Accelerating Mixture-of-Experts Execution with FarSkip-Collective Models#

Whether you are running training or inference, the largest Mixture-of-Experts (MoE) based LLMs cannot fit on a single GPU; instead you must run collective-communication operations to integrate the work of multiple GPUs to work together on a single model.
Researchers training and serving large MoEs recognize that distributing models over multiple GPUs is not without a cost. When splitting the model execution over multiple GPUs, one may face blocking communication patterns which are defined as idle GPU time-segments when calculations must wait while the GPUs synchronize their data.
This blog post presents a modified model architecture for MoEs known as FarSkip-Collective that enables native computation-communication overlapping of MoEs. Computation-communication overlapping ensures the GPU continues to run computations throughout the workload and directly removes idle computation time-segments. FarSkip-Collective’s approach directly accelerates training and inference latencies of MoEs all while maintaining accuracy comparable to the original MoE architecture.
Below we explore our approach and provide hands-on resources for pre-training a FarSkip-Collective model on top of AMD’s Primus framework.
Unhobbling the Mixture-of-Experts Architecture#
Mixture-of-Experts (MoE) based LLMs activate only a subset of their parameters for each token prediction, which decouples the size of the model from the amount of computation it performs (e.g. FLOPs). For example, open-source models such as DeepSeek-R1 and Kimi-K2 have 671B and 1T total parameters but activate only 37B (~5%) and 32B (~3%) of their parameters, respectively, for each token they process.
Because MoEs are more computationally efficient they can be scaled further than dense models to large parameter sizes which require massive memory capacity such as that offered by AMD Instinct GPUs. For the largest and most advanced MoEs such as DeepSeek R1, however, one cannot fit the entire model on any existing single GPU. Instead, you must split the model over multiple GPUs interconnected with fast communication fibers (“interconnects”).
The practice of splitting the MoE model workload across multiple GPUs is named Model Parallelism, in which each GPU worker computes a piece of the model and synchronizes its results with other GPUs in its worker group. For MoEs a key Model Parallelism technique is Expert Parallelism (EP) where the model’s experts in each layer are split across different GPUs. With this setup, when processing each layer the GPUs synchronize their respective expert computation via collective-communication calls. During the synchronization, GPU computation must wait because the next step in the model execution relies on the synchronized outputs from the current layer. This pattern of synchronization that must finish before computation introduces the undesired blocking communication bubble.
But what if we don’t wait for the synchronization to finish before starting computation of the next layer?
FarSkip-Collective explores exactly this question and instead of waiting for collective communication to finish it uses either partial or outdated activations that are already available to start calculations of the next layer. At the same time as the next computation, the synchronization process continues in parallel. When the collective-communication synchronization finishes we finally add it to the residual activation to ensure full information propagation from all layers. In doing so, we “far-skip” the collective to the end of the next computation and ensure that 1) we remove idle time caused by the collective communication by using an available activation and 2) propagate the synchronized activation by eventually summing it with the residual after the layer. FarSkip breaks the straightforward but limiting chronological flow of information in modern networks and takes a more flexible approach that is not blocking. We present the detailed implementation of FarSkip-Collective in our paper and in the Primus based implementation we share below.
Evaluating FarSkip-Collective Models#
We validate the modified FarSkip-Collective MoE architecture by comparing it with existing MoEs. By running pre-training architectural ablations of FarSkip-Collective with a DeepSeek-V2 Lite MoE configuration, in Figure 1 we observe that the architecture performs on-par with the regularly pre-trained MoE model.
Figure 1: FarSkip-Collective ablation with DeepSeek-V2 Lite model configuration (16B parameters 3B active parameters) trained for 50B tokens.#
To prove out FarSkip for even larger model scales we set out to create a state-of-the-art 100B+ MoE model based on FarSkip-Collective. Efficiency was top of mind so we needed to achieve this milestone without the resources of a full-fledged model training with trillions of tokens.
To this end, we develop an efficient self-distillation method (FCSD) to convert any existing regular MoE model into a FarSkip-Collective MoE model efficiently at scale. Our pipeline starts with an existing MoE model checkpoint and converts it into a FarSkip-Collective compatible checkpoint via an efficient training recipe. Using FCSD we achieve the following results when converting Llama-4-Scout MoE:
Model |
PIQA |
ARC-E |
ARC-C |
HS |
CSQa |
WG |
HEval+ |
MMLU |
OBook |
GSM-8K |
MBPP+ |
Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
Llama-4 Scout |
81.1 |
87.3 |
64.6 |
82.9 |
84.4 |
76.6 |
62.2 |
80.0 |
45.2 |
88.6 |
83.6 |
76.0 |
Llama-4 Scout |
80.8 |
87.0 |
62.4 |
82.0 |
82.4 |
75.8 |
63.4 |
75.9 |
44.4 |
89.8 |
81.7 |
75.1 |
Along with validating the accuracy of FarSkip models we look to harness the relaxed connectivity of the model architecture to optimize their computation-communication overlapping on hardware. For inference, we build using the vLLM and SGLang frameworks and accelerate MoEs Time to First Token (TTFT) by 18% by overlapping communication with FarSkip models as shown in Figure 2. For larger architectures such as DeepSeek-V3 671B parameter model, FarSkip-Collective delivers TTFT speedup of up to 1.34x.
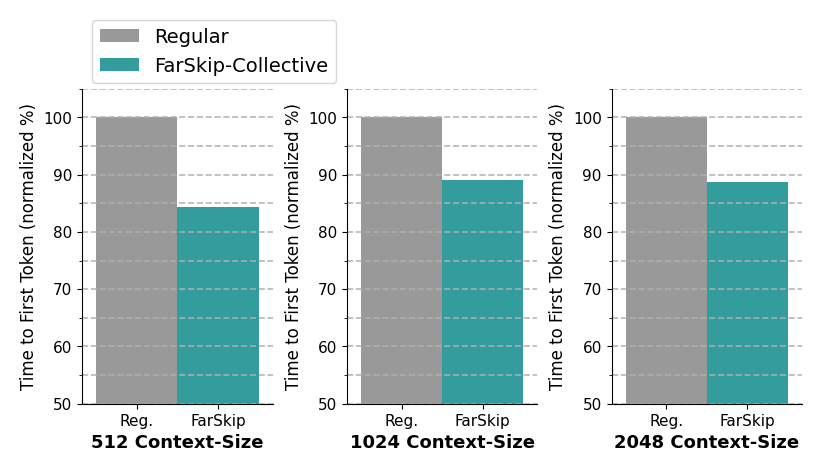
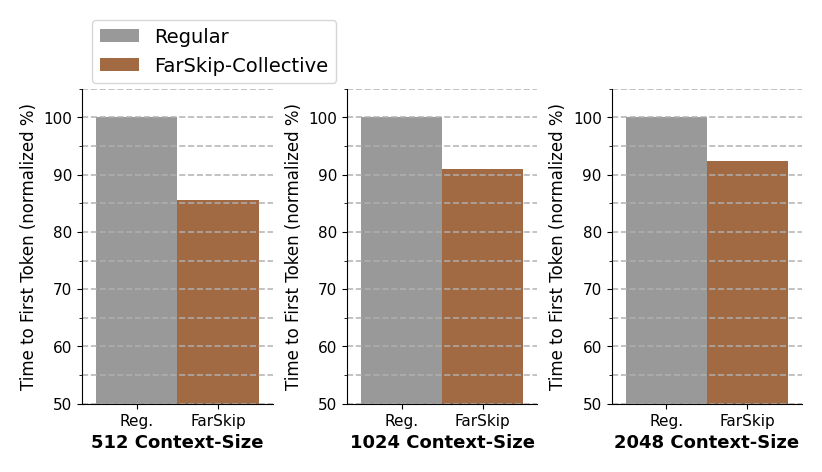
For pre-training FarSkip-Collective models, we develop an implementation with high computation-communication overlapping in both the forward and backward passes of the model. To control the placement of communication and computation routines during backpropagation, we use techniques to control PyTorch’s torch.autograd’s scheduling implicitly which allows us to achieve overlapping of collective-communication while keeping the implementation streamlined. We measure the speedup of FarSkip-Collective pre-training with varying Expert-Parallel sizes in Figure 3.
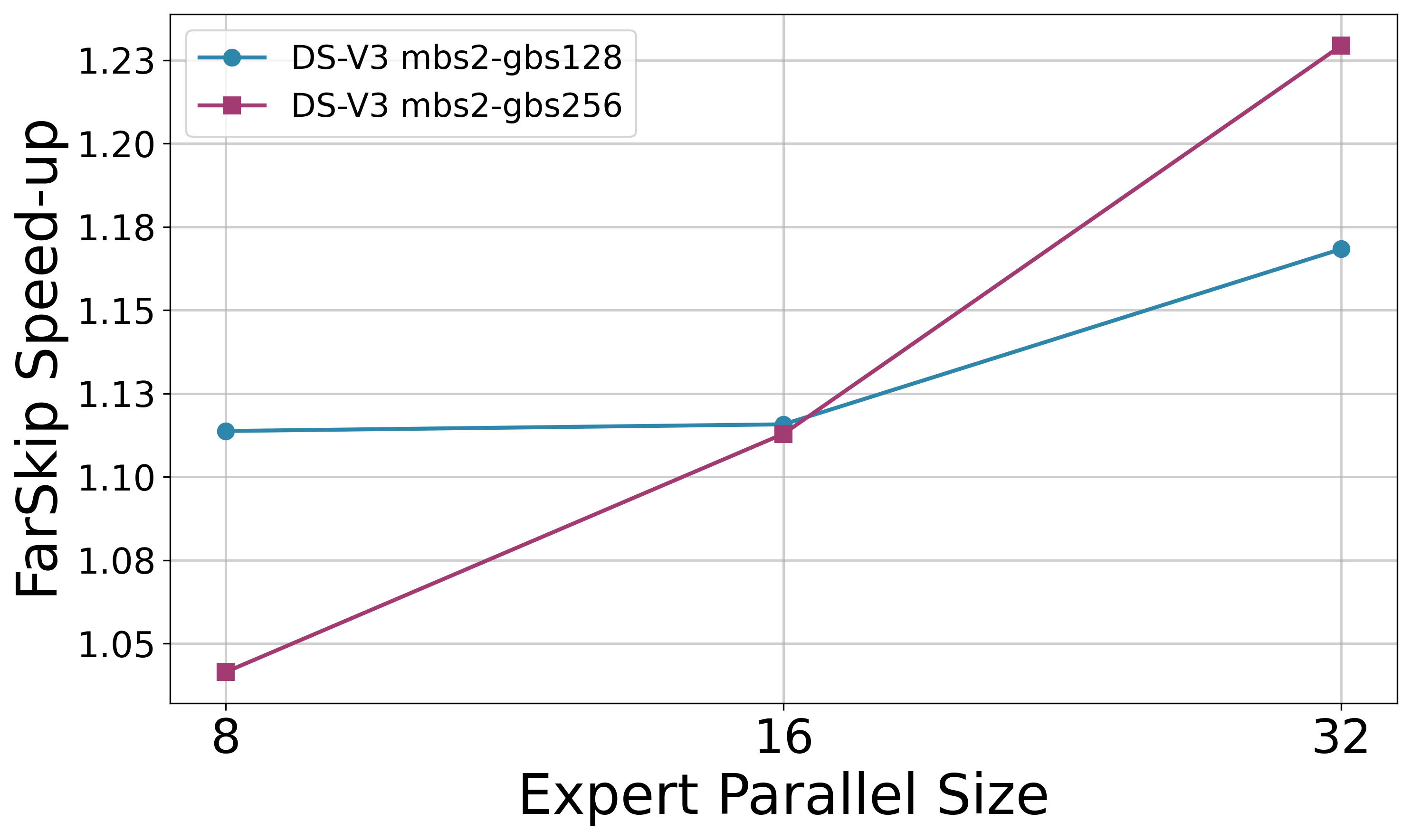
Figure 3: FarSkip-Collective DeepSeek-V3 (short) pre-training speedup with varying Expert-Parallel (EP) size.#
Below we demonstrate FarSkip-Collective pre-training in action by providing a step-by-step guide to run FarSkip model pretraining on top of Primus.
Get Started with FarSkip-Collective on AMD Primus#
FarSkip-Collective’s optimized pre-training implementation is directly integrated with Primus: AMD’s unified and modular training framework. Within Primus, FarSkip-Collective is integrated into the Megatron-LM backend. This enables you to see FarSkip-Collective in action with a few easy steps.
1. Environment setup with Docker#
Use the official ROCm Megatron Docker image to set up the Primus training environment:
# Pull docker image
PRIMUS_IMAGE=docker.io/rocm/megatron-lm:v25.8_py310
# run the container
docker run -it --device /dev/dri --device /dev/kfd --device /dev/infiniband --network host --ipc host --group-add video --cap-add SYS_PTRACE --security-opt seccomp=unconfined --privileged -v $HOME:$HOME -v $HOME/.ssh:/root/.ssh --shm-size 128G --name primus_farskip $PRIMUS_IMAGE
2. Setup the Primus Repo#
Install the Primus repo FarSkip-Collective branch:
# using the dev/farskip branch
git clone -b dev/farskip --recurse-submodules https://github.com/AMD-AIG-AIMA/Primus.git
cd Primus
# Install Python dependencies
pip install -r requirements.txt
3. Launch training with FarSkip-Collective using the Kimi Moonlight Architecture#
Kimi Moonlight is a 16B MoE model with 3B active parameters that demonstrates strong performance for its scale. We integrate the Moonlight model architecture (based on DeepSeek-V3) with FarSkip-Collective. To run pre-training with the overlapped FarSkip implementation, run
export EXP=examples/megatron/configs/farskip-overlap-moonlight-pretrain.yaml
bash ./examples/run_pretrain.sh
By using FarSkip-Collective we accelerate the optimized Moonlight pre-training by 11%. Further, by integrating Moonlight with Grouped-Query-Attention layers we accelerate model training by 16%.
4. Customize FarSkip-Collective training#
You can configure the FarSkip-Collective training setup based on the following flags
use_overlapped_farskip_layer: true
use_simple_farskip_layer: false
mlp_only_farskip: false
attn_only_farskip: false
We provide two implementations of FarSkip-Collective: a “simple” and “overlapped” implementation that are configured via the use_overlapped_farskip_layer and use_simple_farskip_layer flags. The “simple” implementation serves as a reference implementation that follows the exact layer logic of FarSkip models but does not actively overlap communication with computation and therefore does not harness the efficiencies brought about by the architecture. The main implementation is the “overlapped” implementation that is optimized to remove idle compute time-segments by overlapping the communication in the model with computation.
We also support partial use of FarSkip-Collective applied to a subset of the model layers. Activating attn_only_farskip only overlaps the attention layers, similarly mlp_only_farskip will only overlap the MoE layers.
Summary#
By rethinking the requirements of the MoE layer connectivity, FarSkip-Collective enables an unprecedented level of efficiency when distributing MoEs over multiple GPUs. Our experiments show that FarSkip-Collective models remain as capable as MoE models and the additional efficiency brought about by FarSkip-Collective can enable larger and sparser MoE models without facing the inefficiencies brought about by computation bubbles during distributed model execution.
Additional Resources#
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.