Applications & models - Page 4#
Explore the latest blogs about applications and models in the ROCm ecosystem, including machine learning frameworks, AI models, and application case studies.

FlashInfer on ROCm: High‑Throughput Prefill Attention via AITER
FlashInfer is an open-source library for accelerating LLM serving that is now supported by ROCm.

Customizing Kernels with hipBLASLt TensileLite GEMM Tuning - Advanced User Guide
Master hipBLASLt TensileLite Tuning. Learn to build custom kernels that deliver 150%-250% faster GEMM performance on AMD Instinct™ MI300X GPUs

Deploy and Customize AMD Solution Blueprints
Learn how to deploy and customize AMD Solution Blueprints — from default deployment to swapping and reusing AMD Inference Microservices across multiple blueprints.

AMD Instinct™ GPUs MLPerf Inference v6.0 Submission
In this blog, we share the technical details of how we accomplish the results in our MLPerf Inference v6.0 submission.

Reproducing the AMD MLPerf Inference v6.0 Submission Result
Provide instructions to potential customers and partners to verify our MLPerf Inference v6.0 submission result.

Training a Robotic Arm Using MuJoCo and JAX on AMD Hardware with ROCm™
A complete guide to training an RL-based pick-and-lift robotic arm in MuJoCo with JAX, running on AMD hardware via ROCm.

Programming Tensor Descriptors in Composable Kernel (CK)
Learn how to use TensorDescriptor in Composable Kernel (CK) to manage multi-dimensional data layouts and write efficient GPU kernels on AMD GPUs.
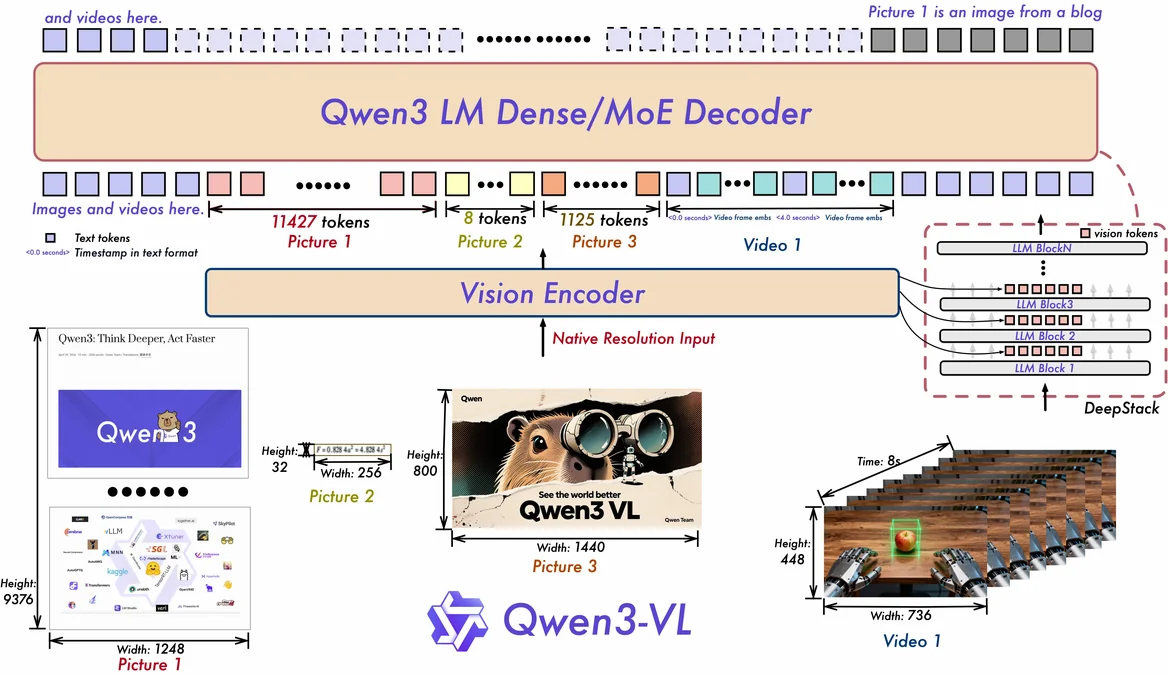
Engineering Qwen-VL for Production: Vision Module Architecture and Optimization Practices
Explore how to optimize Qwen-VL for production on AMD Instinct MI308X GPUs with ROCm, from vision module architecture to kernel fusion and deployment.

Accelerating Kimi-K2.5 on AMD Instinct™ MI300X: Optimizing Fused MoE with FlyDSL
Optimize Kimi-K2.5 on AMD MI300X using FlyDSL for fused MoE kernel acceleration. Achieve faster TTFT, TPOT, and throughput with our step-by-step optimization guide.

GROMACS on AMD Instinct GPUs: A Complete Build Guide
Build GROMACS with HIP, UCX, and OpenMPI on AMD MI300X/MI355X — covering bare metal, Apptainer, and Docker deployments.

Edge-to-Cloud Robotics with AMD ROCm: From Data Collection to Real-Time Inference
This blog demonstrates a comprehensive Edge-to-Cloud robotics AI solution powered by the AMD ecosystem and the Hugging Face LeRobot framework.

hipBLASLt Online GEMM Tuning
Learn how to improve model performance with hipBLASLt online tuning merged into LLM framework