Introducing Instella-Math: Fully Open Language Model with Reasoning Capability#

AMD is thrilled to introduce Instella-Math, a reasoning-focused language model that marks a major milestone for AMD: as far as we know, it’s the first language model trained with long chain-of-thought reinforcement learning entirely on AMD GPUs. Starting from Instella-3B-Instruct, we extended the model’s capabilities through a multi-stage training pipeline—featuring two stages of supervised fine-tuning and three stages of reinforcement learning using the VERL framework —executed entirely on AMD Instinct™ MI300X GPUs. This blog offers an inside look at the training process and highlights Instella-Math’s performance on challenging reasoning benchmarks, demonstrating the strength of both the model and the hardware behind it.
Instella-Math#
Introducing Instella-Math — the first reasoning-centric language model with 3 billion parameters from AMD, fully trained on 32 AMD Instinct MI300X GPUs. Instella-Math is a fully open reasoning language model. Its architecture, training code, weights, and datasets are publicly available, allowing anyone to inspect, use, modify, or build upon the model. In addition, its base model, Instella-3B-Instruct, is fully open and the reasoning SFT is also fully open. Built on the AMD ROCm™ software stack, Instella-Math leverages efficient distributed training techniques, including reinforcement learning across 4 MI300X nodes (8 GPUs each), demonstrating the scalability and performance of AMD hardware for cutting-edge AI workloads. Derived from Instella-3B-Instruct with an identical architecture, Instella-Math is optimized for multi-step logical reasoning, mathematical problem-solving, and chain-of-thought tasks. The training pipeline features two stages of supervised fine-tuning followed by three reinforcement learning stages using the GRPO algorithm, as shown in Figure 1.
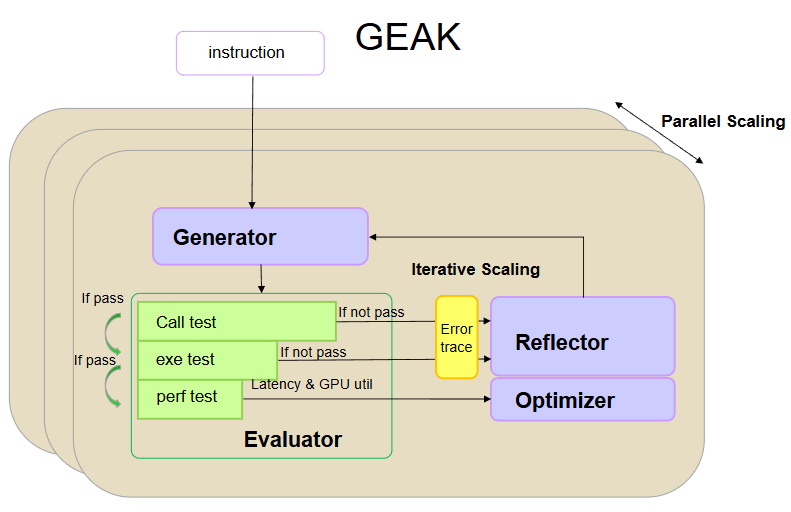
Figure 1. Instella-Math Training Steps#
Supervised Finetuning (SFT)#
We perform a two-stage supervised fine-tuning process to gradually enhance the reasoning capabilities of the Instella-3B-Instruct model. In the first stage we use instruction tuning for mathematical coverage. The second stage enables the model to generate in-depth analyses and structured reasoning steps, which are crucial for tackling complex problems like Olympiad-level math questions.
Stage 1: Instruction Tuning with OpenMathInstruct-2 for Mathematical Coverage#
In the first stage of SFT, we begin with instruction tuning, following instructions or prompts properly, especially in a question-answer or problem-solution format. Using the OpenMathInstruct-2 dataset, which consists of 14 million problem-solution pairs generated from the GSM8K and MATH training sets, the model is trained to follow mathematical prompts covering a diverse range of topics from arithmetic and algebra to probability and calculus.
Stage 2: Deep Reasoning with Long-Context Training on AM-DeepSeek-R1-Distilled#
In the second SFT stage, we further improve the model’s reasoning capability by training on AM-DeepSeek-R1-Distilled-1.4M, which is a large-scale general reasoning dataset containing high-quality and challenging problems. In this stage, we increase the context length of the model from 4K to 32K to allow the model to learn from the long chain-of-thought responses distilled from large reasoning models such as DeepSeek-R1.
Reinforcement Learning (GRPO)#
Stage 1: GRPO with 8 Rollouts and 8K Output Contexts on Big-Math#
Training: In the first stage of reinforcement learning, we apply the Group Relative Policy Optimization (GRPO) algorithm to train the model on Big-Math-RL-Verified, a curated set of complex multi-step math problems. We generate 8 rollouts per prompt, each allowing up to 8K output tokens, to explore diverse reasoning trajectories. The model is trained for 1,200 GRPO steps, using rule-based reward signals designed by Prime-RL that favor correctness of solutions in the desired format. Training is distributed over 16 MI300X GPUs across 2 nodes, with VERL and VLLM enabling stable and efficient rollout collection, reward evaluation, and policy updates.
Stage 2: GRPO with Extended 16 Rollouts and 16K Output Contexts on DeepMath#
Training: To push the limits of long-form reasoning, we conduct a second GRPO stage on DeepMath using 16 rollouts per prompt with up to 16K output tokens. This stage is designed to maximize the model’s capacity for deep mathematical reasoning, enabling it to solve problems that require extended derivations, multiple nested logical steps, or structured proof-like outputs. In this stage, training is distributed over 32 MI300X GPUs across 4 nodes, and the model is trained for 600 GRPO steps.
Stage 3: GRPO with Extended 16 Rollouts and 16K Output Contexts on DeepScaleR#
Training: To further improve the performance on Olympiad-level math questions, we conduct a third GRPO stage on DeepScaleR, which contains original questions from real Olympiad math competitions like AIME (1984-2023) and AMC (prior to 2023). As in Stage 2, Stage 3 training uses 16 rollouts per prompt with up to 16K output tokens. In this stage, training is distributed over 32 MI300X GPUs across 4 nodes, and the model is trained for 740 GRPO steps.
Table 1. Instella-Math evaluation results.#
Following the same evaluation settings as DeepScaleR-1.5B, we report Pass@1 accuracy averaged over 16 responses (as shown in Table 1). Instella-Math delivers competitive performance when compared to leading small-scale open-weight models such as Deepseek-R1-Distilled-Qwen-1.5B, Still-3-1.5B, DeepScaleR-1.5B and SmolLM3-3B. In addition to achieving competitive average performance across all benchmarks, Instella-Math demonstrates the effectiveness of our RL training recipe—improving over its supervised finetuned variant (Instella-Math-SFT) by 10.81 points, compared to a 6.22-point improvement seen in DeepScaleR over its base model (Deepseek-R1-Distilled-Qwen-1.5B).
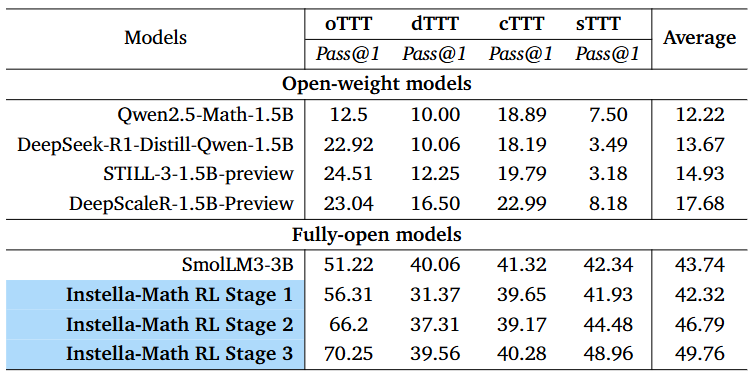
Table 2. Instella-Math evaluation results on TTT-Bench. Here Pass@1 is calculated based on 16 responses per question.#
Additionally, we test Instella-Math on TTT-Bench, a new benchmark targeting strategic, spatial, and logical reasoning. Remarkably, without any exposure to TTT-Bench–style or similar strategic gaming data during any stage of training, Instella-Math achieves the best performance among all evaluated models (as shown in Table 2).
More importantly, like Olmo2 and SmolLM-3B, Instella-Math is a fully-open language model, with fully-open training data for the base model (Instella-3B), reasoning SFT, and reinforcement learning stages. In contrast, many competing models are only open-weight releases; their base model training (e.g., Qwen-1.5B) and reasoning distillation processes (e.g., Deepseek-R1) remain closed.
Summary#
The release of the Instella-Math model marks a major step forward in open-source AI, showcasing the potential of reasoning-focused language models and the scalability of AMD hardware for reinforcement learning and fine-tuning. To our knowledge, Instella-Math is the first fully open math reasoning model that is trained on AMD GPUs. As part of AMD’s commitment to open innovation, we’re sharing the full model weights, training setup, codebase, and datasets to foster collaboration, transparency, and progress across the AI community.
In this blog, we outlined the full training pipeline of Instella-Math, including its supervised fine-tuning stages, multi-phase reinforcement learning process, and performance benchmarks across mathematical reasoning tasks.
We invite researchers, educators, and developers to explore Instella-Math, build on its foundation, and collaborate with us in shaping the next generation of open, interpretable, and high-reasoning language models.
Additional Resources#
Hugging face Model Cards:
Code:
Related Blogs:
Reinforcement Learning from Human Feedback on AMD GPUs with verl and ROCm Integration
PyTorch Fully Sharded Data Parallel (FSDP) on AMD GPUs with ROCm™
Accelerating Large Language Models with Flash Attention on AMD GPUs
Accelerate PyTorch Models using torch.compile on AMD GPUs with ROCm™
Bias, Risks, and Limitations:
The models are being released for research purposes only and are not intended for use cases that require high levels of factuality, safety critical situations, health, or medical applications, generating false information or facilitating toxic conversations.
Model checkpoints are made accessible without any safety promises. It is crucial for users to conduct comprehensive evaluations and implement safety filtering mechanisms as per their respective use cases.
It may be possible to prompt the model to generate content that may be factually inaccurate, harmful, violent, toxic, biased, or otherwise objectionable. Such content may also be generated by prompts that were not intended to produce such output. Users are thus requested to be aware of this and exercise caution and responsible thinking when using the model.
Multi-lingual abilities of the models have not been tested and thus may misunderstand and generate erroneous responses across different languages.
License#
The Instella-3B-Math model is licensed for academic and research purposes under a ResearchRAIL license. Refer to the LICENSE and NOTICES files for more information.
Contributors#
Core contributors: Xiaodong Yu, Jiang Liu, Yusheng Su, Gowtham Ramesh, Zicheng Liu
Contributors: Prakamya Mishra, Sudhanshu Ranjan, Jialian Wu, Ximeng Sun, Ze Wang, Emad Barsoum
Feel free to cite our Instella models:
@misc{Instella,
title = {Introducing Instella: New State-of-the-art Fully Open 3B Language Models with Stellar Performance},
url = {https://huggingface.co/amd/Instella-3B},
author = {Jiang Liu, Jialian Wu, Xiaodong Yu, Prakamya Mishra, Sudhanshu Ranjan, Zicheng Liu, Chaitanya Manem, Yusheng Su, Pratik Prabhanjan Brahma, Gowtham Ramesh, Ximeng Sun, Ze Wang, Emad Barsoum},
month = {February},
year = {2025}
}
Endnotes#
AMD Instinct™ MI300X platform: CPU: 2x Intel® Xeon® Platinum 8480C 48-core Processor (2 sockets, 48 cores per socket, 1 thread per core) NUMA Config: 1 NUMA node per socket Memory: 1.8 TiB Disk: Root drive + Data drive combined: 8x 3.5TB local SSD GPU: 8x AMD MI300X 192GB HBM3 750W Host OS: Ubuntu 22.04.5 LTS with Linux kernel 5.15.0-1086-azure. Host GPU Driver (amdgpu version): 6.12.12
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.