Instella-T2I: Open-Source Text-to-Image with 1D Tokenizer and 32× Token Reduction on AMD GPUs#

In this blog, we introduce Instella T2I, text-to-image models in the AMD open-source Instella model family built from scratch on AMD Instinct™ MI300X GPUs. We’ll walk through the model architecture, training pipeline, tokenizer innovations, and how the system scales efficiently across MI300X GPUs. Instella-T2I v0.1 sets a new baseline for scalable, high-resolution open-source text-to-image generation. You will also explore how AMD is helping advance this space—and how you can get started with the model today. In Instella-T2I, we build upon the rapid advancements in large language models (LLMs) and investigate the use of decoder-only models as text encoders in T2I models as shown in Figure 1.
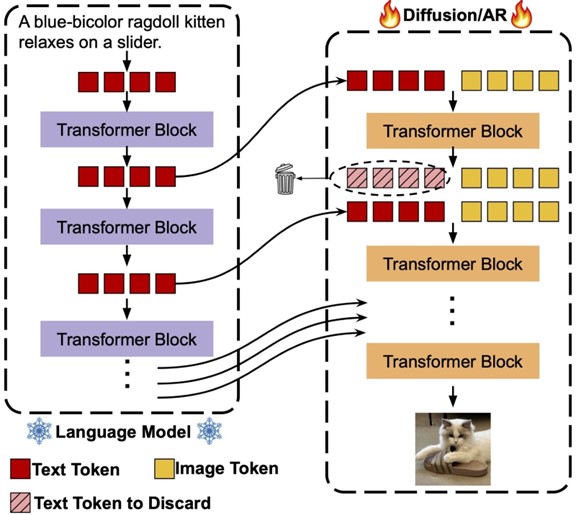
Figure 1. Architecture of the image generation models.#
What is Instella-T2I v0.1#
Instella-T2I v0.1 is the first text-to-image model in the AMD Instella model family, trained exclusively using AMD Instinct MI300X GPUs. By representing images in a 1D binary latent space, our tokenizer encodes a 1024x1024 image using just 128 discrete tokens. Compared to the 4096 tokens typically required by standard VQ-VAEs, our tokenizer achieves a 32x token reduction. Instella-T2I v0.1 leverages our Instella-family language model, AMD OLMo-1B, for text encoding. The same architecture also serves as the backbone for both our diffusion and autoregressive models. Thanks to the large VRAM of the AMD Instinct MI300X GPUs and the compact 1D binary latent space adopted in Instella-T2I v0.1, we can fit 4096 images into a single computation node with 8 AMD Instinct MI300X GPUs, achieving a training throughput of over 220 images per second on each GPU. Both the diffusion and auto-regressive text-to-image models can be trained within 200 MI300X GPU days. Training Instella-T2I from scratch on AMD Instinct MI300X GPUs demonstrates the platform’s capability and scalability for a broad range of AI workloads, including computationally intensive text-to-image diffusion models.
Why a 1D Binary Image Tokenizer#
Traditional latent image representations using 2D latent grids allocate uniform capacity across all image patches. This gridded approach can introduce significant redundancy, which, in turn, introduces excessively long latent token sequences for the T2I model to learn and limits the reconstruction quality of regions with complex features.
By learning 1D latent space representations, the spatial correspondence between the latent space and the image patches is removed, enabling more compact latent representations that can achieve comparable or even superior reconstruction quality, as shown in Figure 2. However, training 1D tokenizers, particularly with discrete latent spaces, can present practical challenges and often require complex model architectures and training strategies. The use of discrete 1D tokenizers for high-resolution image generation remains significantly underexplored.
We developed Instella-T2I to further push the limits of 1D image tokenizers in the discrete latent space for fast and high-fidelity image generation. We specifically focus on generating higher-resolution images than in previous studies on 1D discrete image tokenizers while utilizing the same or fewer latent tokens. To increase the representational capacity of each discrete image token, we adopt a binary latent space approach. Specifically, the Instella T2I tokenizer represents each token as a binary vector rather than a one-hot selection from the codebook. This method allows each latent token to be expressed as a binary combination of elements of a learned codebook, significantly expanding its representational capacity and paving the way for a more compact latent space.
Instella-T2I v0.1 adopts a fully Transformer-based architecture and encodes each image into 128 discrete tokens, each featuring 64 binary elements. The 1D binary tokenizer supports multi-resolution image decoding given the same 128 latent tokens, allowing for a nearly consistent latency when scaling up generation resolution from 512x512 to 1024x1024. For a 1024x1024 image, it demonstrates a 32-fold reduction in discrete token numbers compared to standard VQ-VAEs.
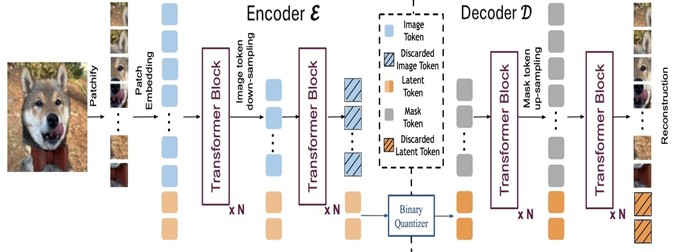
Figure 2. Architecture of the 1D binary tokenizer.#
From Tokenizer to 1D Binary Latent for Image Generation#
T2I models employ dual-stream architecture. The text encoding stream extracts text features from all Transformer blocks of AMD OLMo-1B, which remain frozen throughout the entire T2I model training process. In the image generation stream, we adopt a fully Transformer model with an architecture mirroring that of the LLM. Each Transformer block in the image generation stream receives image features from the preceding block and text features from the same depth of the LLM as input. To align the modalities, a linear layer transforms the text features before concatenating them with the image features as input to a joint text-image self-attention layer.
For Instella-T2I v0.1, we provide two generative models: a diffusion model and an auto-regressive model. For the diffusion and autoregressive models, we employ bidirectional and causal attention for the image tokens, respectively. Since the latent tokens have no predefined spatial order, we use learnable position embeddings initialized randomly in all experiments. Each transformer block learns its own positional embedding, which is added to the image tokens at the start of the block.
Model Training#
The 1D binary latent image tokenizer is trained exclusively using the LAION-COCO dataset.
The training of image generation models employs a two-stage approach. In stage one, the model is pre-trained using the LAION-COCO dataset. We filter the images and reduce the dataset size to 100M, and recapture the images with both short and long captions. In stage two, the data is augmented with synthetic image–text pairs, with a ratio of 3:1 between the LAION and the synthetic data. The synthetic data consists of data from Dalle-1M and images generated from public models. We use the following open models for generating the synthesis data with captions from DiffusionDB:
We generate one image per prompt for each model, using the models’ default hyperparameters.
Evaluation#
We evaluate the image generation results using GenEval to assess the compositionality of the generated results. CLIP and ImageReward scores to evaluate text-image alignment and quality. We compare the Instella auto-regressive and diffusion T2I models against modern text-to-image models, which are primarily trained using massive amounts of private data and computational resources. As shown in the table below, our Instella diffusion model achieves a GenEval score of 0.64, approaching the performance of the Stable Diffusion 3 model with 8 billion parameters, and demonstrating strong results in text-image alignment and complex object composition. The ImageReward score of 0.9 indicates a strong alignment between the generated images and human preferences. While the auto-regressive model does not yet match the performance of the diffusion-based approach, it establishes a solid baseline for auto-regressive image generation in 1D image latent space. We plan to further advance its capabilities by exploring more sophisticated generation techniques, such as masked image modeling and diffusion loss.
Model |
Size |
Reso. |
Single Obj. |
Two Obj. |
Counting |
Colors |
Color Attr. |
Position |
Overall ↑ |
CLIP ↑ |
IR ↑ |
|---|---|---|---|---|---|---|---|---|---|---|---|
SDv1.5 |
0.9B |
512 |
0.97 |
0.38 |
0.35 |
0.76 |
0.06 |
0.04 |
0.43 |
0.318 |
0.201 |
SDv2.1 |
0.9B |
512 |
0.98 |
0.51 |
0.44 |
0.85 |
0.17 |
0.07 |
0.50 |
0.338 |
0.372 |
PixArtα |
0.6B |
1024 |
0.98 |
0.50 |
0.44 |
0.80 |
0.07 |
0.08 |
0.48 |
0.321 |
0.871 |
PixArtσ |
0.6B |
1024 |
0.98 |
0.59 |
0.50 |
0.80 |
0.15 |
0.10 |
0.52 |
0.325 |
0.872 |
SDXL |
2.6B |
1024 |
0.98 |
0.74 |
0.39 |
0.85 |
0.23 |
0.15 |
0.55 |
0.335 |
0.600 |
SD3Medium |
8.0B |
1024 |
0.97 |
0.89 |
0.69 |
0.82 |
0.47 |
0.34 |
0.69 |
0.334 |
0.871 |
Chameleon |
7.0B |
512 |
– |
– |
– |
– |
– |
– |
0.39 |
– |
– |
Emu3 |
8.0B |
1024 |
0.98 |
0.71 |
0.34 |
0.81 |
0.17 |
0.21 |
0.54 |
0.333 |
0.872 |
Instella AR |
0.8B |
1024 |
0.96 |
0.43 |
0.40 |
0.80 |
0.14 |
0.08 |
0.46 |
0.313 |
0.538 |
Instella Diff. |
1.2B |
1024 |
0.99 |
0.78 |
0.66 |
0.85 |
0.45 |
0.12 |
0.64 |
0.332 |
0.900 |
Summary#
In this blog, we introduced Instella-T2I v0.1—a 1B-parameter text-to-image model and the latest addition to the open-source Instella family. Built and trained entirely on AMD Instinct MI300X GPUs using only publicly available data sources, providing competitive performance as compared to other image generation models. This release is fully open source—offering model weights, training scripts, configurations, and data recipes—to empower the developer community with reproducible, extensible tools for research and experimentation. We invite developers and researchers to explore, improve, and build on Instella-T2I. Future updates will target higher resolutions, enhanced compositional skills, richer multimodal prompts, and larger-scale training. Stay tuned as the Instella series grows—and help shape what comes next.
Additional Resources#
Bias, Risks, and Limitations#
The models are being released for research purposes only. They are not intended for use cases that require high levels of visual fidelity or factual accuracy, safety-critical situations, health or medical applications, generating misleading images, or facilitating toxic or harmful imagery.
Model checkpoints are made accessible without any safety promises. Users must conduct comprehensive evaluations and implement appropriate safety filtering mechanisms as per their respective use cases.
It may be possible to prompt the model to generate images that are factually inaccurate, harmful, violent, toxic, biased, or otherwise objectionable. Such content may also be produced by prompts that did not intend to generate such output. Users are therefore requested to be aware of this and exercise caution and responsible judgment when using the model.
The model’s multi-lingual abilities have not been tested, and thus, it may misunderstand prompts in different languages and generate erroneous or unintended images.
Endnotes#
AMD Instinct™ MI300X platform: CPU: 2x Intel® Xeon® Platinum 8480C 48-core Processor (2 sockets, 48 cores per socket, 1 thread per core) NUMA Config: 1 NUMA node per socket Memory: 1.8 TiB Disk: Root drive + Data drive combined: 8x 3.5TB local SSD GPU: 8x AMD MI300X 192GB HBM3 750W Host OS: Ubuntu 22.04.5 LTS with Linux kernel 5.15.0-1086-azure. Host GPU Driver (amdgpu version): 6.12.12
Citations#
@article{instella-t2i,
title={Instella-T2I: Pushing the Limits of 1D Discrete Latent Space Image Generation},
author={Wang, Ze and Chen, Hao and Hu, Benran and Liu, Jiang and Sun, Ximeng and Wu, Jialian and Su, Yusheng and Yu, Xiaodong and Barsoum, Emad and Liu, Zicheng},
journal={arXiv preprint arXiv:2506.21022},
year={2025}
}
Core contributors:
Ze Wang, Hao Chen, Benran Hu, Zicheng Liu
Contributors:
Jiang Liu, Ximeng Sun, Jialian Wu, Xiaodong Yu, Yusheng Su, Emad Barsoum
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.