Scaling AI Inference Performance with vLLM on AMD Instinct MI355X GPUs#

Today, we are excited to share Large Language Model (LLM) Inference Performance with vLLM on AMD Instinct™ MI355X GPUs. Whether you are a startup, an enterprise or a hyperscaler, the AMD open software ecosystem with Instinct MI355X GPUs delivers consistent, high-performance inference at scale outperforming Nvidia Blackwell B200 GPUs as concurrency grows. For real-world users, this performance impact is directly proportional to user experience and cost efficiency in production environments.
AMD benchmarked MI355X against B200 using the open-source vLLM inference engine, analyzing throughput-latency trade-offs across popular models such as DeepSeek-R1, GPT-OSS-120B, Qwen3-235B, and Llama-3.3-70B. The results show that MI355X delivers consistent, high-performance inference at scale, outperforming B200 as concurrency and context sizes grow, translating into better user experience and lower cost of ownership.
Key Takeaways#
Up to 1.4x higher throughput on DeepSeek-R1 at scale.
Consistent advantage at scale for GPT-OSS-120B and Qwen3-235B workloads.
Competitive performance on Llama-3.3-70B with planned optimizations to close remaining gaps.
Integrated AITER kernels and QuickReduce for optimized MoE/MLA fusion and tensor-parallel communication.
Benchmark Setup#
To ensure a fair evaluation, we benchmarked four leading LLMs DeepSeek-R1, GPT-OSS-120B, Qwen3-235B, and Llama-3.3-70B, using the same inference framework, vLLM, on both AMD Instinct™ MI355X and NVIDIA Blackwell B200 GPUs. This approach minimizes software stack variables and isolates hardware-driven performance differences.
Each model was tested across:
Concurrency levels: 4, 8, 16, 32, 64, and 128 simultaneous requests.
Sequence configurations: Input and output Sequence Length (ISL/OSL)
1024/1024 – Balanced input/output
1024/8192 – Long-form generation
8192/1024 – Large-context summarization
The benchmark configuration above reflects real-world workloads, from interactive chat to document summarization at scale.
Performance at Scale: Where It Matters Most#
Our analysis includes throughput-latency curves for each model, illustrating how performance evolves from low concurrency to high-load production scenarios. The trend is clear: AMD Instinct™ MI355X GPU sustains its advantage as concurrency rises, delivering the scalability that real-world deployments demand.
DeepSeek-R1#
DeepSeek-R1 is a widely adopted open reasoning model built on Mixture-of-Experts (MoE) and Multi-Head Latent Attention (MLA) architectures that demand specialized optimization for peak inference performance. On AMD Instinct™ MI355X GPU, AITER kernels including fused MoE, fused MLA, and additional kernel fusions unlock substantial throughput gains. These optimizations are fully integrated into vLLM with zero developer overhead.
Benchmark Insight: AMD Instinct MI355X GPU consistently outperforms NVIDIA B200 GPU across all concurrency levels. AMD measurements demonstrate up to 1.4x higher throughput on AMD Instinct MI355X GPU over NVIDIA B200 GPU, when serving DeepSeek-R1 at scale.
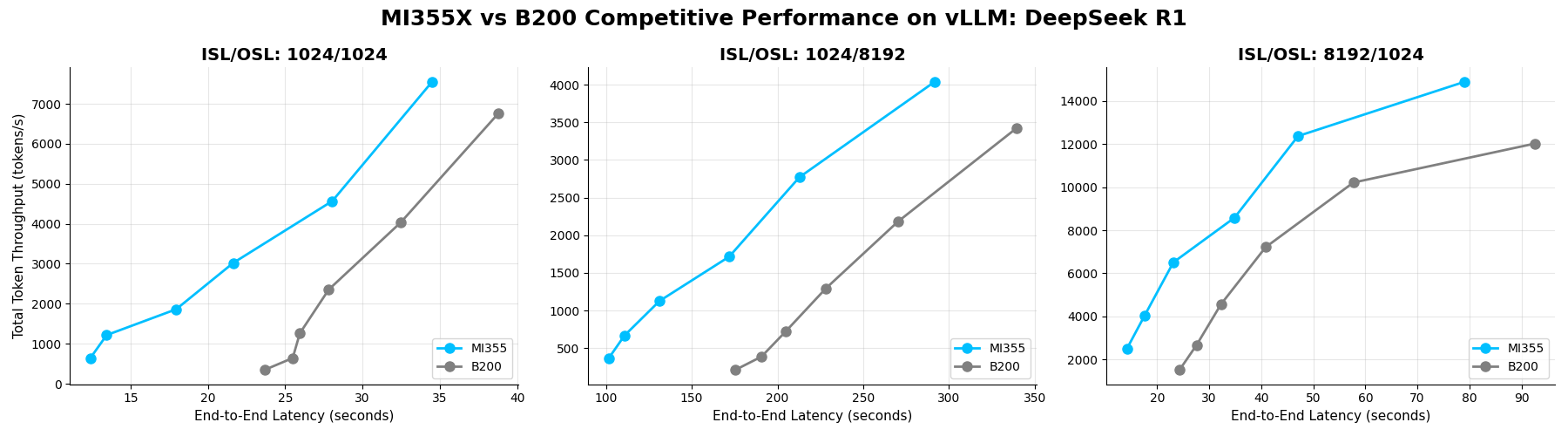
Total Throughput vs E2E Latency on DeepSeek-R1 (FP8) across concurrencies 4, 8, 16, 32, 64, 128 for MI355X and B200 GPUs on vLLM.#
GPT-OSS-120B#
GPT-OSS-120B is OpenAI’s first open-weight LLM, and for this benchmark, both platforms were evaluated using identical configurations, i.e., FP4 quantized weights and BF16 computation to ensure fairness. At low-to-mid concurrency (4–32 requests), B200 shows a slight throughput edge. However, as workloads scale to 64–128 concurrent requests, MI355X GPU takes the lead across most configurations. This advantage at high concurrency translates directly into better economics and user experience for inference services operating at scale.
Benchmark Insight: Across all tested scenarios, MI355X GPU delivers approximately 1.0x aggregate throughput compared to B200 GPU, underscoring MI355X GPU’s ability to sustain performance under demanding conditions.
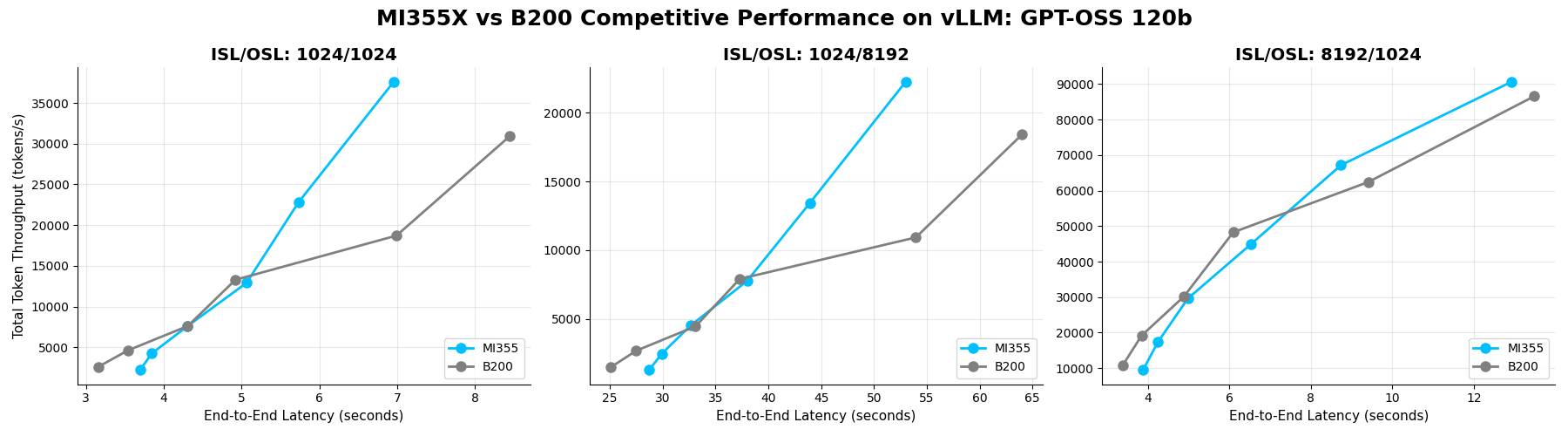
Total Throughput vs E2E Latency on GPT-OSS-120B (FP4) across concurrencies 4, 8, 16, 32, 64, 128 for MI355X and B200 GPUs on vLLM.#
Qwen3-235B#
Qwen3-235B (Qwen3-235B-A22B-Instruct-2507) is a 235B parameter Mixture-of-Experts (MoE) model designed for ultra-long context reasoning (up to 262k tokens). With only 22B active parameters per task, it achieves efficiency comparable to smaller dense models while delivering advanced capabilities for coding, complex reasoning, multilingual tasks, and creative text generation.
Benchmark Insight: Throughput scales linearly across concurrency levels, with minor saturation at 128 concurrent requests for 8k/1k configurations on both GPUs.
Balanced workloads (1k/1k): MI355X GPU shows a consistent edge.
Long-context scenarios (1k/8k and 8k/1k): both GPUs perform similarly.
Overall, MI355X GPU achieves slightly above parity with B200, with a geometric mean of 1.03x across all tested cases underscoring its reliability for demanding, long-context applications.
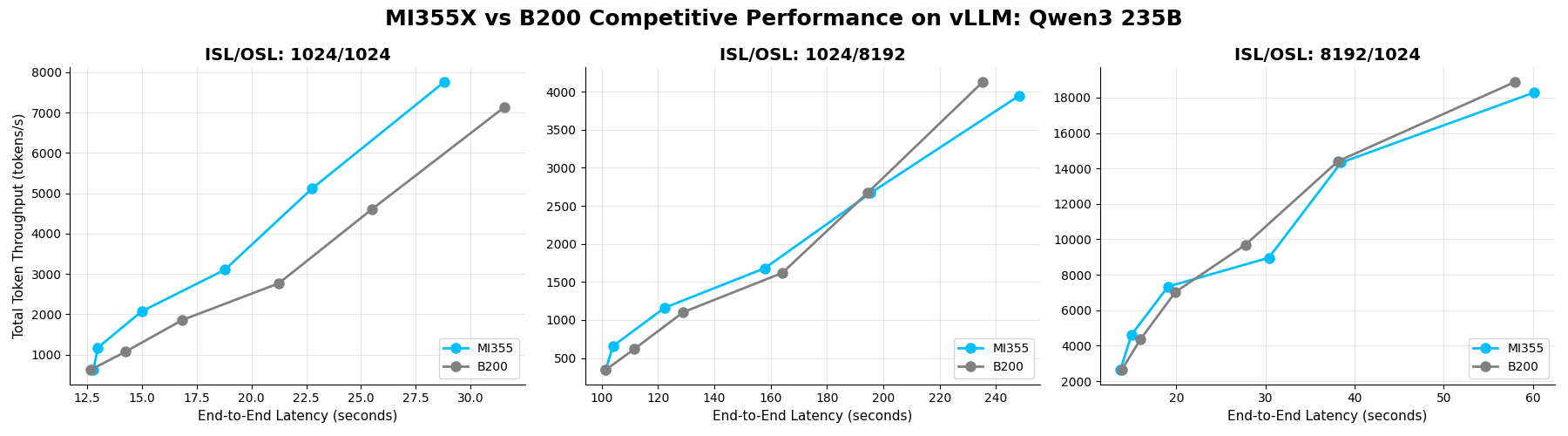
Total Throughput vs E2E Latency on Qwen3-235B (BF16) across concurrencies 4, 8, 16, 32, 64, 128 for MI355X and B200 GPUs on vLLM.#
Llama-3.3-70B#
Llama-3.3-70B is a dense model from the Llama family, built for reasoning, knowledge tasks, and long-context handling. It can be used in TP1 tensor parallelism to maximize throughput. We use this configuration and FP8 quantized weights in this benchmark.
Benchmark Insight:
At low concurrency (4-16 requests), both GPUs scale throughput rapidly with minimal latency impact, and with relative performance being very similar between the two GPUs.
At mid concurrency (32-64 requests) B200 leads due to more efficient kernel implementations and fusions.
At high concurrency (128 requests), performance begins to saturate on B200 on long sequence lengths, while MI355X GPU gains the lead due to higher HBM capacity.
Overall, MI355X GPU delivers 0.94x of B200’s performance across configurations.
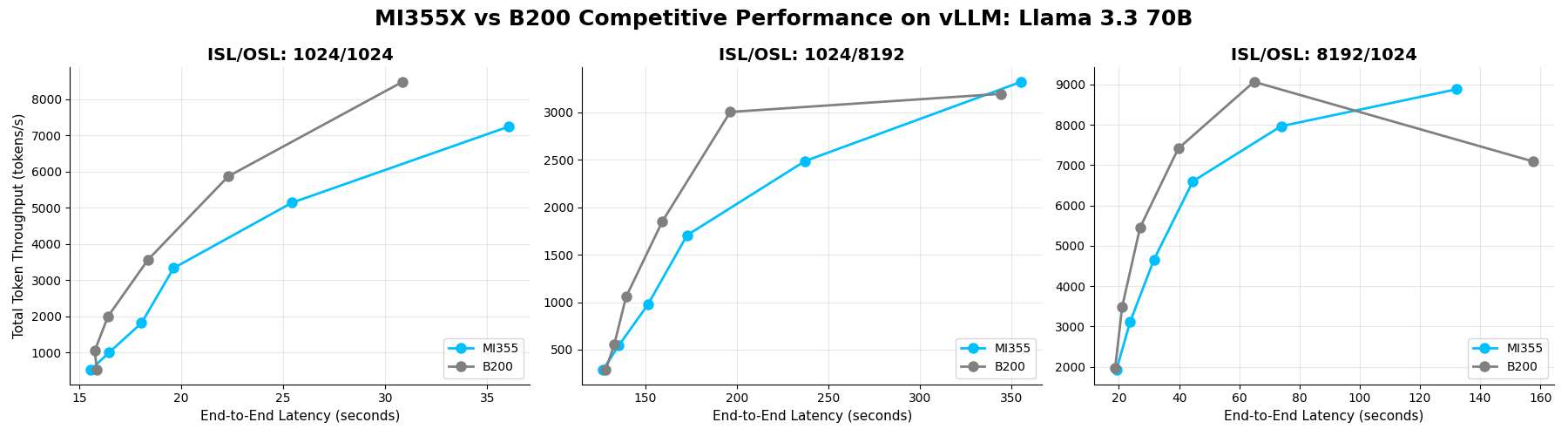
Total Throughput vs E2E Latency on Llama-3.3-70B (FP8) across concurrencies 4, 8, 16, 32, 64, 128 for MI355X and B200 GPUs on vLLM.#
Summary#
In this blog you have learned how the AMD Instinct™ MI355X GPU performs against NVIDIA B200 GPU across several different LLM workloads when using open-source vLLM inference framework.
Our benchmarks demonstrate that AMD Instinct™ MI355X GPU delivers clear performance advantages for production-scale LLM inference. Across models like DeepSeek-R1, GPT-OSS-120B, Qwen3-235B, and Llama-3.3-70B, MI355X GPU performs competitively against B200, achieving up to 1.4x higher throughput on DeepSeek-R1. While B200 may hold a slight edge at low concurrency, MI355X GPU dominates in the mid-to-high concurrency range (64–128 requests) that defines real-world deployments. This scalability advantage comes from superior memory bandwidth and capacity, combined with advanced software optimizations such as AITER kernels for MoE/MLA fusion and QuickReduce for efficient tensor-parallel communication, all integrated seamlessly into vLLM.
For teams deploying LLM inference at scale, these gains translate into:
Higher quality of service under load
Support for larger context windows critical for document summarization and coding assistants
Lower cost per token for inference at scale
MI355X GPU provides the headroom and reliability needed for demanding production environments, where consistent performance at scale is non-negotiable, and upcoming kernel fusion enhancements will push performance even further.
Learn more about our previous work on vLLM from the following ROCm Blogs:
Reproducibility / Tech details#
B200 GPT-OSS-120B and Llama-3.3-70b configurations are used from NVIDIA public recipes while for DeepSeek and Qwen 3 are from our baseline configurations listed below.
Upstream Docker (Coming soon)
DeepSeek-R1#
DeepSeek-R1 on MI355X#
Docker: rocm/7.x-preview:rocm7.2_preview_ubuntu_22.04_vlm_0.10.1_instinct_20251029
MODEL="deepseek-ai/DeepSeek-R1"
export VLLM_ROCM_USE_AITER=1
export VLLM_USE_AITER_TRITON_ROPE=1
export VLLM_ROCM_USE_AITER_RMSNORM=1
export VLLM_ROCM_USE_AITER_TRITON_LINEAR=1
export VLLM_ROCM_QUICK_REDUCE_QUANTIZATION="INT4"
vllm serve ${MODEL} \
--port 8000 \
--swap-space 16 \
--tensor-parallel-size 8 \
--max-num-batched-tokens: 131072 \
--max-seq-len-to-capture 10240 \
--max-model-len: 32768 \
--async-scheduling: true \
--kv-cache-dtype auto \
--quantization fp8 \
--block-size 1 \
--gpu-memory-utilization 0.95 \
--no-enable-prefix-caching: true \
--max-num-seqs 4096 \
--enable-chunked-prefill
DeepSeek-R1 on B200#
Docker: vllm/vllm-openai:v0.10.2
MODEL="deepseek-ai/DeepSeek-R1"
export OMP_NUM_THREADS=1
export MKL_NUM_THREADS=1
export TORCH_ALLOW_TF32_CUBLAS_OVERRIDE=1
export TOKENIZERS_PARALLELISM=true
export TORCH_CUDA_ARCH_LIST="10.0"
export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
export VLLM_USE_V1=1
PORT=8000
vllm serve ${MODEL} \
--host localhost \
--port $PORT \
--swap-space 64 \
--tensor-parallel-size 8 \
--max-num-seqs 1024 \
--no-enable-prefix-caching \
--max-num-batched-tokens 131072 \
--max-model-len 16384 \
--block-size 1 \
--gpu-memory-utilization 0.95 \
--disable-custom-all-reduce \
--max-seq-len-to-capture 10240 \
--async-scheduling \
--kv-cache-dtype auto
GPT-OSS-120B#
GPT-OSS-120B on MI355X#
Docker: rocm/7.0:rocm7.0_ubuntu_22.04_vllm_0.10.1_instinct_20250927_rc1
MODEL="openai/gpt-oss-120b"
cat > config.yaml << EOF
compilation-config: '{"compile_sizes":[1,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32,34,36,38,40,42,44,46,48,50,52,54,56,58,60,62,64,66,68,70,72,74,76,78,80,82,84,86,88,90,92,94,96,98,100,102,104,106,108,110,112,114,116,118,120,122,124,126,128,256,512,1024,2048,8192],
"cudagraph_capture_sizes":[1,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32,34,36,38,40,42,44,46,48,50,52,54,56,58,60,62,64,66,68,70,72,74,76,78,80,82,84,86,88,90,92,94,96,98,100,102,104,106,108,110,112,114,116,118,120,122,124,126,128,136,144,152,160,168,176,184,192,200,208,216,224,232,240,248,256,264,272,280,288,296,304,312,320,328,336,344,352,360,368,376,384,392,400,408,416,424,432,440,448,456,464,472,480,488,496,504,512,520,528,536,544,552,560,568,576,584,592,600,608,616,624,632,640,648,656,664,672,680,688,696,704,712,720,728,736,744,752,760,768,776,784,792,800,808,816,824,832,840,848,856,864,872,880,888,896,904,912,920,928,936,944,952,960,968,976,984,992,1000,1008,1016,1024,2048,4096,8192], "cudagraph_mode":"FULL_AND_PIECEWISE"}'
EOF
export VLLM_USE_AITER_UNIFIED_ATTENTION=1
export VLLM_ROCM_USE_AITER_MHA=0
export VLLM_ROCM_USE_AITER_FUSED_MOE_A16W4=1
vllm serve $MODEL --port $PORT \
--tensor-parallel-size=8 \
--gpu-memory-utilization 0.95 \
--max-model-len 10368 \
--max-seq-len-to-capture 10368 \
--config config.yaml \
--block-size=64 \
--no-enable-prefix-caching \
--disable-LOG-requests \
--async-scheduling \
Qwen3-235B-A22B-Instruct-2507#
Qwen3-235B-A22B-Instruct-2507 on MI355X#
Docker: amdsiloai/vllm:20251208-qwen3-1999bf5
MODEL="Qwen/Qwen3-235B-A22B-Instruct-2507"
export VLLM_ROCM_QUICK_REDUCE_QUANTIZATION=INT4
export VLLM_V1_USE_PREFILL_DECODE_ATTENTION=1
export VLLM_ROCM_USE_AITER=1
export VLLM_ROCM_USE_AITER_MHA=1
export SAFETENSORS_FAST_GPU=1
vllm serve ${MODEL} \
--tensor-parallel-size 8 \
--max-num-seqs 256 \
--max-num-batched-tokens 8192 \
--compilation-config '{"custom_ops": ["-rms_norm", "-quant_fp8"], "cudagraph_mode": "FULL_AND_PIECEWISE"}' \
--no-enable-prefix-caching: true
Qwen3-235B-A22B-Instruct-2507 on B200#
Docker: vllm/vllm-openai:v0.11.2
MODEL="Qwen/Qwen3-235B-A22B-Instruct-2507"
vllm serve ${MODEL} \
--tensor-parallel-size 8 \
--no-enable-prefix-caching
Llama-3.3-70B#
Llama-3.3-70B on MI355X#
Docker: amdsiloai/vllm:rocm7.2_preview_ubuntu_22.04_vllm_0.10.1_instinct_20251120
MODEL=amd/Llama-3.3-70B-Instruct-FP8-KV
export VLLM_ROCM_USE_AITER_MHA=1
export VLLM_ROCM_USE_AITER=1
export VLLM_ROCM_QUICK_REDUCE_QUANTIZATION="INT4"
export VLLM_ROCM_USE_AITER_TRITON_FUSED_ROPE_ZEROS_KV_CACHE=1
vllm serve ${MODEL} \
--port 8000 \
--swap-space 64 \
--tensor-parallel-size 8 \
--max-num-batched-tokens: 8192 \
--max-seq-len-to-capture 10240\
--max-model-len: 10240\
--kv-cache-dtype: fp8 \
--async-scheduling: true \
--compilation-config '{"custom_ops": ["-rms_norm", "-quant_fp8", "-silu_and_mul"]}' \
--gpu-memory-utilization 0.94 \
--no-enable-prefix-caching: true \
--max-num-seqs 512
Endnotes#
Based on testing by AMD Silo AI on 05-Dec 2025, DeepSeek-R1 (FP8), GPT-OSS 120B (FP4), Qwen3 (BF16), and Llama 3.3 70B (FP8) were tested with a maximum sequence length of 8192 tokens using a maximum batch size of 128. Server manufacturers may vary configurations, yielding different results. Performance may vary based on the use of the latest drivers and optimizations.
AMD system configuration: Dual Core AMD EPYC 9575F 64-core processor, AMD Instinct MI355X 8x GPU platform, 3072 GiB RAM (24 DIMMS, 6400 mts, 128 GiB/DIMM), System BIOS 1.5a, 1 NUMA node per socket, Host OS Ubuntu 22.04.5 LTS with Linux kernel 5.15.0-140-generic, Host GPU driver ROCm 7.0.1 + amdgpu 6.14.14, PyTorch 2.9.0, AMD ROCm 7.0.1 software
NVIDIA system configuration: Dual Core Intel Xeon 6960P 72-core processor, NVIDIA B200 8x GPU platform (NVLink 192G, 1000W), 2304 GiB RAM (24 DIMMS, 6400 mts, 96 GiB/DIMM), System BIOS 1.0, 3 NUMA nodes per socket, Host OS Ubuntu 22.04.5 LTS with Linux kernel 5.15.0-151-generic, GPU driver: 580.105.08, CUDA 13.0 (MI350-073)
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.