QuickReduce FP4 Quantization and Benchmarking on MI355#

Large Language Models (LLMs) typically contain billions — or even tens of billions — of parameters. During inference, tensor parallelism is commonly employed to distribute the workload across multiple GPUs. This approach demands frequent, large-scale data synchronization between layers, introducing significant communication latency and placing enormous pressure on interconnect bandwidth.
Among the various communication patterns, all-reduce stands out as one of the most critical. It aggregates data (e.g., via summation) from all participating devices and broadcasts the result back, enabling synchronized multi-GPU computation.
QuickReduce is a high-performance all-reduce library designed for AMD ROCm that supports inline compression. Compared to RCCL (AMD’s collective communications primitives for multi-GPU and multi-node communication), QuickReduce achieves up to 2.25x faster performance on 2×MI300X and 4×MI300X configurations, and outperforms RCCL for all multi-GPU (single-node) configurations when optimized.
In our previous work, we provided a detailed discussion of the design principles and performance characteristics of QuickReduce, and integrated it into the popular inference frameworks vLLM and SGLang, along with comprehensive performance and accuracy benchmarks for MI300.
In this blog post, we extend our evaluation to the MI355 platform, presenting performance and accuracy results on this newer hardware. Additionally, we introduce support for FP4 quantization within QuickReduce on MI355.
QuickReduce with FP4#
The OCP standard defines MXFP4 with an E8M0 scaling exponent — an 8-bit exponent-only format with no mantissa bits. To achieve higher precision, we diverge from the OCP standard and instead compute the scale directly in FP16 format.
The MI355 architecture provides dedicated FP4 assembly instructions that can be leveraged to accelerate both quantization and dequantization operations.
Quantization (Send Path)#
// Compute the absolute maximum of the atom in the thread group
int wblockmax = group_abs_max<T>(atom);
// Derive encoding and decoding scales
int decoding_scale = packed_mul<T>(wblockmax, kScaleFactor);
int encoding_scale = packed_add<T>(decoding_scale, kScaleEpsilon);
encoding_scale = packed_rcp<T>(encoding_scale);
// Apply scales to get quantized values
int32x4_t w;
for (int i = 0; i < 4; i++) {
w[i] = packed_mul<T>(atom[i], encoding_scale);
}
// Convert FP16 to FP4 using MI355 native instructions
float con_scale = 1.0f;
int32_t qw;
__amd_fp16x2_storage_t* y = reinterpret_cast<__amd_fp16x2_storage_t*>(&w);
qw = __builtin_amdgcn_cvt_scalef32_pk_fp4_f16(qw, y[0], con_scale, 0);
qw = __builtin_amdgcn_cvt_scalef32_pk_fp4_f16(qw, y[1], con_scale, 1);
qw = __builtin_amdgcn_cvt_scalef32_pk_fp4_f16(qw, y[2], con_scale, 2);
qw = __builtin_amdgcn_cvt_scalef32_pk_fp4_f16(qw, y[3], con_scale, 3);
Dequantization (Receive Path)#
// Convert FP4 back to FP16 using MI355 native instructions
int32x4_t w;
__amd_fp16x2_storage_t* y = reinterpret_cast<__amd_fp16x2_storage_t*>(&w);
__hip_fp4x2_storage_t* qww = reinterpret_cast<__hip_fp4x2_storage_t*>(&qw);
y[0] = __builtin_amdgcn_cvt_scalef32_pk_f16_fp4(qww[0], 1.0f, 0);
y[1] = __builtin_amdgcn_cvt_scalef32_pk_f16_fp4(qww[1], 1.0f, 0);
y[2] = __builtin_amdgcn_cvt_scalef32_pk_f16_fp4(qww[2], 1.0f, 0);
y[3] = __builtin_amdgcn_cvt_scalef32_pk_f16_fp4(qww[3], 1.0f, 0);
QuickReduce Benchmarking on MI355#
Kernel Performance#
We benchmark three all-reduce implementations on MI355:
RCCL
Custom AllReduce (CR) — A widely adopted all-reduce acceleration kernel used in vLLM and SGLang, which significantly outperforms RCCL at low data volumes.
QuickReduce (QR) — Tested with four quantization configurations: INT8, INT6, INT4, and FP4.
We evaluate all three approaches across message sizes ranging from 4 KB to 1 GB.
All latency values are in μs (microseconds).
To better visualize relative performance across the full message-size range, we plot speedup over RCCL instead of raw latency. The y-axis is computed as RCCL latency divided by the latency of each method, so values greater than 1 indicate better performance than RCCL.
TP = 2#
The figure below shows the TP=2 speedup over RCCL across message sizes, highlighting where QuickReduce FP4 and INT4 overtake CR.
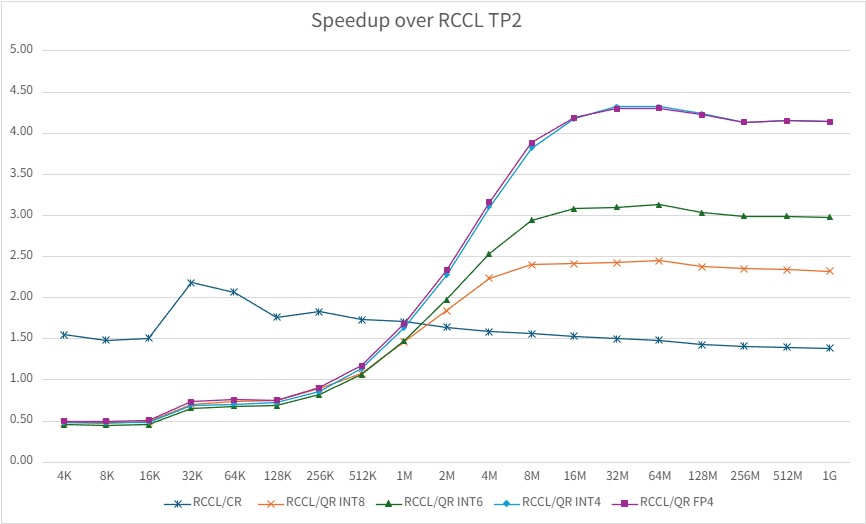
Speedup over RCCL on MI355 at TP=2. The y-axis is computed as RCCL latency divided by the measured latency of each method.#
At TP=2, CR is clearly the strongest option for small message sizes, while QR INT4 and QR FP4 become the best-performing configurations once the message size grows beyond the crossover region. At large message sizes, QR FP4 achieves roughly 4.1x speedup over RCCL.
TP = 4#
The figure below shows the TP=4 speedup over RCCL and illustrates that QuickReduce becomes more effective as message size increases.
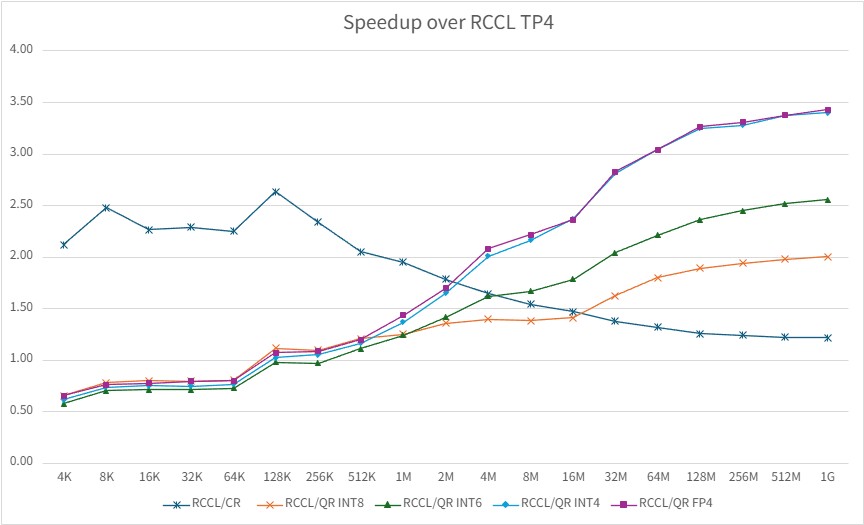
Speedup over RCCL on MI355 at TP=4. The y-axis is computed as RCCL latency divided by the measured latency of each method.#
At TP=4, the same pattern holds: CR leads in the low-volume regime, but QR INT4 and QR FP4 become dominant as message size increases. In the large-message regime, QuickReduce delivers more than 3x speedup over RCCL, with FP4 and INT4 remaining very close.
TP = 8#
The figure below shows the TP=8 speedup over RCCL, where the crossover point moves to larger message sizes because more GPUs participate in the all-reduce.
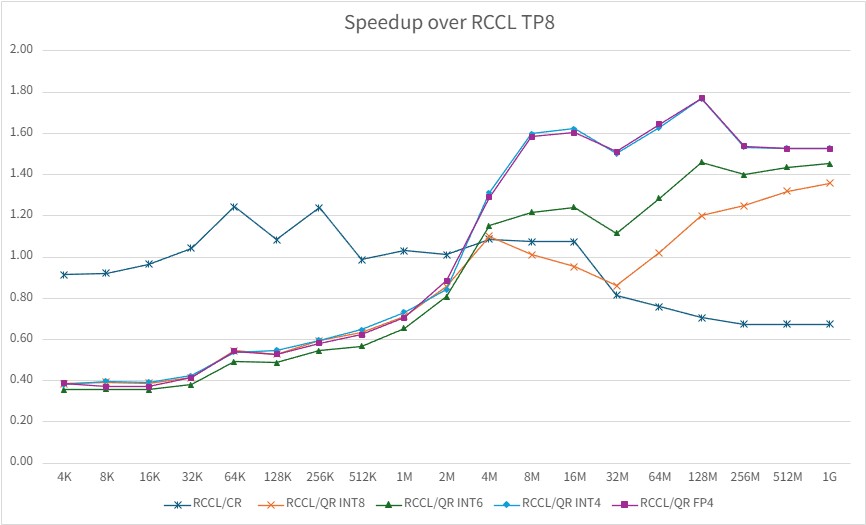
Speedup over RCCL on MI355 at TP=8. The y-axis is computed as RCCL latency divided by the measured latency of each method.#
At TP=8, the crossover point shifts to larger message sizes. CR remains favorable for small messages, while QuickReduce starts to show clear gains only once the message size reaches the multi-megabyte regime. Even in this more demanding setting, QR INT4 and QR FP4 still provide the highest speedup in the large-message region.
Key Observations#
From the results, we draw the following conclusions:
For message sizes above the crossover point, QuickReduce delivers the highest large-message speedup over RCCL. At 1 GB message size, QR FP4 achieves 4.14x speedup at TP=2, 3.43x speedup at TP=4, and 1.52x speedup at TP=8.
FP4 and INT4 deliver comparable performance — there is no meaningful throughput difference between the two quantization schemes. FP4 is marginally faster in most cases.
At TP=8, the crossover point shifts higher — QuickReduce begins to outperform CR and RCCL at approximately 4 MB rather than 1 MB, due to the increased coordination overhead with more GPUs.
CR dominates at small message sizes — for data volumes below ~512 KB, Custom AllReduce consistently delivers the lowest latency across all TP configurations.
End-to-End Performance and Accuracy#
We selected Qwen3-30B-A3B-Instruct-2507 and DeepSeek-R1-0528 as our test models and used vLLM for both performance and accuracy evaluation.
Server launch command:
VLLM_ROCM_QUICK_REDUCE_QUANTIZATION=FP4 vllm serve <model_path> \
--max-model-len 262144 \
--disable-log-requests \
--no-enable-prefix-caching \
-tp 2 \
--dtype auto \
--port 12340
Client commands:
# Accuracy evaluation
python3 vllm/tests/evals/gsm8k/gsm8k_eval.py --port 12340
# Performance benchmark
vllm bench serve \
--model <model_path> \
--backend vllm \
--endpoint /v1/completions \
--dataset-name random \
--random-input-len 2048 \
--random-output-len 10 \
--num-prompts 500 \
--ignore-eos \
--request-rate 10 \
--port 12340
Qwen3-30B-A3B-Instruct-2507#
TP = 2
The table below summarizes Qwen3-30B-A3B-Instruct-2507 results at TP=2, where FP4 and INT4 reduce TTFT and TPOT while preserving GSM8K accuracy.
Quantization |
TTFT (ms) |
TPOT (ms) |
TTFT Speedup |
TPOT Speedup |
GSM8K |
Accuracy Recovery |
|---|---|---|---|---|---|---|
NONE |
87.89 |
19.96 |
1.000 |
1.000 |
0.8842 |
1.0000 |
FP4 |
64.81 |
15.87 |
1.356 |
1.258 |
0.8788 |
0.9938 |
INT4 |
64.98 |
15.92 |
1.353 |
1.254 |
0.8838 |
0.9994 |
INT6 |
68.42 |
16.53 |
1.285 |
1.207 |
0.8835 |
0.9992 |
INT8 |
72.11 |
17.19 |
1.219 |
1.161 |
0.8815 |
0.9969 |
TP = 4
The table below summarizes Qwen3-30B-A3B-Instruct-2507 results at TP=4, where FP4 and INT4 continue to provide the best overall speedup.
Quantization |
TTFT (ms) |
TPOT (ms) |
TTFT Speedup |
TPOT Speedup |
GSM8K |
Accuracy Recovery |
|---|---|---|---|---|---|---|
NONE |
61.51 |
15.11 |
1.000 |
1.000 |
0.8835 |
1.0000 |
FP4 |
55.38 |
14.09 |
1.111 |
1.073 |
0.8860 |
1.0028 |
INT4 |
55.16 |
14.04 |
1.115 |
1.077 |
0.8852 |
1.0020 |
INT6 |
57.90 |
14.48 |
1.062 |
1.043 |
0.8820 |
0.9983 |
INT8 |
61.76 |
14.94 |
0.996 |
1.012 |
0.8805 |
0.9966 |
TP = 8
The table below summarizes Qwen3-30B-A3B-Instruct-2507 results at TP=8, where the speedup narrows because communication volume is lower relative to the coordination overhead.
Quantization |
TTFT (ms) |
TPOT (ms) |
TTFT Speedup |
TPOT Speedup |
GSM8K |
Accuracy Recovery |
|---|---|---|---|---|---|---|
NONE |
56.11 |
14.09 |
1.000 |
1.000 |
0.8858 |
1.0000 |
FP4 |
51.35 |
13.45 |
1.093 |
1.047 |
0.8912 |
1.0062 |
INT4 |
52.50 |
13.50 |
1.069 |
1.044 |
0.8810 |
0.9946 |
INT6 |
53.47 |
13.73 |
1.049 |
1.026 |
0.8825 |
0.9963 |
INT8 |
55.21 |
13.97 |
1.016 |
1.008 |
0.8832 |
0.9972 |
DeepSeek-R1-0528#
TP = 4
The table below summarizes DeepSeek-R1-0528 results at TP=4, showing that FP4 and INT4 reduce TTFT and TPOT while maintaining GSM8K accuracy.
Quantization |
TTFT (ms) |
TPOT (ms) |
TTFT Speedup |
TPOT Speedup |
GSM8K |
Accuracy Recovery |
|---|---|---|---|---|---|---|
NONE |
11934.87 |
543.22 |
1.000 |
1.000 |
0.9547 |
1.0000 |
FP4 |
6788.52 |
456.02 |
1.758 |
1.191 |
0.9572 |
1.0026 |
INT4 |
6849.56 |
459.29 |
1.742 |
1.183 |
0.9590 |
1.0045 |
INT6 |
8043.25 |
478.06 |
1.484 |
1.136 |
0.9545 |
0.9997 |
INT8 |
9193.78 |
497.97 |
1.298 |
1.091 |
0.9570 |
1.0024 |
TP = 8
The table below summarizes DeepSeek-R1-0528 results at TP=8, where FP4 and INT4 deliver the lowest TTFT and TPOT among the tested quantization modes.
Quantization |
TTFT (ms) |
TPOT (ms) |
TTFT Speedup |
TPOT Speedup |
GSM8K |
Accuracy Recovery |
|---|---|---|---|---|---|---|
NONE |
1137.01 |
293.43 |
1.000 |
1.000 |
0.9552 |
1.0000 |
FP4 |
755.44 |
214.76 |
1.505 |
1.366 |
0.9537 |
0.9984 |
INT4 |
754.21 |
214.87 |
1.508 |
1.366 |
0.9515 |
0.9961 |
INT6 |
869.40 |
244.08 |
1.308 |
1.202 |
0.9562 |
1.0010 |
INT8 |
1043.71 |
280.02 |
1.089 |
1.048 |
0.9517 |
0.9963 |
Analysis#
At first glance, QuickReduce appears to provide modest gains on smaller models while delivering more significant speedups on larger models. However, the underlying reason is more nuanced.
QuickReduce only activates when the communication volume exceeds a certain threshold. In both vLLM and SGLang, we have configured an activation threshold — when the data volume is below this threshold, the framework falls back to RCCL or Custom AllReduce, whichever is faster. This is why QuickReduce may not show visible speedups in certain scenarios.
For inference engines like vLLM and SGLang, the communication volume during the prefill phase is primarily determined by batch_size, prompt_length, and hidden_size. During the decode phase, prompt_length effectively becomes 1, causing the communication volume to drop significantly. This explains why QuickReduce often has little to no impact on Time Per Output Token (TPOT).
Based on our experiments, FP4 and INT4 exhibit nearly identical performance and accuracy. Either can be used interchangeably.
Summary#
In this blog post, we benchmarked several QuickReduce quantization configurations on MI355. Our findings show that, for message sizes greater than ~1 MB, QuickReduce significantly outperforms both RCCL and Custom AllReduce.
The FP4 and INT4 quantization schemes deliver virtually identical performance and accuracy, making them interchangeable in practice.
It is also important to note that for low communication volumes (e.g., below 1 MB), QuickReduce is not the fastest option. As a result, even with QuickReduce enabled in an inference framework, you may not observe acceleration in all scenarios because the framework automatically falls back to faster alternatives when appropriate.
Configuration Details#
Results were obtained using a system configured with AMD Instinct™ MI355X GPUs. Tests for vLLM were conducted by AMD on May 20, 2026. Actual results may vary depending on system configuration, usage, software version, and applied optimizations.
Software Setup for vLLM#
HIPBLASLT_BRANCH: 1.2.2.70202-86~22.04 (libhipblaslt.so.1.2.70202)
TRITON_BRANCH: 3.6.0
TRITON_REPO: https://github.com/triton-lang/triton.git
PYTORCH_BRANCH: 2.10.0+git8514f05
PYTORCH_REPO: https://github.com/ROCm/pytorch.git (commit 8514f05131610dab50233027b2fab9c01235081b)
PYTORCH_VISION_BRANCH: 0.24.1+d801a34
PYTORCH_VISION_REPO: https://github.com/pytorch/vision.git
AITER_BRANCH: 0.1.13 (amd_aiter)
AITER_REPO: https://github.com/ROCm/aiter.git
VLLM_BRANCH: 0.20.2rc1.dev433+gc38bed424.d20260519.rocm722 (commit c38bed424)
VLLM_REPO: https://github.com/vllm-project/vllm
ROCm: 7.2.2 (HIP runtime 7.2.53211-35e8c7bf89)
System Configuration#
AMD Instinct MI350 platform (gfx950)
System Hostname: smci355-ccs-aus-m06-05
CPU: 2x AMD EPYC 9575F 64-Core Processor (256 logical CPUs)
NUMA: 2 NUMA node(s), 1 NUMA node per socket
node0 CPUs: 0-63,128-191
node1 CPUs: 64-127,192-255
Memory: ~3.0 TiB total
Disk: 1x Micron 7450 14 TB NVMe + 2x Micron 7450 3.5 TB NVMe
GPU: 8x AMD Instinct MI350 (gfx950, 256 CUs each, ~288 GiB HBM each — VRAM total 309 GB/GPU reported)
Host OS: Ubuntu 22.04.5 LTS (Jammy)
Host Kernel: 5.15.0-144-generic
Host GPU Driver (amdgpu / KFD): 6.14.14
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.