Using Reinforcement Learning to Fix Text in AI-Generated Videos#

One common giveaway that a video is AI-generated is the text. Letters may look slightly malformed or nonsensical, words can be misspelled and full sentences can have grammatical errors. Improving text generation in videos isn’t just a cosmetic issue - it is essential to generate the prompted text precisely, lest the message become confusing, unprofessional, and potentially misleading. This is an excellent case for leveraging reinforcement learning to improve a video generation model on a specific task without requiring massive amounts of suitable training data.
In this blog, we explore how online reinforcement learning can be applied to fine-tune video generation models so they generate text more accurately. Our approach builds on the paper Flow-GRPO: Training Flow Matching Models via Online RL, where the authors introduce Flow-GRPO, a method for fine-tuning Flow Matching models with reinforcement learning.
Flow-GRPO was originally designed to generally improve text-to-image (T2I) models, including visual text rendering. We’ll apply the authors’ framework to video generation—specifically to Wan text-to-video (T2V) models. We show that the same technique sharpens text fidelity in videos while preserving the overall video quality. If you wish to learn more about fine-tuning T2V models first, check out our blog post on Wan fine-tuning.
To make this practical, we’ll walk through how to implement Flow-GRPO on AMD Instinct GPUs, with code examples, training results, and generated video samples included.
If you’re ready to dive in, fire up your terminal and read on!
Background#
Here’s a brief introduction to the technologies we’ll use, including technical challenges specific to training T2V models with reinforcement learning and how Flow-GRPO solves them. If your terminal is already anxious to start the training, skip to the Step-by-Step Instructions further below.
Reinforcement Learning#
Reinforcement Learning (RL) is a branch of machine learning focused on training agents to make decisions by interacting with an environment. Instead of learning from a fixed dataset, as in supervised learning, an RL agent learns by trial and error—receiving feedback in the form of rewards or penalties for its actions.
At its core, RL is built on three components:
Agent – the decision-maker (e.g., a model generating video frames).
Environment – the world the agent interacts with (e.g., the training loop simulating prompts and outputs).
Reward function – the feedback signal that tells the agent how well it’s performing (e.g., how accurate generated text is).
The agent’s goal is to maximize its cumulative reward over time. To do this, it learns a policy, which is essentially a strategy for deciding which action to take in a given situation to maximize the expected reward.
Online RL means the training data is actively collected by the agent, e.g. the model generates videos and is rewarded based on how accurately the textual content matches to the prompts. This is opposed to offline RL where training data is pre-collected, or pre-generated, mandating the agent to only work with what’s in the dataset, prohibiting it from exploring new actions.
Why does this matter for video generation? State-of-the-art AI video generation (e.g. Wan) relies on training models to produce images from random noise using static datasets. While powerful, this process doesn’t capture nuanced requirements like “render text exactly as prompted.” Addressing such constraints using supervised training alone would demand large collections of prompt–output pairs with perfectly aligned text.
RL, on the other hand, allows us to directly optimize models based on custom feedback signals—whether that’s sharper text, smoother motion, or higher aesthetic quality. In our case the reward is given by Optical Character Recognition (OCR), which compares the generated text to the prompt and outputs a score of how closely the characters match.
Challenges of using RL for training T2V models come down to a few key factors:
First, RL requires generating samples during training, which is already computationally heavy — and even more so when dealing with videos instead of single images.
Second, effective RL relies on the agent’s ability to explore and try new ways of generating videos, which means it needs to sample stochastically rather than deterministically.
Finally, learning a policy to maximize the reward often involves training an additional value model.
Flow-GRPO#
Flow-GRPO is a recent publication that provides a framework for fine-tuning image and video generation models using online reinforcement learning. Building on the success of RL in advancing large language models (LLMs), the authors adapt these techniques to flow-matching image generation models, while also tackling the computational challenges that arise when applying RL in this context.
Reinforcement learning has proven effective in enhancing the reasoning capabilities of LLMs. A key development is the computationally effective policy algorithm, Group Relative Policy Optimization (GRPO). As introduced in the paper DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models, GRPO enables efficient RL to fine-tune the mathematical reasoning capabilities of the DeepSeek-Coder-Base-v1.5 7B model.
The key idea behind Flow-GRPO is to leverage online RL with GRPO—similar to its use in LLMs—to enhance the capabilities of flow-matching models:
Composition Image Generation: precise control over aspects such as object position, count, and color in generated images.
Visual text rendering: accurate depiction of text exactly as specified in the prompt.
Human preference alignment: the model’s ability to generate images that humans are more likely to prefer over alternative options.
One technical challenge the authors tackle is the mismatch between GRPO and flow matching models. GRPO relies on stochastic sampling to enable the RL agent to explore diverse paths, while flow matching models are inherently deterministic, driven by ordinary differential equations (ODEs). The authors’ solution is to convert the ODEs into equivalent stochastic differential equations (SDEs), which unlock compatibility between GRPO and flow matching.
Additionally, the authors employ de-noising reduction, a technique that reduces the number of de-noising steps during training while retaining the full schedule during inference. This approach substantially lowers data generation costs without compromising model quality.
Figure 1 below, sourced from the paper Flow-GRPO: Training Flow Matching Models via Online RL, gives an overview of the Flow-GRPO training method for T2I models. A prompt is sampled stochastically, enabled by the ODE-to-SDE conversion. De-noising reduction of 10 steps efficiently gathers low-quality but useful image trajectories to explore. Reward function (OCR in our case) informs the GRPO loss to update the policy and the model.
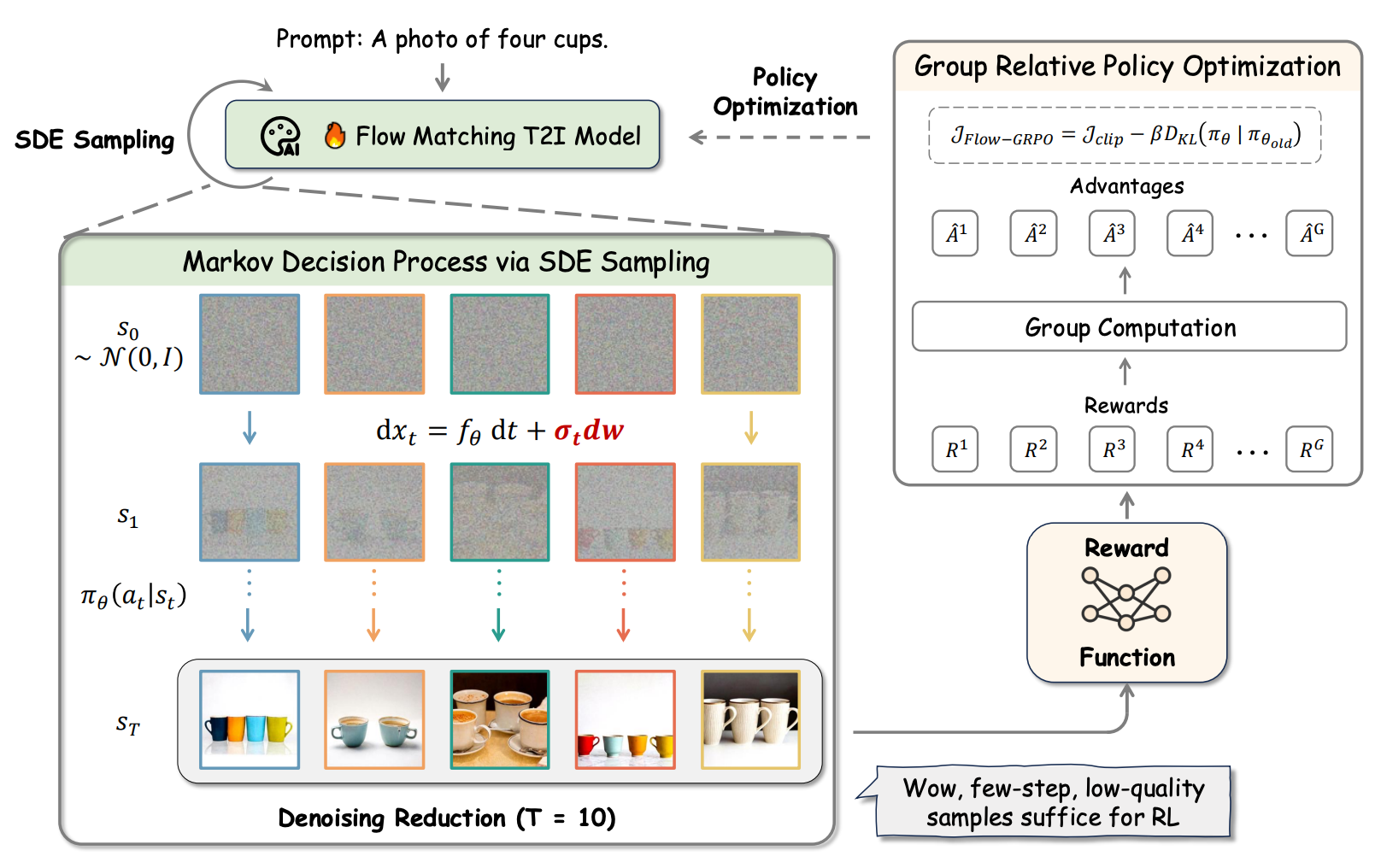
Figure 1. Overview of the Flow-GRPO training method. Liu, Jie and Liu, Gongye and Liang, Jiajun and Li, Yangguang and Liu, Jiaheng and Wang, Xin, “Flow-GRPO: Training Flow Matching Models via Online RL”, arXiv pre-print arXiv:2505.05470, 2025.#
The Flow-GRPO framework primarily targets flow-matching text-to-image (T2I) models, including:
The authors also explore extending this approach to text-to-video (T2V) models, specifically Wan2.1 14B. As we’ll see, the methodology is effective with T2V tasks too.
Step-by-Step Instructions#
Here we’ll walk through using Flow-GRPO to improve text generation in the following Wan T2V models:
Wan2.1 14 billion parameter text-to-video (Wan2.1-T2V-14B-Diffusers)
Wan2.2 14 billion parameter text-to-video (Wan2.2-T2V-A14B-Diffusers)
0. Requirements#
To get started, you’ll need a system that satisfies the following:
GPU : AMD Instinct™ MI300X or other ROCm-compatible GPU
Host Requirements : See ROCm system requirements
This tutorial assumes ROCm 6.3+ and Docker are available on your system.
1. Pull the Docker Image#
docker pull rocm/pytorch-training:v25.6
2. Launch the Docker Container#
Option A: AMD Container Toolkit (Recommended)#
If you have AMD GPUs and the AMD Container Toolkit installed on your system, we recommend using it for better GPU management. Use specific GPU IDs as we have used four GPUs in the example.
docker run -it --rm --runtime=amd \
-e AMD_VISIBLE_DEVICES=0,1,2,3 \
--shm-size=32g \
--name flow-grpo \
-v $(pwd):/workspace -w /workspace \
rocm/pytorch-training:v25.6 \
/bin/bash
Option B: Traditional Device Mapping#
docker run -it --rm \
--device=/dev/kfd \
--device=/dev/dri \
--group-add=video \
--name flow-grpo \
-v $(pwd):/workspace -w /workspace \
rocm/pytorch-training:v25.6 \
/bin/bash
3. Set up the environment#
3.1 Clone the repository#
From inside the container, start by cloning the official Flow-GRPO repository.
git clone https://github.com/yifan123/flow_grpo.git
cd flow_grpo
3.2 Install Flow-GRPO#
Since torch is already installed on the image along with some additional dependencies, modify the setup.py file by removing all required packages except:
diffusers==0.33.1ml_collections
and adding one missing requirement:
imageio[ffmpeg]
i.e. replace the contents of setup.py with the following:
from setuptools import setup, find_packages
setup(
name="flow-grpo",
version="0.0.1",
packages=find_packages(),
python_requires=">=3.10",
install_requires=[
"diffusers==0.33.1",
"ml_collections",
"imageio[ffmpeg]",
],
)
Next, install the package with:
pip install -e .
Additionally, if you wish to log your training, install one of the options:
Weights & Biases (W&B), the logger used by Flow-GRPO authors:
pip install wandb
MLflow, the free open-source logger we used:
pip install mlflow
3.3 Install the OCR module#
Install the dependencies for the OCR module.
pip install paddlepaddle-gpu==2.6.2 paddleocr==2.9.1 python-Levenshtein
Open a Python interpreter and execute the lines below to pre-download the OCR model.
from paddleocr import PaddleOCR
ocr = PaddleOCR(use_angle_cls=False, lang="en", use_gpu=False, show_log=False)
By pre-downloading we avoid issues with PaddleOCR when the Flow-GRPO training script launches multiple processes in distributed setups.
3.4 Download the model#
Finally, choose the Wan model and download it from the Hugging Face model repository.
Wan2.1-T2V-14B-Diffusers#
huggingface-cli download Wan-AI/Wan2.1-T2V-14B-Diffusers --local-dir hf_cache/Wan2.1-T2V-14B-Diffusers
Wan2.2-T2V-A14B-Diffusers#
huggingface-cli download Wan-AI/Wan2.2-T2V-A14B-Diffusers --local-dir hf_cache/Wan2.2-T2V-A14B-Diffusers
4. Start the training job#
To start the training job, start by modifying the config file for the training script config/grpo.py to match your run.
Some important values to configure are:
config.pretrained.model- Specify here the local path to the model you downloaded from Hugging Face.config.sample.train_batch_size- Specify the batch size for training.config.sample.num_image_per_prompt- Specify how many samples are generated for each unique prompt.config.sample.num_batches_per_epoch- Specify the number of batches per epoch.
where, according to the authors’ empirical findings, a good relationship to maintain between hyperparameters is:
config.sample.train_batch_size * num_gpu / config.sample.num_image_per_prompt * config.sample.num_batches_per_epoch = 48
You may also find the configurations we used in the Example Results section.
Once you’re done with configuration, you can launch the training job with default Flow-GRPO training script which logs your training using W&B. If you don’t have W&B set up, launching the script lets you interactively skip logging as well.
Alternatively - and how we ran the training - use our modified script where we have replaced W&B with MLflow.
We train on four GPUs in this example:
accelerate launch \
--config_file scripts/accelerate_configs/multi_gpu.yaml \
--num_processes=4 \
--main_process_port 29503 \
scripts/train_wan2_1.py \
--config config/grpo.py:general_ocr_wan2_1
Note
Here, the script scripts/train_wan2_1.py is either the original script in the repository using W&B or our modified script train_wan_mlflow.py using MLflow. If you want to use our script, copy it into the same flow_grpo/scripts/ folder where the original is.
5. Generating Videos#
If you have a finished fine-tuning a model and wish to generate videos, you can use our video generation scripts found in this blog’s repository. The script supports inference on the same distributed setup as the training happened. With the previous training setup available, you can use the steps below to run inference.
Install one requirement for inference missing in the original repository:
pip install ftfy
And run video generation (for example on four GPUs):
accelerate launch --config_file scripts/accelerate_configs/multi_gpu.yaml --num_processes=4 --main_process_port 29505 generate_video.py
This command generates a video based on the settings and prompt defined in generate_video.py -script.
Example Results#
In this section, we’ll take a closer look at how reinforcement learning enhanced text generation in Wan video models. We’ll showcase output examples from the largest models we’ve introduced:
Wan2.1-T2V-14B-Diffusers
Wan2.2-T2V-A14B-Diffusers
We also experimented with smaller versions of the Wan models. While these lighter models trained more quickly, their text rendering and overall video quality fell short of the larger variants:
Wan2.1-T2V-1.3B-Diffusers
Wan2.2-TI2V-5B-Diffusers
We generated pairs of sample videos using our RL trained models and compared them to videos produced by the corresponding base models. For each pair, we used the same prompt with both the fine-tuned and base models. The prompts were randomly selected from the Flow-GRPO test dataset, then edited to better suit video generation by including elements such as camera movements. These edited prompts were created with ChatGPT, which received the original text prompt and was instructed to adapt it for video generation.
An example prompt from the test dataset:
Original prompt
“A futuristic spaceship with sleek, metallic exterior hull markings that boldly spell “Mars Colony One” under the glow of distant stars, set against the dark vastness of space.”
And the edited prompt, with which we also generated the example videos presented for each model:
Edited prompt
“A vast shot opens in the dark expanse of space, scattered with distant stars and a faint red hue from the planet Mars. The camera slowly glides past a futuristic spaceship, its sleek metallic hull reflecting the starlight in soft gradients. Subtle thruster lights pulse along its surface as the camera tilts to reveal bold markings etched across the side: “Mars Colony One.” The letters gleam under the distant cosmic glow. The camera pulls back gradually, capturing the ship’s immense scale as it drifts silently through the endless void.”
Both the original and edited prompts include the text to be rendered in quotation marks, which is important for computing the reward. The OCR extracts any text from the videos and compares it with the text specified in the prompt. If the recognized text exactly matches the prompt, a reward of 1.0 is given. The score decreases depending on how many of the letters would have to be changed to make the text an exact match. If no matching text is found—or if no text is detected at all—the reward is 0.0.
Figure 2 below shows how the OCR reward improved during training for each model. The best results came from Wan2.1 14B, which increased from 0.55 to 0.79. The smaller Wan2.2 5B model also improved—from 0.32 to about 0.68. The Wan2.2 14B model improved too, though less than Wan2.1 14B, which is interesting since it’s the more advanced version in terms of general video quality. Finally, the Wan2.1 1.3B model improved but produced weaker OCR results, as we expected given its small size.
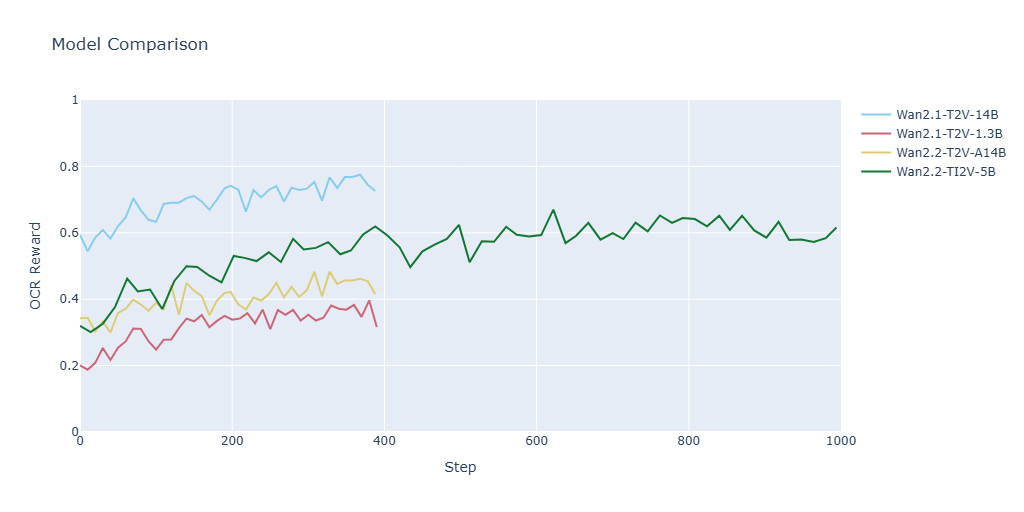
Figure 2. OCR reward curves for all the tested Wan T2V models. Every fifth step is plotted for readability.#
Training Configuration#
For training the Wan2.1 and Wan2.2 14B parameter models, we modified the following default configuration settings:
config.pretrained.model = "hf_cache/Wan2.1-T2V-14B-Diffusers"
config.height = 512
config.width = 512
config.frames = 1
config.sample.train_batch_size = 9
config.sample.num_image_per_prompt = 12
config.sample.num_batches_per_epoch = 16
config.sample.test_batch_size = 8
config.num_epochs = 200
config.save_freq = 10
config.eval_freq = 20
Note
With this configuration, we generate only a single frame, effectively using the T2V model as a T2I model. While this may seem unusual, our rationale is that it significantly reduces training time, while preserving the overall video generation performance of the T2V model.
Model Output Showcase: Wan2.1-T2V-14B#
Here are five pairs of videos generated from five different prompts with the Wan2.1 14B base model and our RL fine-tuned model.
Prompt 1#
The first prompt we used was:
Prompt 1
“A mist-shrouded mountain trail winds through dense, fog-covered trees and jagged rocks, the air thick with silence and mystery. The camera moves slowly along the narrow path, mist swirling around mossy stones and fallen branches. As the fog parts, a weathered wooden signpost emerges from the haze, its surface damp and splintered with age. The camera zooms in gently to reveal the carved words “Beware of Yetis”, barely visible beneath a sheen of moisture. Distant echoes of wind and shifting branches heighten the tension as the camera pulls back, leaving the trail fading into misty obscurity.”
Figure 3 shows the videos generated from prompt 1 side-by-side, with the base model’s output on the left and the RL fine-tuned model’s output on the right. Both models render the text nearly correctly, but the sign in the base model’s output reads “BEWARE YO YETIS,” while the RL fine-tuned model’s output reads “BEWARE YETIS,” omitting the word “of” from the prompt. Both outputs depict a visual scene consistent with the prompt—a mountain trail shrouded in thick fog. However, the camera movement in both videos is minimal and does not follow the prompt’s instruction to track the trail and gradually reveal the sign. In addition, the RL fine-tuned output shows noticeable visual distortions, suggesting that the training hyperparameters may need further adjustment to prevent the model’s visual quality from degrading when it is fine-tuned for text rendering and rewarded solely on text correctness.
Figure 3. Video outputs from the base Wan2.1 14B model and the RL fine-tuned Wan2.1 14B model for prompt 1.
Prompt 2#
The second prompt was:
Prompt 2
“A vast shot opens in the dark expanse of space, scattered with distant stars and a faint red hue from the planet Mars. The camera slowly glides past a futuristic spaceship, its sleek metallic hull reflecting the starlight in soft gradients. Subtle thruster lights pulse along its surface as the camera tilts to reveal bold markings etched across the side: “Mars Colony One.” The letters gleam under the distant cosmic glow. The camera pulls back gradually, capturing the ship’s immense scale as it drifts silently through the endless void.”
Figure 4 presents the videos generated from prompt 2, where the RL fine-tuned output renders the text more accurately, reading “MARS COLLONY ONE”, though it includes an extra “L.” In contrast, the base model’s output is less accurate and inconsistent between frames, producing “MIARS CALLIONE” or “MIARS COUOONE.” Similar to the first video pair, the camera movement does not follow the prompt’s instructions. In the base model’s output, the camera moves around quickly, while in the RL fine-tuned output the movement is slower but minimal.
Figure 4. Video outputs from the base Wan2.1 14B model and the RL fine-tuned Wan2.1 14B model for prompt 2.
Prompt 3#
The third prompt was:
Prompt 3
“A warm, inviting bakery interior glows in the soft light of a sunny morning. The camera pans slowly across a wooden counter, where rows of freshly baked cookies and golden pastries rest on cooling racks, their aroma seeming to fill the air. At the center of the counter sits a large, vintage cookie jar, its surface slightly worn with age, proudly labeled “Emergency Sugar Supply.” The camera lingers on the jar, then pulls back gently, revealing the cozy charm of the bakery — flour-dusted counters, rustic shelves, and the comforting hum of a busy morning.”
Figure 5 shows the videos generated from prompt 3. The RL fine-tuned model renders the text almost correctly as “emergency suger supply,” still misspelling “sugar.” The base model also misspells “sugar,” but its output is less accurate overall, producing “emergency suger spplley.” In the base model’s output, the camera zooms in and out, creating an inconsistent pull-back effect, while in the RL fine-tuned output the camera movement is again minimal.
Figure 5. Video outputs from the base Wan2.1 14B model and the RL fine-tuned Wan2.1 14B model for prompt 3.
Prompt 4#
The fourth prompt was:
Prompt 4
“A calm coastal morning sets the scene, waves gently lapping against the shore. The camera moves slowly across the sandy beach, revealing a neatly arranged set of scuba gear resting near the waterline — fins, mask, regulator, and wetsuit catching the soft sunlight. The focus shifts to a close-up of a silver scuba tank, its metal surface glistening with tiny grains of sand. A clearly visible tag reads “Air Pressure 3000 PSI.” The camera lingers on the detail, then pulls back gradually, capturing the peaceful atmosphere of preparation before an underwater adventure.”
Figure 6 presents the outputs from prompt 4. In this case, the base model fails to produce any text on the gas cylinder. The RL fine-tuned model, however, attempts to render text that, while blurry, resembles the prompt “air pressure.” The sign on the tank also displays “30000” and “300 PSI,” which are close but not exact matches to the instructions.
Figure 6. Video outputs from the base Wan2.1 14B model and the RL fine-tuned Wan2.1 14B model for prompt 4.
Prompt 5#
The fifth and final prompt used with Wan2.1 was:
Prompt 5
“A tight, cinematic close-up focuses on the top of a pizza box, resting on a wooden counter under warm kitchen lighting. The camera slowly tilts forward, revealing bold red letters printed across the white surface that read “Fresh From Oven.” Tiny wisps of steam rise gently from the box’s edges, hinting at the heat of a freshly baked pizza within. Soft light reflects off the box’s smooth cardboard texture as the camera lingers on the text, capturing the mouthwatering warmth and anticipation of a meal just delivered, before fading out into the cozy kitchen atmosphere.”
Figure 7 shows the outputs from prompt 5. Here the base model fails again to produce meaningful text, while the RL fine-tuned model generates “Fresh From Fim Oven.”
Figure 7. Video outputs from the base Wan2.1 14B model and the RL fine-tuned Wan2.1 14B model for prompt 5.
Model Output Showcase: Wan2.2-T2V-A14B#
Here’s a pair of videos generated with the Wan2.2 14B base model and our fine-tuned model. While this model didn’t improve in text generation as much as the Wan2.1 14B, the model’s higher image and motion quality was maintained well.
The prompt was:
Prompt 6
“A bustling night street scene in Tokyo, filled with glowing neon signs and rainy reflections on the pavement. The camera begins with a wide shot, then slowly tracks forward and upward, panning slightly to reveal a large glowing billboard on the side of a tall building. The billboard displays the text: “WELCOME TO THE FUTURE” in bold neon blue letters with a soft animated flicker, blending naturally into the environment as if it were part of the cityscape. Raindrops create shimmering reflections of the sign on the wet street below, while passing cars briefly obscure the view before the camera rises above them.”
Figure 8 shows the side-by-side outputs for prompt 6, using the Wan2.2 14B base model and our RL fine-tuned version. Both models render the text with minor errors: the base model omits the word “to,” while the fine-tuned model repeats the word “the.” Unlike Wan2.1, the Wan2.2 output does not exhibit image distortions from fine-tuning. In both videos, the camera movement follows the instructions, tracking forward and upward toward the sign. Additionally, the rendered scenes feature more dynamic content, moving cars and raindrops, compared to Wan2.1.
Figure 8. Video outputs from the base Wan2.2 14B model and the RL fine-tuned Wan2.2 14B model for prompt 6.
Summary#
In this blog we showed how to improve video generation models on a specific task such as text generation, without a large training dataset leveraging reinforcement learning. Flow-GRPO provides an excellent framework for RL fine-tuning executed on AMD Instinct GPUs.
As shown, the Flow-GRPO method extends well from image generation to video generation models. The fine-tuned models showed clear improvements in text generation while maintaining overall video quality. However, even the best text-to-video model still fell slightly short of the top text-to-image model in OCR accuracy.
Potential ways to improve include:
Using a more holistic reward that evaluates both text accuracy and overall video quality
Training with multiple generated frames instead of a single one
Experimenting with Flow-GRPO hyperparameters, such as the number of de-noising steps, the momentum term β, and the Kullback–Leibler term
The OCR score is a simple and effective reward signal, but it can lead the model to focus too much on getting the text right—sometimes at the cost of visual and motion quality, noticeable especially in the videos generated by the fine-tuned Wan2.1 14B model. A better approach might combine OCR accuracy with a broader video-quality metric, similar to how Flow-GRPO handles image models. The trade-off, of course, is higher computational cost.
In our experiments, we trained each sample using only one generated video frame. This greatly reduced compute time but may have had an effect on how well the model captured motion and temporal consistency. Flow-GRPO can readily support multi-frame training (by default, scoring every fourth frame), so that’s an area worth exploring. Tuning hyperparameters—such as increasing the number of de-noising steps—may further enhance video quality. Additionally, according to the authors, increasing the momentum parameter β can help maintain image quality by preventing the model from changing too drastically at each training iteration.
This blog outlines our team’s ongoing efforts to enable video generation on AMD Instinct GPUs. We’re closely tracking emerging technologies and products in the video generation space, with the goal of delivering a seamless, high-performance user experience. Our work focuses on simplifying workflows and maximizing performance across a wide range of video generation tasks. For example, see our recent blog posts on Gameplay Video Generation with Hunyuan-GameCraft, 3D World Inference with HunyuanWorld-Voyager, Accelerating Audio-Driven Video Generation: WAN2.2-S2V on AMD ROCm and Design for Serving Video Generation Models with Distributed Inference.
We’re also developing detailed guides and playbooks covering model inference, model serving, and end-to-end workflow management. Stay tuned for our upcoming updates as we continue advancing this field.
Acknowledgements#
We are grateful to the authors of Flow-GRPO: Training Flow Matching Models via Online RL whose work provides the basis and the framework for this blog.
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.