on replacing hipified or framework-default kernels with hardware-aware implementations better suited to MI308. Our kernel replacement strategy primarily leverages the high performance kernel library AITER, which provides ROCm-optimized implementations tailored for AMD GPUs.
A representative example of kernel replacement in our MI308 optimization work is the substitution of the default torch.sdpa_attention operator in the visual module with a ROCm-optimized FlashAttention implementation. By switching to a ROCm-native FlashAttention kernel, we significantly improved memory efficiency and attention throughput, particularly for long-sequence and high-concurrency inference workloads.
# torch sdpaAttention
import torch.nn.functional as F
attn_output = F.scaled_dot_product_attention(q, k, v, attention_mask, dropout_p=0.0)
# rocm flashattention
from flash_attn import flash_attn_varlen_func
attn_output = flash_attn_varlen_func(q, k, v, cu_seqlens, cu_seqlens, max_seqlen, max_seqlen).reshape(seq_length, -1)
Benchmark (Qwen2.5-VL-72B-Instruct model, single attention operator):
Implementation |
Latency (µs) |
Speedup |
|---|---|---|
torch.sdpa_attention |
496.13 |
— |
flash_attn |
28.86 |
17.19× |
Key benefit: Switching to flash_attn reduces single-operator latency from 496.13 µs to 28.86 µs — a 17.19× speedup.
In addition to attention, normalization operators were another critical target for kernel replacement. Several normalization kernels that are automatically hipified from CUDA—such as LayerNorm and RMSNorm—exhibited noticeable performance overhead on MI308. To address this, we replaced these hipified implementations with highly optimized alternatives from the Aiter library, specifically rmsnorm2d and layernorm2d. These kernels are tailored for ROCm execution, offering better vectorization and reduced memory traffic, which translates into lower latency and more stable performance in normalization-heavy model components.
// Hipified rmsnorm kernel
DISPATCH_CUDA_FUNCTION_COMPUTE_QUANT_TYPES(
data_type,
quant_data_type,
invokeGeneralRmsNorm,
norm_output->data(),
input->data(),
gamma,
beta,
eps,
m,
n,
stream_,
nullptr, // scale
scales_ptr, // dynamic_scale
quant_output // out_quant
);
// Aiter rmsnorm kernel
#include "rmsnorm.h"
auto input_tensor = Buffer2torchTensor(input, false);
auto weight_tensor = Buffer2torchTensor(*norm_weight->get().gamma.get(), false);
auto res_tensor = rmsnorm2d(input_tensor, weight_tensor, static_cast<double>(eps), 0);
copy({*norm_output, *torchTensor2Buffer(res_tensor)});
Kernel Fusion#
One practical instance of this fusion optimization is the consolidation of RMSNorm and quantization into a single execution pass. In the original version, RMSNorm and the subsequent quantization step are executed as two independent operators. This separation introduces multiple inefficiencies: an intermediate tensor must be written back to global memory after normalization, reloaded for quantization, and processed again, resulting in redundant memory traffic and additional kernel launch overhead.
To eliminate this overhead, we implemented a fused kernel that performs normalization and quantization within the same execution context. Specifically, the kernel first computes the RMS statistics and applies normalization in registers or shared memory. Instead of materializing the normalized FP16/BF16 tensor in global memory, it directly proceeds to apply scaling and quantization (e.g., to INT8 or FP8 format), producing the final quantized output in a single pass.
// Fusion of rmsnorm and quantization
auto qout = std::dynamic_pointer_cast<QBuffer>(norm_output);
auto out_kernel_tensor = Buffer2torchTensor(qout->kernelPtr(), /*copyData=*/false); // [m,n], FP8/Byte
auto out_scale_tensor = Buffer2torchTensor(qout->scalesPtr(), /*copyData=*/false); // [m,1], FP32
rmsnorm2d_with_dynamicquant(
/*out=*/out_kernel_tensor,
/*input=*/input_tensor,
/*yscale=*/out_scale_tensor,
/*weight=*/weight_tensor,
/*epsilon=*/static_cast<double>(eps),
/*use_model_sensitive_rmsnorm=*/0);
Benchmark (Qwen2.5-VL-72B-Instruct model, RMSNorm + Quantization Stage):
Implementation |
Latency (µs) |
Speedup |
|---|---|---|
Separate RMSNorm + Quant |
32.36 |
— |
Fused rmsnorm2d_with_dynamicquant |
25.36 |
1.28× |
Key benefit: The fusion reduces the combined latency from 32.36 µs to 25.36 µs — a 1.28× speedup.
This fusion yields multiple performance benefits on MI308:
Reduced memory bandwidth pressure – intermediate normalized tensors are never written to or read from global memory.
Lower kernel launch overhead – two lightweight kernels are replaced with a single launch.
Improved data locality – normalization results remain in registers, minimizing memory round trips.
Better pipeline efficiency – particularly impactful in inference scenarios where normalization–quantization patterns appear repeatedly across layers.
End-to-End Inference Performance#
Inference Performance Comparison (Qwen2.5-VL-72B-Instruct model on MI308):
Metric |
Unoptimized |
Latest Optimized |
Speedup |
|---|---|---|---|
TTFT (ms) |
274.39 |
225.95 |
1.21× |
TPOT (ms/token) |
11.20 |
8.12 |
1.38× |
These individual kernel optimizations—such as FlashAttention replacement and RMSNorm + quantization fusion—collectively deliver substantial gains at the system level, resulting in a 1.21× speedup in TTFT and a 1.38× speedup in TPOT, significantly improving overall multimodal inference efficiency on MI308 hardware.
Qwen-VL In Production#
In commercial deployments, Qwen-VL has been applied to high-impact, real-world scenarios that demand both scale and robustness. Qwen-VL was integrated into a domain-specific information retrieval application deployed on a large-scale consumer browser platform, providing multimodal assistance to a broad user base through image and text understanding in time-sensitive query workflows. Beyond end-user applications, Qwen-VL is also widely used for large-scale data enrichment, where it powers automated processing and labeling pipelines for massive image and video corpora. These capabilities enable efficient corpus “refreshing” and quality improvement, supporting downstream model training, evaluation, and content understanding tasks across multiple business domains.
Summary#
This blog presented a detailed look at the Qwen-VL vision module architecture and a series of engineering optimizations for AMD Instinct™ MI308X GPUs using the ROCm ecosystem. Through targeted kernel replacements — such as switching to ROCm-native FlashAttention (17× single-operator speedup) — and kernel fusions like RMSNorm + quantization (1.28× speedup), we achieved a 1.21× improvement in TTFT and a 1.38× improvement in TPOT on end-to-end inference with the Qwen2.5-VL-72B model. These optimizations have been validated in real-world production deployments at scale.
Looking ahead, we plan to introduce vision encoder data parallelism to better scale multi-image and multi-video inference workloads, and to extend our optimization practices to Qwen3-Omni for unified audio-vision-language multimodal inference on AMD Instinct™ GPUs. Stay tuned for upcoming blogs with deeper dives into these topics.
Acknowledgements#
This blog post summarizes collaborative efforts from members of the AMD Quark team, the AMD AI Framework team, the Alibaba Tech Infra and Reliability Engineering team, and the Alibaba Cloud Sinian Heterogeneous Computing team. We would like to express our sincere thanks to all contributors for their valuable insights, optimizations, and ongoing support.
Additional Resources#
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.