hipBLASLt Online GEMM Tuning#

This blog post introduces the integration of hipBLASLt Online GEMM Tuning into LLM frameworks, illustrated through an example implementation of RTP-LLM. Developed by the AMD Quark Team, hipBLASLt Online Tuning provides a user-friendly approach to improving GEMM performance by enabling runtime tuning without requiring additional offline tuning steps.
For more information about hipBLASLt offline tuning, please refer to the previous blog post Day 0 Developer Guide: hipBLASLt Offline GEMM Tuning Script. That post introduces the background of GEMM tuning and demonstrates how to use hipBLASLt offline tuning to improve model performance. In this blog, we build on that work and focus on the design, implementation, and performance of hipBLASLt online tuning.
Background#
Matrix–matrix multiplication, or GEMM (General Matrix Multiply), is one of the most fundamental operations in AI workloads. GEMM operations dominate both training and inference time, often consuming the majority of total runtime. Because of this, even a small improvement in GEMM performance can translate into significant end-to-end speedups. A tremendous amount of research has gone into the optimization of matrix multiplication.
GEMM tuning is the process of optimizing how GEMM operations are executed on specific hardware to maximize performance. Modern software libraries offer multiple algorithms or kernel variants for computing GEMM on CPUs and GPUs, each with different tile and block sizes, memory layouts, thread configurations, and instruction usage. The goal of tuning is to identify the implementation that yields the best performance for a given production scenario (e.g., on metrics such as throughput, latency, and goodput) for a specific matrix size, data type, and hardware architecture.
Online GEMM Tuning#
Online GEMM tuning refers to the practice of optimizing GEMM operations during runtime by dynamically selecting the best-performing implementation for the current workload and hardware environment. Instead of relying solely on pre-tuned kernels, online tuning evaluates multiple candidate algorithms or kernel variants during execution—often using lightweight profiling—and chooses the one that delivers the best performance for a given matrix shape, data type, and device.
This approach allows GEMM performance to adapt to dynamic inputs, changing hardware conditions, and evolving workloads, reducing the need for exhaustive offline benchmarking while providing robust, user-transparent performance optimization.
GEMM tuning can be categorized into Online GEMM Tuning and Offline GEMM Tuning (refer to the previous blog for details). Compared with offline tuning, online tuning offers several advantages:
Ease of Use: Operates automatically without requiring changes to user workflows or deployment pipelines, and reduces the need for users to understand low-level hardware or kernel parameters.
Adaptivity: Automatically adapts to real runtime inputs, matrix shapes, data types, and hardware environments that may not be known in advance.
Future-proofing: Continues to discover efficient kernels as models, workloads, and hardware evolve, without requiring repeated offline re-tuning.
For these reasons, online GEMM tuning is considered a valuable feature for optimizing the performance of LLM workloads. Frameworks such as TensorRT-LLM and TVM also provide similar runtime tuning capabilities.
Workflow of hipBLASLt Online Tuning#
The online tuning feature is implemented on top of the hipBLASLt API and is fully integrated inside the hipBLASLt GEMM wrapper. Instead of relying on offline benchmarking tools, the wrapper dynamically invokes hipBLASLt heuristic and tuning-related APIs at runtime to evaluate multiple candidate GEMM algorithms for a given GEMM configuration. When a new GEMM shape is encountered, the wrapper performs lightweight performance measurements, selects the best-performing algorithm, and caches the result for subsequent executions. This design allows online tuning to transparently leverage hipBLASLt’s existing algorithm selection and execution mechanisms while providing adaptive, shape-aware optimization without requiring changes to the underlying hipBLASLt library or application code. The hipBLASLt Online Tuning consists of following steps:
Lookup in cache file: Search the tuning cache file for a matching GEMM configuration and return the corresponding solution index.
Candidate Benchmark and Selection: If the GEMM configuration is not found in the cache file, benchmark candidate solutions and select the one with the best performance.
Save solution in cache file: Store the GEMM configuration and the selected solution index in the tuning cache file for future reuse.
The workflow chart of the hipBLASLt wrapper with the online tuning feature is shown in Figure 1 below.
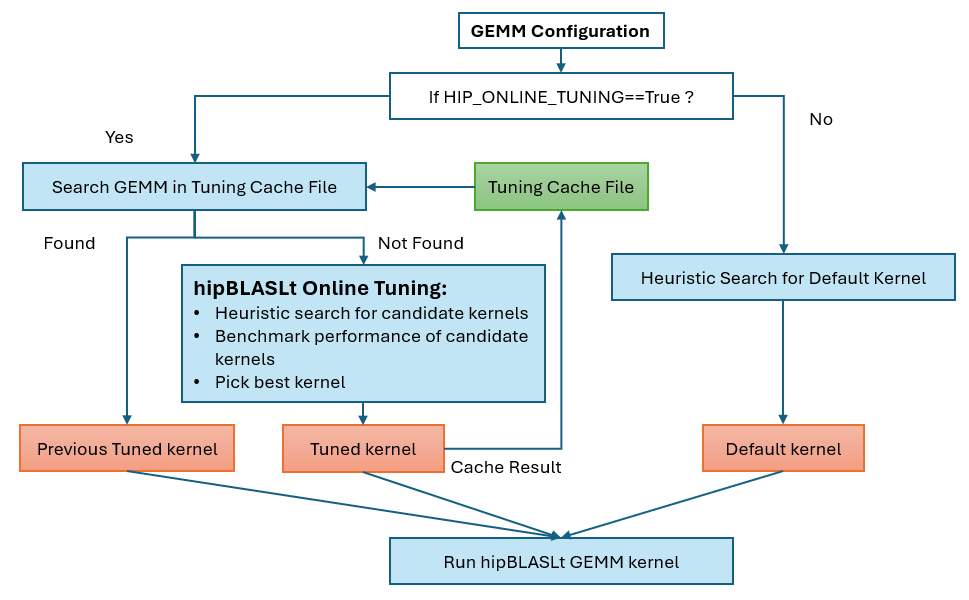
Figure 1. Flow of hipBLASLt online tuning#
Experiments of hipBLASLt Online Tuning#
The hipBLASLt online tuning feature has been merged into the AITER. Enabling hipBLASLt online tuning is straightforward and requires only setting the environment variable HIP_ONLINE_TUNING.
export HIP_ONLINE_TUNING=1
Note To enable the hipBLASLt online tuning in vLLM, set the environment variable “VLLM_ROCM_USE_AITER_HIP_ONLINE_TUNING”.
export VLLM_ROCM_USE_AITER_HIP_ONLINE_TUNING=1
We evaluated hipBLASLt online tuning on the Qwen3-30B model and collected kernel latency data on the AMD MI308 GPU, and compared its performance against offline tuning results generated by QuickTune. The comparison between online and offline tuning is shown in Figure 2. The column “baseline latency” indicates the latency data without tuning.
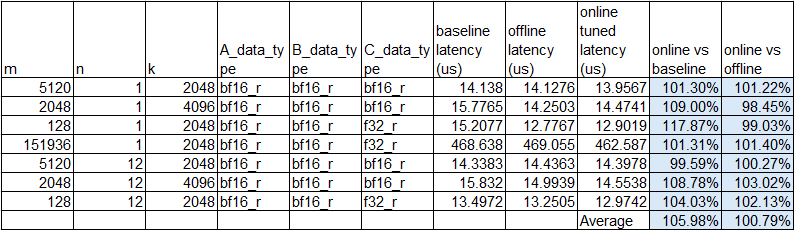
Figure 2. hipBLASLt online/offline tuning comparison#
The experimental results demonstrate that the proposed online tuning approach consistently achieves performance comparable to, and in many cases better than the baseline and equivalent to offline-tuned configurations. On average, online tuning achieves a 105.98% performance relative to the baseline and 100.79% relative to offline tuning, confirming that the runtime tuning strategy can effectively identify near-optimal algorithms without prior offline profiling while preserving stable performance across diverse GEMM configurations.
The total overhead introduced by the online tuning process for the above experiments is 31 seconds, which corresponds to the one-time cost of benchmarking candidate algorithms for previously unseen GEMM configurations. This overhead is amortized over subsequent executions because the selected optimal algorithms are cached and reused for identical problem shapes, eliminating the need for repeated tuning. Given the observable performance gains and the close alignment with offline-tuned results, the 31-second tuning cost represents a reasonable trade-off between upfront runtime overhead and long-term execution efficiency, especially for workloads where the same GEMM shapes are invoked repeatedly during model inference or training.
Summary#
This blog presents the hipBLASLt Online GEMM Tuning feature and its integration into LLM frameworks such as RTP-LLM and vLLM as a practical runtime alternative to offline tuning. Implemented on top of the hipBLASLt API within the GEMM wrapper, the online tuning mechanism dynamically evaluates candidate GEMM algorithms when new matrix configurations are encountered, selects the most efficient solution, and stores it in a cache for future reuse.
Compared with offline tuning, online tuning emphasizes ease of use, adaptability to real workloads, and long-term maintainability as models and hardware evolve, without requiring users to manage separate tuning scripts or profiles. Experimental results demonstrate that online tuning can achieve performance comparable to offline tuning and often improves upon baseline execution, while introducing only a one-time overhead that is amortized over repeated runs. Overall, the blog highlights online tuning as a user-transparent and effective approach to delivering robust GEMM performance optimization for large language model workloads.
Acknowledgement#
We would like to express our thanks to our colleagues Jiangyong Ren, Hang Yang, Junyan Yang, Yilin Zhao, Thiago Fernandes Crepaldi, Bowen Bao, AMD Quark Team and AITER team, for their insightful feedback and technical assistance.
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.