ROCm Revisited: Evolution of the High-Performance GPU Computing Ecosystem#

This blog is part of our ROCm Revisited series[1]. The purpose of this series is to share the story of ROCm and our journey through the changes and successes we’ve achieved over the past few years. We’ll explore the key milestones in our development, the innovative technologies that have propelled us forward, and the challenges we’ve overcome to establish our leadership in the world of GPU computing.
In this blog post, we aim to highlight AMD’s ROCm ecosystem and the evolution of the software stack throughout the years. We will explore the key features, tools, and concepts included in ROCm as well as some of the highs and lows along the journey. One notable example was that originally ROCm was referred to as Radeon Open Compute (ROCm), but was shortened to just ROCm. From dropping the HCC compiler, the closer CUDA compatibility, and the expansion of ROCm’s scope across multiple verticals and technologies, ROCm has gone through many exciting changes and advancements to what it is today.
The ROCm ecosystem can be partitioned into four distinct groups all built to harness the power of AMDs Instinct GPUs and APUs (see Figure 1, below). The ROCm ecosystem is built on a foundation of AMD Instinct GPUs and APUs, as shown in the first layer of the diagram. Moving onto the software ecosystem, at the base lies the Instinct System Software that will interact with the GPU/APU and firmware managing scheduling, orchestration, drivers, and validation. Above that is the ROCm Core Toolkit, consisting of the libraries, runtimes, compilers, and dev tools. At the top are the last two groups being the partner ecosystem with large AI/ML frameworks and expansion toolkits such as ROCm-DS diving into data science applications. The expansion toolkits will continue to grow as ROCm expands its scope to more applications and technology verticals.
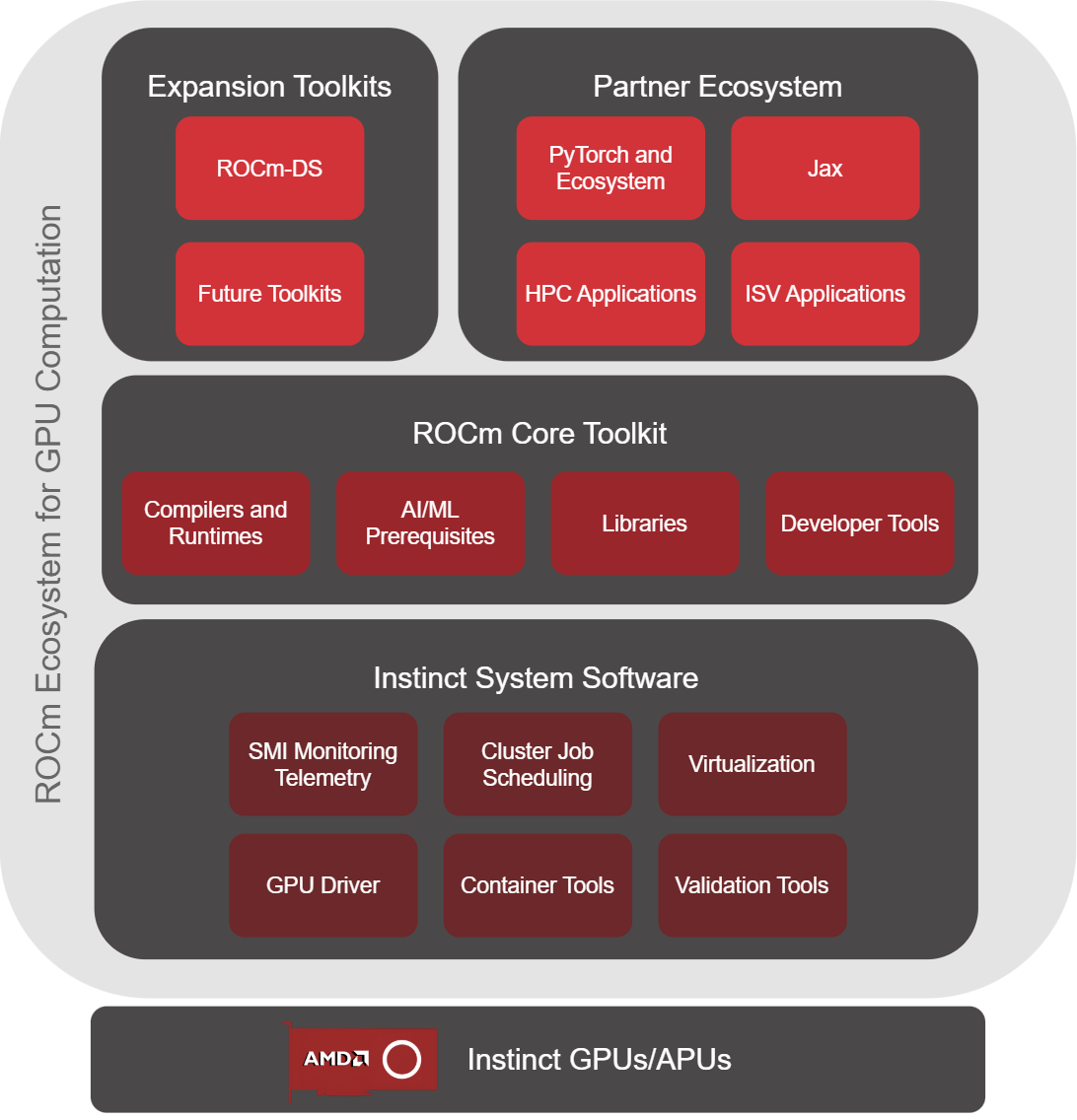
Figure 1: The ROCm ecosystem and its components.#
Compilers and Runtimes#
At the core of ROCm’s performance is its compiler and runtime stack, anchored by the Heterogeneous-Computing Interface for Portability (HIP). HIP is a C++ runtime API and kernel language for portable GPU-accelerated code.
A major milestone was the transition from the Heterogeneous-Compute Compiler (HCC) to HIP-Clang. HCC was designed to enable efficient parallel programming for AMD GPUs and CPUs but was deprecated to focus on HIP, leveraging the LLVM ecosystem for better compatibility, maintainability, and optimization, such as kernel fusion and memory coalescing, which are crucial for AI and HPC workloads. With HIP-Clang, AMD has made significant contributions to the LLVM project, upstreaming ROCm-related enhancements and features. This ensures that ROCm’s compiler technology benefits from the latest advancements from the LLVM project while also making AMD’s GPU support available and sustainable within the open-source ecosystem.
The LLVM ecosystem comprises a suite of modular, reusable compiler and toolchain components. It provides a flexible infrastructure for building, optimizing, and targeting code across multiple architectures, enabling ROCm to leverage industry-standard tools for improved compatibility and performance.
HIPCC, the original compiler driver, showcased HIP’s portability but is being phased out in favor of direct Clang workflows, reducing abstraction and improving maintainability. While this transition introduces short-term challenges for developers used to HIPCC, it aligns ROCm with open-source toolchains and supports long-term growth. These compiler and runtime improvements have solidified ROCm’s foundation for scalable, high-performance GPU computing. To learn more consult the ROCm tools, compilers, and runtimes[2] page.
Libraries#
ROCm’s libraries are foundational to its ecosystem, delivering optimized, ready-to-use algorithms for rapid GPU application development. These libraries, tailored for high-performance computing (HPC) and AI, fall into four main categories:
Machine Learning & Computer Vision:
Composable Kernel,MIGraphX,MIOpen,MIVisionX,rocAL,rocDecode,rocPyDecode,rocJPEG,RPPCommunication:
RCCL,rocSHMEMMath:
hipBLAS,hipBLASLt,hipFFT,hipfort,hipRAND,hipSOLVER,hipSPARSE,hipSPARSELtC++ Primitives:
hipCUB,hipTensor,rocPRIM,rocThrust
ROCm libraries evolve to meet developer needs. For example, the recent addition of rocDecode (ROCm 6.1) enables efficient video stream decoding directly on the GPU, minimizing PCIe data transfers and streamlining post-processing with HIP. To learn more about specific libraries you can explore the ROCm libraries[3] page under the ROCm documentation.
Developer Tools#
ROCm offers a comprehensive suite of tools for profiling, debugging, and system management, all bundled in the ROCm SDK. The SDK streamlines installation and supports containerized, bare-metal, and virtualized environments. Since ROCm 6.4, the SDK and Instinct GPU driver are modular, allowing flexible deployment. Modular architecture gives developers the option to deploy only the components relevant to their workflows, simplifying setup and improving maintainability.
Key tools include:
Profiling: ROCprofiler-SDK and
rocprofv3for GPU execution, memory, and API tracing.Debugging:
ROCdbgapiandROCgdbfor low-level GPU state access and source-level debugging.Portability: HIPIFY for CUDA-to-HIP code conversion and CMake modules for platform-agnostic builds.
System Management: AMD SMI (monitoring/control), rocminfo (system/GPU topology), and ROCm Validation Suite (hardware validation).
These tools have matured alongside ROCm, supporting multi-GPU and cluster deployments, and simplifying GPU management. Collectively, they empower developers to efficiently build, optimize, and maintain high-performance GPU applications, reflecting ROCm’s evolution and commitment to modern HPC and AI workloads. Refer to the ROCm tools documentation[2] for further details.
Drivers, Scheduling, and Deployment Models#
Efficient GPU scheduling and robust driver support are essential for ROCm’s high performance and reliability. The ROCm Instinct driver bridges the OS and AMD GPUs, exposing features like multi-GPU support, peer-to-peer communication, and resource management.
ROCm supports GPU partitioning and resource isolation to ensure fair access and maximize throughput. For distributed workloads, ROCm enables high-bandwidth networking (RDMA, InfiniBand) and integrates with orchestration platforms like Kubernetes. Tools such as Omnistat Profiler, the AMD GPU Operator, and Device Metrics Exporter automate GPU management and scaling in clusters.
ROCm supports diverse deployment models tailored to specific performance and infrastructure needs:
Bare Metal: Direct installs maximize hardware use, with support for Infinity Fabric/PCIe, GPU partitioning, and isolation.
Virtualization: Instinct Virtualization Drivers, GPU passthrough, and virtual GPUs enable workloads in virtual machines, with AMD SMI for monitoring.
Containers: Kubernetes and ROCm orchestration tools support dynamic GPU allocation and workload balancing in containerized/cloud environments.
With robust drivers, flexible scheduling, and comprehensive management, ROCm enables scalable, high-performance GPU solutions for HPC and AI—across bare metal, virtualized, and containerized deployments. You can learn more about the Instinct system software from the Instinct GPU documentation[4].
Expansion Toolkits#
A significant recent addition to the ROCm ecosystem is the introduction of expansion toolkits designed to address emerging workloads and developer needs. The first of these is ROCm-DS[5] (ROCm Data Science), a toolkit focused on accelerating data science workflows on AMD GPUs. ROCm-DS brings together optimized libraries and tools for data preprocessing, analytics, and machine learning, making it easier for data scientists and engineers to leverage GPU acceleration in their pipelines. See our recent blog post on ROCm-DS: GPU Accelerated Data Science for AMD Instinct GPUs[6] for more information.
Data scientists benefit from ROCm’s acceleration of popular Python and R libraries. With ROCm-DS, libraries such as NumPy, Pandas, and GPU-accelerated frameworks like CuPy and RAPIDS AI can process large datasets faster, enabling rapid prototyping and analysis. This makes ROCm a compelling choice for data wrangling, machine learning pipelines, and exploratory analytics.
Looking ahead, AMD is committed to expanding the ROCm toolkit portfolio to cover a broader range of domains and applications. Future toolkits are expected to target areas such as computer vision, natural language processing, and simulation, providing developers with specialized, high-performance building blocks for their projects. More specifically, AMD is developing HPC communication toolkits with OpenMPI builds validated and tested with the ROCm core toolkit.
Beyond these core areas, ROCm’s compatibility continues to grow—supporting frameworks in fields such as computer vision and natural language processing. The open-source nature of ROCm encourages community-driven integrations, ensuring that new technologies and verticals are quickly adopted.
Partner Ecosystems#
ROCm’s partner ecosystem has grown to encompass a wide range of frameworks and applications, enabling developers to harness AMD GPUs for diverse workloads in AI, HPC, and beyond.
ROCm provides robust support for leading machine learning frameworks, including PyTorch and JAX. These integrations allow researchers and engineers to train and deploy models efficiently on AMD hardware, with features like mixed-precision training, optimized memory management, and seamless multi-GPU scaling. The ROCm team collaborates closely with framework maintainers to ensure upstream compatibility, rapid adoption of new features, and performance parity with other platforms. As a result, users benefit from a streamlined experience when developing and deploying AI workloads on AMD GPUs.
Beyond core frameworks, ROCm partners with Independent Software Vendors (ISVs) and the open-source community to enable popular HPC and simulation applications. Key workloads such as LAMMPS, GROMACS, and NAMD are optimized for ROCm, empowering scientists in computational chemistry, physics, and engineering to accelerate their research. Additional simulation and modeling applications supported by ROCm can be found in the instinct documentation[7] site including Ansys Fluent, DevitoPRO, ECHELON, and more.
ROCm’s parallel processing capabilities shine in computationally intensive simulations. Applications in quantum mechanics, computational fluid dynamics, and biomedical research are now optimized for AMD GPUs via ROCm, with new toolkits expected to support these applications in the future.
This expanding partner ecosystem ensures that ROCm users benefit from a rich set of tools and applications, whether building custom AI models, running large-scale simulations, or deploying ISV solutions in production environments. To see the supported frameworks and their documentation you can take a look at the ROCm compatibility matrix[8].
Summary#
Since its initial launch, ROCm has evolved into a comprehensive, high-performance computing ecosystem—offering robust compilers, optimized libraries, powerful developer tools, flexible scheduling, and broad application support. This journey reflects AMD’s commitment to empowering developers and researchers with scalable, open-source GPU solutions for AI, HPC, and beyond. Explore what else ROCm has to offer by looking through the ROCm documentation[9]. To continue learning about ROCm’s evolution and ecosystem, be sure to follow upcoming posts on the ROCm Revisited series[1].
Updated on 09 June 2025
Changed the names of the profiling tools from deprecated products to actively supported products.
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.