Accelerating Multimodal Inference in vLLM: The One-Line Optimization for Large Multimodal Models#

Deploying multimodal models like Qwen3-VL or InternVL at scale reveals a hidden bottleneck. While Tensor Parallelism (TP) is essential for massive language decoders, it is often overkill for vision encoders. These encoders are typically small, often just 1-5% of total model size, so there is limited compute benefit from sharding them. However, they still incur expensive all-reduce communication costs after every single layer.
vLLM was the first to introduce a hybrid parallelism strategy for multimodal models on a single node: the ViT Data Parallel + LLM Tensor Parallel approach [1], where the vision encoder runs with Data Parallelism (DP) across GPUs while the language model uses tensor parallelism. This hybrid strategy dramatically reduces TTFT and improves overall throughput. The approach has since proven its effectiveness and been adopted by other serving frameworks, such as SGLang.
Enter vLLM’s Batch-Level Data Parallelism (--mm-encoder-tp-mode data). This simple configuration switch changes the paradigm. Rather than sharding the encoder, it replicates the lightweight weights across GPUs and load-balances the input batch instead. Each GPU processes different images independently, eliminating communication overhead during the vision forward pass entirely.
In this blog, we explain when and why to enable batch-level DP, benchmark the performance across different architectures on AMD Instinct™ MI300X, and clarify how this optimization complements your existing parallelism strategy.
You will see benchmark results and learn the one key tradeoff: slightly higher memory usage in exchange for substantially better throughput and latency. If you are running multimodal models with tensor_parallel_size ≥ 4, this optimization deserves your attention. It is the definition of high-ROI engineering: a one-line change that can unlock significant performance gains.
Note
Scope: This blog focuses primarily on single-node deployment (typically 8 GPUs connected via AMD Infinity Fabric™ technology or xGMI).
What is a Multimodal Model?#
Multimodal models process multiple types of input—such as text, images, audio, or video—within a single unified architecture, typically combining specialized encoders for each modality with a language model that generates text responses.
For this blog, we focus specifically on vision-language models that accept image inputs alongside text prompts, such as Qwen3-VL and InternVL. These models use a vision encoder to transform images into embeddings that the language model can understand.
How Batch-Level DP Works: Architecture Overview#
To understand why batch-level DP improves performance, let’s first clarify the two fundamental parallelism strategies and how they apply to multimodal encoders.
Tensor Parallelism (TP)#
Tensor Parallelism shards model weights across multiple GPUs. Each GPU holds a portion of the weight matrices and performs computation on its shard. After each layer’s forward pass, GPUs communicate via all-reduce operations to synchronize results before proceeding to the next layer. In vLLM, TP is controlled by the --tensor-parallel-size flag, which applies to the language model by default.
Data Parallelism (DP)#
Data Parallelism takes the opposite approach: each GPU holds a complete copy of the model weights but processes different subsets of the input batch (controlled by the --data-parallel-size flag).
Batch-Level DP for Vision Encoders#
By default, vLLM applies TP uniformly across both the vision encoder and language model—encoder weights are sharded across GPUs just like the language model weights (controlled by --mm-encoder-tp-mode weights, which is the default, as shown in Figure 1). When you set --mm-encoder-tp-mode data, vLLM switches the vision encoder to batch-level DP (see Figure 2) [2]:
Vision Encoder: Each GPU maintains a full copy of the encoder weights and processes a different slice of the image batch in parallel. No all-reduce synchronization during encoding—each GPU independently transforms its assigned images into embeddings.
Language Model: Continues using standard TP to shard weights across prefill and decode phases, unchanged by the encoder setting.
This hybrid approach leverages the best of both strategies: DP for the lightweight encoder (where communication overhead would outweigh compute gains from parallelization) and TP for the massive language model (distributing compute and memory requirements).

Figure 1: Default Data flow when Multimodal Encoder is in standard TP mode#

Figure 2: Default Data flow when Multimodal Encoder is in Batch-level DP mode#
|
|
|
|---|---|---|
Encoder weight distribution |
Sharded across TP ranks |
Replicated on each TP rank |
Input batch processing |
Full batch on each rank |
Batch divided across TP ranks |
Inter-GPU communication |
All-reduce after every layer |
None during forward pass |
Memory per GPU |
Lower (weights sharded) |
Slightly higher (weights replicated) |
Language weight distribution |
TP (unchanged)* |
TP (unchanged)* |
*The language model’s parallelism strategy is controlled independently by --tensor-parallel-size, --data-parallel-size, and --enable-expert-parallel flags [3]. The --mm-encoder-tp-mode flag only affects how the vision encoder processes inputs and does not change the language model’s parallelism configuration.
Enabling Batch-Level DP for Multimodal Encoders#
Activating batch-level data parallelism for your vision encoder simply requires a single parameter change.
Setting the Flag#
Pass --mm-encoder-tp-mode data when starting your vLLM API server:
vllm serve Qwen/Qwen3-VL-235B-A22B-Instruct \
--tensor-parallel-size 8 \
--enable-expert-parallel \
--mm-encoder-tp-mode data
The language model continues using standard TP to shard its weights across prefill and decode, while the vision encoder now processes batched inputs in parallel across TP ranks.
Prerequisites#
Before enabling this optimization, ensure your setup meets the conditions to actually benefit from it.
Model support: Your model must implement batch-level DP at the code level by setting supports_encoder_tp_data = True in the model class. Currently supported models include:
Qwen3-VL series
InternVL series
step3
If your model isn’t in this list, the flag won’t activate the optimization—standard TP behavior continues as the fallback.
Memory headroom: As a general best practice, verify you have sufficient GPU memory headroom before enabling this feature. While vision encoders are lightweight compared to language models, their weights are replicated across each TP rank rather than sharded, leading to a slight increase in memory consumption.
Benchmark Results: Strategy Performance#
Let’s see how batch-level DP performs compared to the standard TP of the vision encoder.
Test Configuration#
Hardware:
GPU: 8× AMD Instinct™ MI300X GPUs (gfx942)
CPU: 2 × AMD EPYC™ 9654 96-Core Processor
Software stack:
ROCm Driver: 6.10.5 (AMDGPU)
Container: rocm/vllm-dev (ROCm 7.1.25424-4179531dcd)
vLLM: 0.11.2.dev69+g3fb0d9099
PyTorch: 2.9.0a0+git1c57644 (ROCm 7.1.25424-4179531dcd)
Benchmark configuration:
Text input sequence length (
--random-input-len): 256Text output sequence length (
--random-output-len): 128Number of images per request (
--random-mm-base-items-per-request): [1, 3, 10]Image size (
--random-mm-bucket-config): [256×256, 512×512, 1024×1024], uniform probabilitySeed: 0 (for reproducibility)
Dataset: random-mm
Workload: 640 total requests
Concurrency: 64 requests
Maximum number of tokens per iteration (
--max-num-batched-tokens): 8192
Model Specifications#
We tested three popular multimodal models:
Qwen3-VL-235B-A22B-Instruct
InternVL3_5-241B-A28B
step3
Model |
Vision encoder params |
LLM params |
Total params |
Vision % |
|---|---|---|---|---|
Qwen3-VL-235B-A22B-Instruct |
0.4B |
235B |
235.4B |
0.2% |
InternVL3_5-241B-A28B |
5.5B |
235.1B |
241.6B |
2.3% |
step3 |
5B |
316B |
321B |
1.6% |
Key observation: Vision encoders represent only 0.2-2.3% of the total model parameters, making them candidates for data parallelism without significant memory overhead.
Results Summary#
Model |
Image Size |
Items/Req |
Request throughput for TP Mode (req/s) |
Request throughput for DP Mode (req/s) |
Gain (%) |
|---|---|---|---|---|---|
Qwen3-VL-235B-A22B-Instruct |
256px |
1 |
6.59 |
6.99 |
+6.0% |
256px |
3 |
4.88 |
4.83 |
-1.0% |
|
256px |
10 |
2.22 |
2.22 |
+0.1% |
|
512px |
1 |
6.81 |
6.85 |
+0.6% |
|
512px |
3 |
3.89 |
4.64 |
+19.2% |
|
512px |
10 |
2.04 |
2.01 |
-1.5% |
|
1024px |
1 |
4.43 |
5.19 |
+17.1% |
|
1024px |
3 |
2.57 |
2.66 |
+3.4% |
|
1024px |
10 |
0.83 |
0.93 |
+11.6% |
|
step3 |
256px |
1 |
5.37 |
6.33 |
+17.8% |
256px |
3 |
2.38 |
2.62 |
+10.3% |
|
256px |
10 |
0.85 |
0.93 |
+9.0% |
|
512px |
1 |
4.81 |
6.40 |
+33.1% |
|
512px |
3 |
2.01 |
2.89 |
+43.6% |
|
512px |
10 |
0.84 |
0.88 |
+4.6% |
|
1024px |
1 |
1.77 |
2.03 |
+14.7% |
|
1024px |
3 |
0.71 |
0.73 |
+2.6% |
|
1024px |
10 |
0.22 |
0.22 |
-0.3% |
|
InternVL3_5-241B-A28B |
256px |
1 |
9.30 |
9.84 |
+5.8% |
256px |
3 |
4.45 |
5.11 |
+14.6% |
|
256px |
10 |
1.56 |
1.72 |
+10.0% |
|
512px |
1 |
9.19 |
9.72 |
+5.9% |
|
512px |
3 |
4.46 |
5.29 |
+18.4% |
|
512px |
10 |
1.58 |
1.70 |
+7.3% |
|
1024px |
1 |
2.54 |
3.03 |
+19.6% |
|
1024px |
3 |
0.94 |
1.24 |
+32.5% |
|
1024px |
10 |
0.30 |
0.43 |
+44.9% |
Trend Analysis#
Impact of Vision Encoder Size#
Model |
Encoder Size |
Encoder % |
Avg Gain in request throughput for DP Mode |
Consistency |
|---|---|---|---|---|
step3 |
5.0B |
1.6% |
+15.0% |
High (8/9 positive) |
InternVL3_5-241B-A28B |
5.5B |
2.3% |
+17.7% |
Very High (9/9 positive) |
Qwen3-VL-235B-A22B-Instruct |
0.4B |
0.2% |
+6.2% |
Low (7/9 positive) |
Trend: Models with larger vision encoders (>1% of total parameters) show more substantial and consistent DP mode benefits (step3: +15.0%, InternVL3_5-241B-A28B: +17.7%). For models with very small encoders (<0.5% like Qwen3-VL-235B-A22B-Instruct), gains are marginal (+6.2%), because the encoder’s computational workload is insufficient to fully benefit from DP’s parallelization advantages.
Impact of Image Size#
Image Size |
Avg Gain in request throughput for DP Mode |
Range |
Negative Results |
Best Case |
|---|---|---|---|---|
256px |
+8.1% |
-1.0% to +17.8% |
1/9 configs |
step3 @ 1 item (+17.8%) |
512px |
+14.6% |
-1.5% to +43.6% |
1/9 configs |
step3 @ 3 items (+43.6%) |
1024px |
+16.2% |
-0.3% to +44.9% |
1/9 configs |
InternVL3_5-241B-A28B @ 10 items (+44.9%) |
Trend: DP benefit scales with image size (256px: +8.1% → 512px: +14.6% → 1024px: +16.2%), as larger images provide more encoder computation to parallelize. Consistency remains high across all sizes (8/9 positive), with best-case gains reaching up to +44.9% at 1024px.
Impact of Items Per Request#
Items/Req |
Avg Gain in request throughput for DP Mode |
Range |
Negative Results |
Best Case |
|---|---|---|---|---|
1 |
+13.4% |
+0.6% to +33.1% |
0/9 configs |
step3 @ 512px (+33.1%) |
3 |
+16.0% |
-1.0% to +43.6% |
1/9 configs |
step3 @ 512px (+43.6%) |
10 |
+9.5% |
-1.5% to +44.9% |
2/9 configs |
InternVL3_5-241B-A28B @ 1024px (+44.9%) |
Trend: DP benefit peaks at 3 items/request (+16.0%), with lower gains at 1 item (+13.4%) and 10 items (+9.5%). Single-item requests show perfect consistency (0/9 negative), while 10 items/request has more variability (2/9 negative).
Why Does DP Mode Help?#
Reduced Communication Overhead: The key difference lies in synchronization frequency during the vision encoder forward pass.
TP mode (see Figure 3):
All-reduce follows the row-parallel linear projection to synchronize results across tensor parallel ranks
All-reduce occurs twice per vision block: after attention output projection + after MLP down projection
Additional all-reduces for merger layers (deepstack feature used in Qwen3-VL-235B-A22B-Instruct)
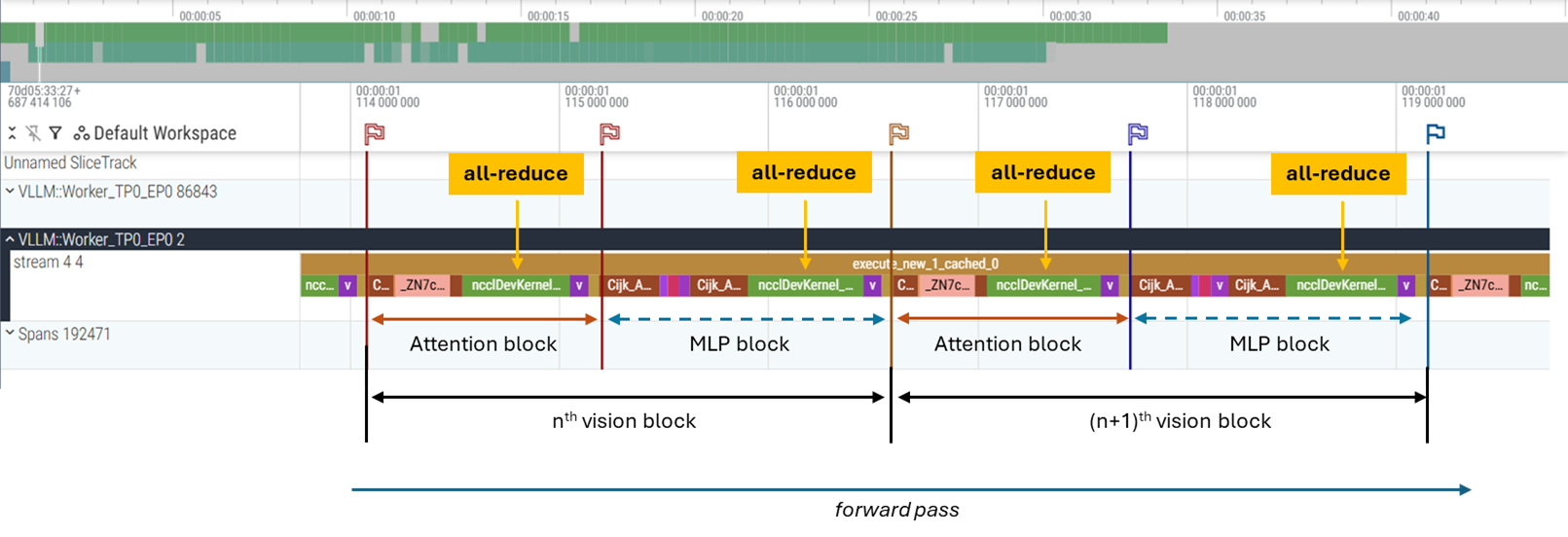
Figure 3: TP mode trace#
DP mode:
Zero communication during forward pass—each DP rank processes its batch slice independently (see Figure 4)
All-Gather follows the vision encoder forward pass to collect results across DP ranks (see Figure 5)
Single synchronization point at the end
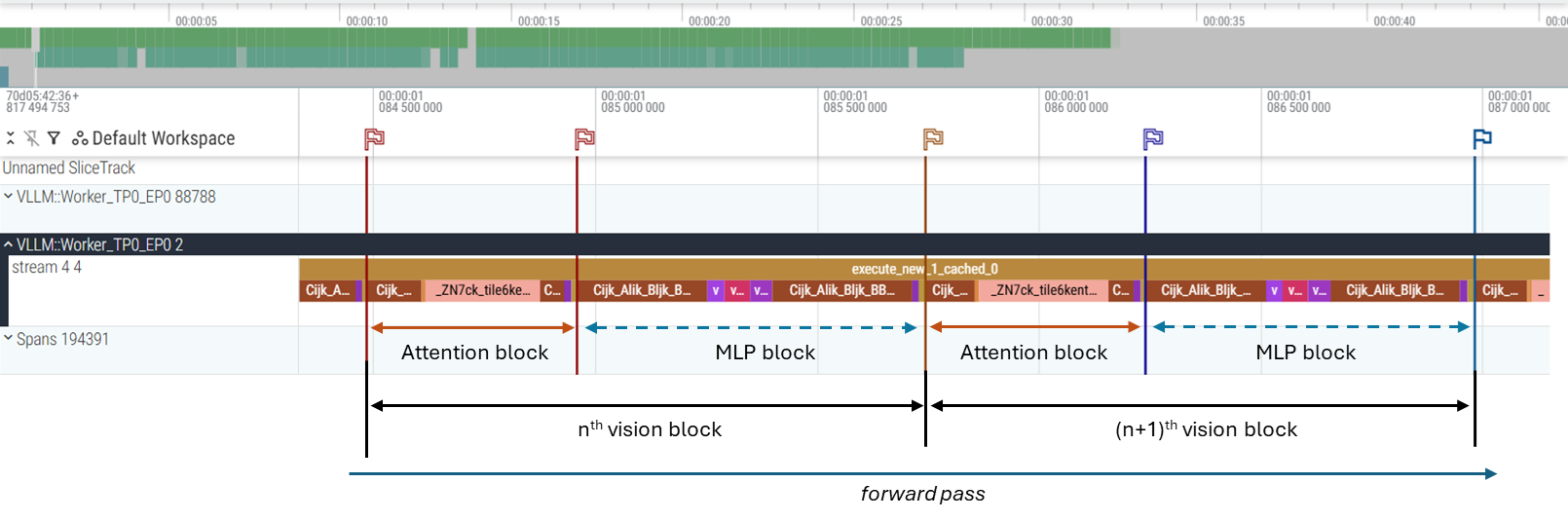
Figure 4: DP mode trace during forward pass – no communications#
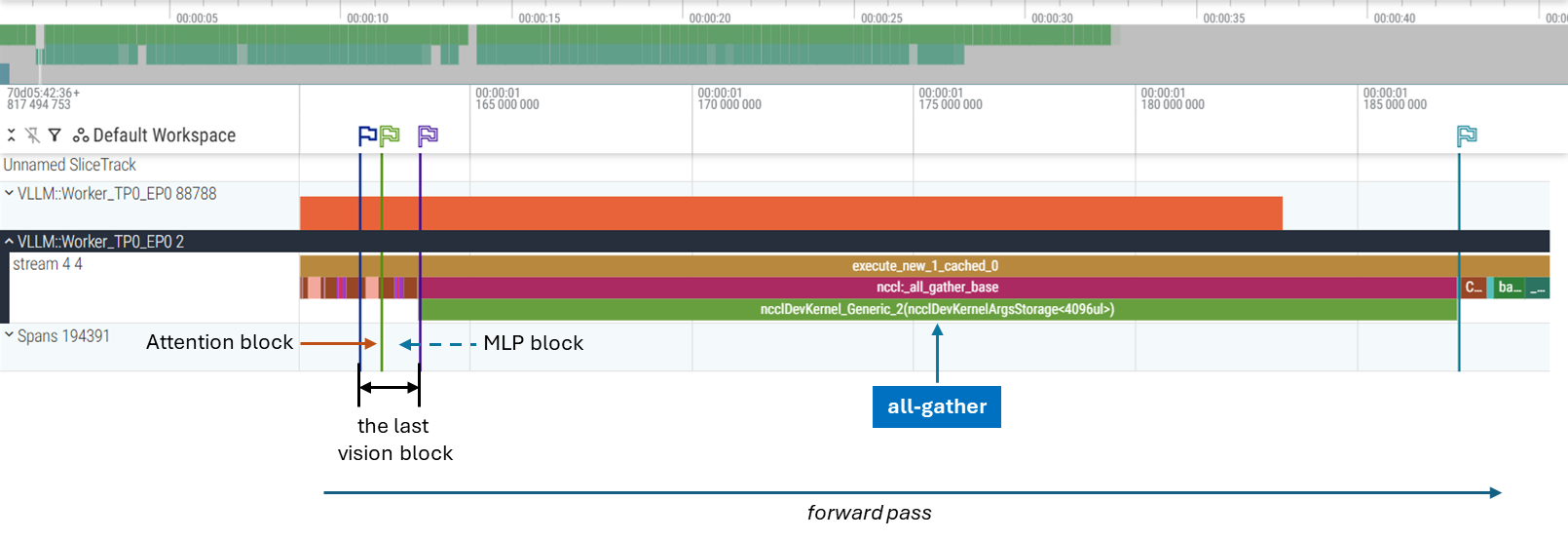
Figure 5: DP mode trace of All-Gather after vision encode forward#
Analysis of PyTorch Profiler Traces#
Figure 6 below presents an interactive visualization comparing communication patterns between TP and DP modes during a forward pass of the vision encoder execution of the step3 model. The figure displays two timeline bars—the top bar shows TP mode and the bottom bar shows DP mode. As you hover your cursor over different operations in the timeline, you can see detailed information about each operation’s duration and type. You can zoom into specific time ranges by clicking and dragging across the timeline, and double-click to reset the view. Use the mode toggle buttons above the timelines to switch between viewing TP mode only, DP mode only, or both modes simultaneously for direct comparison. Notice how the TP mode timeline shows frequent all-reduce operations (appearing as regular patterns throughout the execution), while the DP mode timeline shows a single all-gather operation at the end.
Figure 6: Interactive timeline comparison of TP mode vs DP mode communication patterns#
As shown in Figure 6 above, for one forward pass of the step3 model:
TP mode: 63 synchronization points of all-reduce are found in each attention and MLP blocks of the vision transformer to aggregate partial results across TP ranks
DP mode: 1 synchronization point of all-gather after the vision transformer to gather outputs across all ranks
As shown in Figure 7, the profiling results show that communication synchronization is the dominant process, with all-reduce operations consuming 39.88% of total time in TP and all-gather accounting for 32.7% in DP.
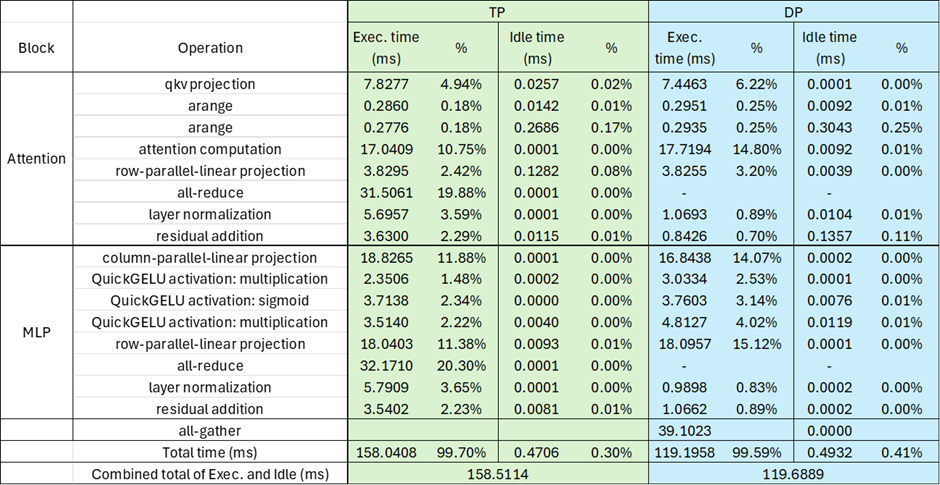
Figure 7: Breakdown of operators comparing TP mode and DP mode#
Communication Cost Comparison#
Model |
No. of vision blocks (depth) |
No. of other blocks |
TP synchronization points (All-Reduce) |
DP synchronization points (All-Gather) |
|---|---|---|---|---|
Qwen3-VL-235B-A22B-Instruct |
27 |
4 (3 Deepstack merger + 1 final merger) |
27 × 2 + 4 × 1 = 58 |
1 |
InternVL3_5-241B-A28B |
45 |
- |
45 × 2 = 90 |
1 |
step3 |
63 |
- |
63 × 2 = 126 |
1 |
When DP wins:
Deeper vision encoders → more TP synchronization points → greater DP advantage (step3’s 126 sync points vs. Qwen3-VL-235B-A22B-Instruct’s 58)
Low-to-moderate items per request (1-3) with medium-to-high resolution images (512×512 pixels - 1024×1024 pixels) show consistent gains
Note
Performance gains vary by workload characteristics. Very high items-per-request (10+) with large images may show diminished or negative gains due to increased all-gather payload size and memory pressure—benchmark your specific workload.
Tradeoff: Memory overhead from replicated encoder weights (0.2-2.3% of the total model size) in exchange for eliminating 58-126 synchronization points per forward pass.
Practical Recommendations#
Use DP Mode (--mm-encoder-tp-mode data) When#
Processing high-resolution images (1024×1024: +16.2% average gain vs. 512×512: +14.6% vs. 256×256: +8.1%)
Low-to-moderate items per request (1-3 images: +13-16% average gain)
Vision encoder represents >1% of the total model parameters (larger encoders benefit more from communication reduction)
Throughput is critical and sufficient GPU memory is available for weight replication
Use DP Mode With Caution When#
Vision encoder is small relative to total model size (encoders <1% of total parameters show more modest and variable gains—benchmark your specific workload)
Processing high item counts per request (10 images: +9.5% average with diminishing returns)
Combining small images with high image counts (256×256 pixels × 10 images shows minimal or negative gains)
Operating under memory constraints (DP mode requires full encoder weights replicated across all TP ranks)
Summary#
In this blog, you learned how batch-level Data Parallelism offers an alternative parallelism strategy for vision encoders in multimodal models. While Tensor Parallelism shards encoder weights across GPUs with frequent all-reduce synchronization, batch-level DP replicates the lightweight encoder (0.2-2.3% of total parameters) and eliminates communication during the forward pass.
Our benchmarks on AMD Instinct™ MI300X GPUs reveal performance patterns tied to encoder depth. Deeper transformers (step3’s 63 blocks, InternVL3_5-241B-A28B’s 45 blocks) show more consistent gains than shallow encoders (Qwen3-VL-235B-A22B-Instruct’s 27 blocks), correlating with synchronization points eliminated (126 vs 90 vs 58 all-reduces replaced by one all-gather). Peak gains of 10-45% appear at 1-3 images per request with 512×512 to 1024×1024 resolution.
For practitioners deploying multimodal models, enabling --mm-encoder-tp-mode data is a simple, high-impact optimization—especially for deep vision encoders processing high-resolution images. The memory overhead from weight replication is often negligible compared to the reduced communication overhead. While results vary by architecture and workload, the potential for 10-45% throughput improvements makes this a compelling one-line change worth benchmarking in your specific configuration.
This work builds on our ongoing exploration of vLLM optimization strategies. Our previous work on [4] covered general performance tuning across various model architectures. The current focus on multimodal encoder parallelism addresses the specific challenges when vision and language components meet.
Looking ahead, vLLM continues evolving with features like disaggregated encoders for more flexible resource allocation. As these capabilities mature and deployment patterns emerge, we plan to explore their implications for production serving. We will continue sharing insights as we benchmark new optimization strategies on AMD hardware.
References#
Appendix#
This appendix provides complete, reproducible vLLM command-line configurations for all benchmark tests presented in this guide. Each command includes the exact environment variables (AITER settings), parallelism flags for batch-level DP, and deployment parameters used to generate the performance results for Qwen3-VL-235B-A22B-Instruct, InternVL3_5-241B-A28B and step3 on AMD Instinct™ MI300X GPUs.
Qwen3-VL-235B-A22B-Instruct: batch-level TP#
VLLM_ROCM_USE_AITER=1 VLLM_ROCM_USE_AITER_MHA=1 VLLM_V1_USE_PREFILL_DECODE_ATTENTION=0 vllm serve Qwen/Qwen3-VL-235B-A22B-Instruct \
--tensor-parallel-size 8 \
--data-parallel-size 1 \
--enable-expert-parallel \
--mm-encoder-tp-mode weights \
--max-model-len 32768 \
--compilation-config '{\"cudagraph_mode\":\"FULL_AND_PIECEWISE\", \"level\":3}' \
--trust-remote-code \
--distributed-executor-backend mp \
--swap-space 16 \
--disable-log-requests \
--port 8000
Qwen3-VL-235B-A22B-Instruct: batch-level DP#
VLLM_ROCM_USE_AITER=1 VLLM_ROCM_USE_AITER_MHA=1 VLLM_V1_USE_PREFILL_DECODE_ATTENTION=0 vllm serve Qwen/Qwen3-VL-235B-A22B-Instruct \
--tensor-parallel-size 8 \
--data-parallel-size 1 \
--enable-expert-parallel \
--mm-encoder-tp-mode data \
--max-model-len 32768 \
--compilation-config '{\"cudagraph_mode\":\"FULL_AND_PIECEWISE\", \"level\":3}' \
--trust-remote-code \
--distributed-executor-backend mp \
--swap-space 16 \
--disable-log-requests \
--port 8000
step3: batch-level TP#
VLLM_ROCM_USE_AITER=1 VLLM_ROCM_USE_AITER_MHA=1 VLLM_V1_USE_PREFILL_DECODE_ATTENTION=0 vllm serve stepfun-ai/step3 \
--tensor-parallel-size 8 \
--data-parallel-size 1 \
--enable-expert-parallel \
--mm-encoder-tp-mode weights \
--max-model-len 32768 \
--compilation-config '{\"cudagraph_mode\":\"FULL_AND_PIECEWISE\", \"level\":3}' \
--trust-remote-code \
--distributed-executor-backend mp \
--swap-space 16 \
--disable-log-requests \
--port 8000
step3: batch-level DP#
VLLM_ROCM_USE_AITER=1 VLLM_ROCM_USE_AITER_MHA=1 VLLM_V1_USE_PREFILL_DECODE_ATTENTION=0 vllm serve stepfun-ai/step3 \
--tensor-parallel-size 8 \
--data-parallel-size 1 \
--enable-expert-parallel \
--mm-encoder-tp-mode data \
--max-model-len 32768 \
--compilation-config '{\"cudagraph_mode\":\"FULL_AND_PIECEWISE\", \"level\":3}' \
--trust-remote-code \
--distributed-executor-backend mp \
--swap-space 16 \
--disable-log-requests \
--port 8000
InternVL3_5-241B-A28B: batch-level TP#
VLLM_ROCM_USE_AITER=1 VLLM_ROCM_USE_AITER_MHA=1 VLLM_V1_USE_PREFILL_DECODE_ATTENTION=0 vllm serve OpenGVLab/InternVL3_5-241B-A28B \
--tensor-parallel-size 8 \
--data-parallel-size 1 \
--enable-expert-parallel \
--mm-encoder-tp-mode weights \
--max-model-len 32768 \
--compilation-config '{\"cudagraph_mode\":\"FULL_AND_PIECEWISE\", \"level\":3}' \
--trust-remote-code \
--distributed-executor-backend mp \
--swap-space 16 \
--disable-log-requests \
--port 8000
InternVL3_5-241B-A28B: batch-level DP#
VLLM_ROCM_USE_AITER=1 VLLM_ROCM_USE_AITER_MHA=1 VLLM_V1_USE_PREFILL_DECODE_ATTENTION=0 vllm serve OpenGVLab/InternVL3_5-241B-A28B \
--tensor-parallel-size 8 \
--data-parallel-size 1 \
--enable-expert-parallel \
--mm-encoder-tp-mode data \
--max-model-len 32768 \
--compilation-config '{\"cudagraph_mode\":\"FULL_AND_PIECEWISE\", \"level\":3}' \
--trust-remote-code \
--distributed-executor-backend mp \
--swap-space 16 \
--disable-log-requests \
--port 8000
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.