Micro-World: First AMD Open-Source World Models for Interactive Video Generation#

World models aim to simulate aspects of the real world, enabling more effective training and exploration of AI agents and ultimately paving the way toward richer forms of digital life. Games can be viewed as another form of world simulation, and their data is relatively easy to collect and annotate, making them a natural playground for building and studying world models. GameNGen [1] has demonstrated the potential of this direction, while works such as GameFactory [2], Matrix-Game [3], and Hunyuan-GameCraft [4] further showcase strong performance in game-oriented world modeling. However, these projects are either fully closed-sourced or release only partial components (typically inference-only), which limits reproducibility and community-driven progress.
In this blog, we introduce Micro-World, an action-controlled interactive world model designed to generate high-quality, open-domain scenes. The name Micro-World reflects our motivation to study world modeling through compact, controllable environments. Our training data is collected from Minecraft, a minimal yet expressive game world, and our models are intentionally designed to be lightweight and efficient, enabling practical training and deployment.
Built on top of the Wan2.1 [5] family of models, we train both image-to-world (I2W) and text-to-world (T2W) variants to support a wide range of use cases. To foster open research and practical adoption within the community, we release the model weights, complete training and inference code, and a curated dataset specifically tailored for controllable world modeling. Our evaluations demonstrate that Micro-World can generate high-quality video while faithfully following the provided action instructions.
The key takeaways of our blog are outlined below (see also Figure 1):
Data Collection: We collected over 6,000 gameplay clips, each consisting of 81 frames. The dataset includes both keyboard and mouse actions to enable flexible control, and each clip is annotated with text captions and action labels.
Open-Domain Control: Micro-World accepts action inputs and generates controllable videos in open-domain scenarios.
Model Design: We design a dedicated action processing module that separately encodes continuous mouse actions and discrete keyboard actions. Action features are injected into the model using either ControlNet or Adaptive Layer Normalization (adaLN).
Fully Open-Sourced: Built upon Wan 2.1, Micro-World is fully open-sourced, including the curated dataset as well as the complete training and inference code.
AMD ROCm™ Software Support: The model is fully trained and deployed on AMD Instinct™ GPUs within the ROCm ecosystem.
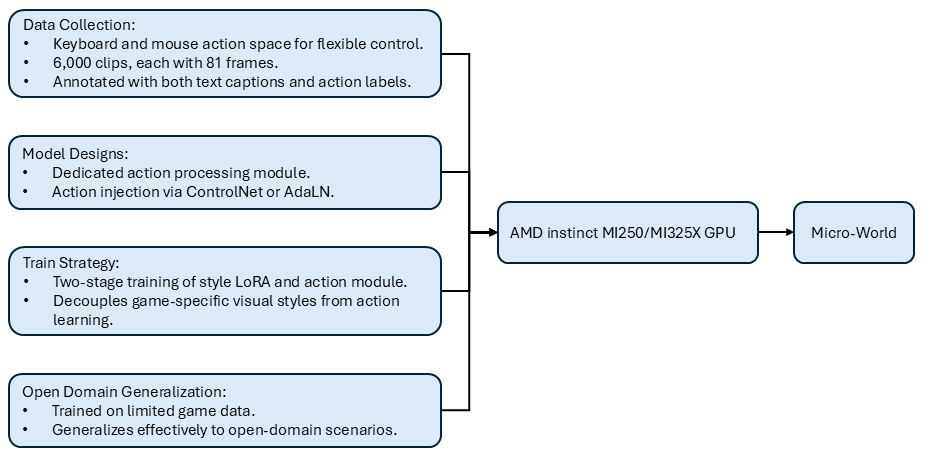
Figure 1. Key takeaways.#
AMD Solution for World Modeling#
Most existing world-model research in the gaming domain focuses on overfitting to a single game environment. For instance, GameNGen [1] accurately simulates Doom, modeling not only player actions but also UI elements such as the health indicators. Similarly, works such as Playable Game Generation [6] for Mario and Oasis [7] for Minecraft remain constrained to their respective game environments. As a result, these approaches struggle to generalize beyond the domains on which they are trained.
However, game data should be regarded as a means rather than an end. The broader objective is to leverage game environments as a proxy for learning transferable world dynamics that extend to open-domain scenarios. Recent efforts such as GameFactory [2] and Matrix-Game [3] take encouraging steps in this direction by attempting to transfer knowledge learned from game data to real-world contexts, thereby motivating further exploration in this area. Despite their promising ideas, these approaches are either not open-sourced or only partially released, which limits reproducibility and slows progress within the open-source community.
In this blog, we present an open-domain world model designed to address these limitations. Inspired by GameFactory [2], we adopt a two-stage training paradigm to transfer action knowledge from game environments to open-domain control. In the first stage, we train LoRA [8] weights to adapt the base model to game-style visual distributions. In the second stage, we introduce an action module and jointly learn action control while merging the trained LoRA weights. This design allows the action module to decouple from game-specific visual styles and focus on learning generalized action dynamics. At inference time, the LoRA weights can be removed, enabling the model to operate directly in open-domain scenarios.
To foster transparency and accelerate research in world-model development, we fully open-source our contributions, including model weights, complete training and inference pipelines, and a curated dataset.
Technical Details#
Data Collection#
Although numerous action datasets exist for training, most suffer from severe imbalances in action class distributions. For instance, during real gameplay, players press the forward key far more frequently than the backward key, which can bias the model and hinder effective action learning. GameFactory addresses this issue by collecting data through randomly executed actions to achieve a more balanced distribution. However, such random action sequences often result in unnatural movements, leading to abrupt frame-to-frame transitions that impede stable model learning.
To overcome these limitations, we construct our own dataset. Rather than fully randomizing actions at each timestep, we enforce a temporal consistency rule in which each action is maintained for a randomly sampled duration. In addition, we constrain the magnitude of sampled mouse movements to prevent unnatural camera motion and abrupt viewpoint changes.
We leverage the Minecraft API [9] to collect game data, as it enables us to obtain diverse biomes as well as varying weather and lighting conditions—properties that are desirable for improving generalization to real-world scenarios.
For the action space, we record keyboard controls including W (forward), A (left), S (backward), D (right), Ctrl (sprint), Shift (sneak), Space (jump), along with mouse movement. By randomly sampling biomes and executing these actions, we collected 6,000 clips, each consisting of 81 frames, forming our Game dataset. We use miniCPM [10] to generate captions for each clip.
Base Model#
The Wan2.1 series has attracted significant attention from the community. Owing to its strong performance and practical utility, many developers have chosen to build their own models on top of Wan2.1, forming a thriving ecosystem. We also adopt Wan2.1 as our base model to contribute to this collective effort. Our work includes both T2W and I2W variants, built upon Wan2.1 1.3B T2V and Wan2.1 14B I2V, respectively.
Action processing module#
The input actions include continuous mouse actions \(M \in R^{n×2}\) and discrete keyboard actions \(K \in R^{n×7}\), both aligned with the frame sequence. Since past actions can influence the current state, we adopt a sliding history window that groups past and current actions \(A^{i-w}…A^i\) as the input for the current feature \(F^i\).
For mouse actions, we first aggregate the historical and current steps and then apply an MLP to align their feature dimensionality. For keyboard actions, we embed the discrete inputs and add positional encodings. The embedded features are then grouped using the same history window and passed through an MLP for dimensional alignment.
Finally, the mouse and keyboard features are concatenated and processed by another MLP to better match the diffusion model’s feature space. All action features are preprocessed at the beginning of the inverse diffusion process and forwarded to subsequent modules.
Action injection#
There are three primary strategies for injecting action information into the model:
Direct fusion through addition or concatenation of action features with noise features.
Cross-attention based integration, which enables the model to capture intra-domain relationships.
Adaptive Layer Normalization (adaLN [11]), where action features are encoded together with the timestep embedding.
We experimented with all three approaches and selected adaLN [11] and ControlNet [12]. ControlNet is used in the T2W model (Figure 2(c)), while adaLN is adopted for the I2W model (Figure 2(b)). We choose adaLN for its lightweight parameter footprint, and ControlNet for its learning capability. The overall module architecture is illustrated in Figure 2.
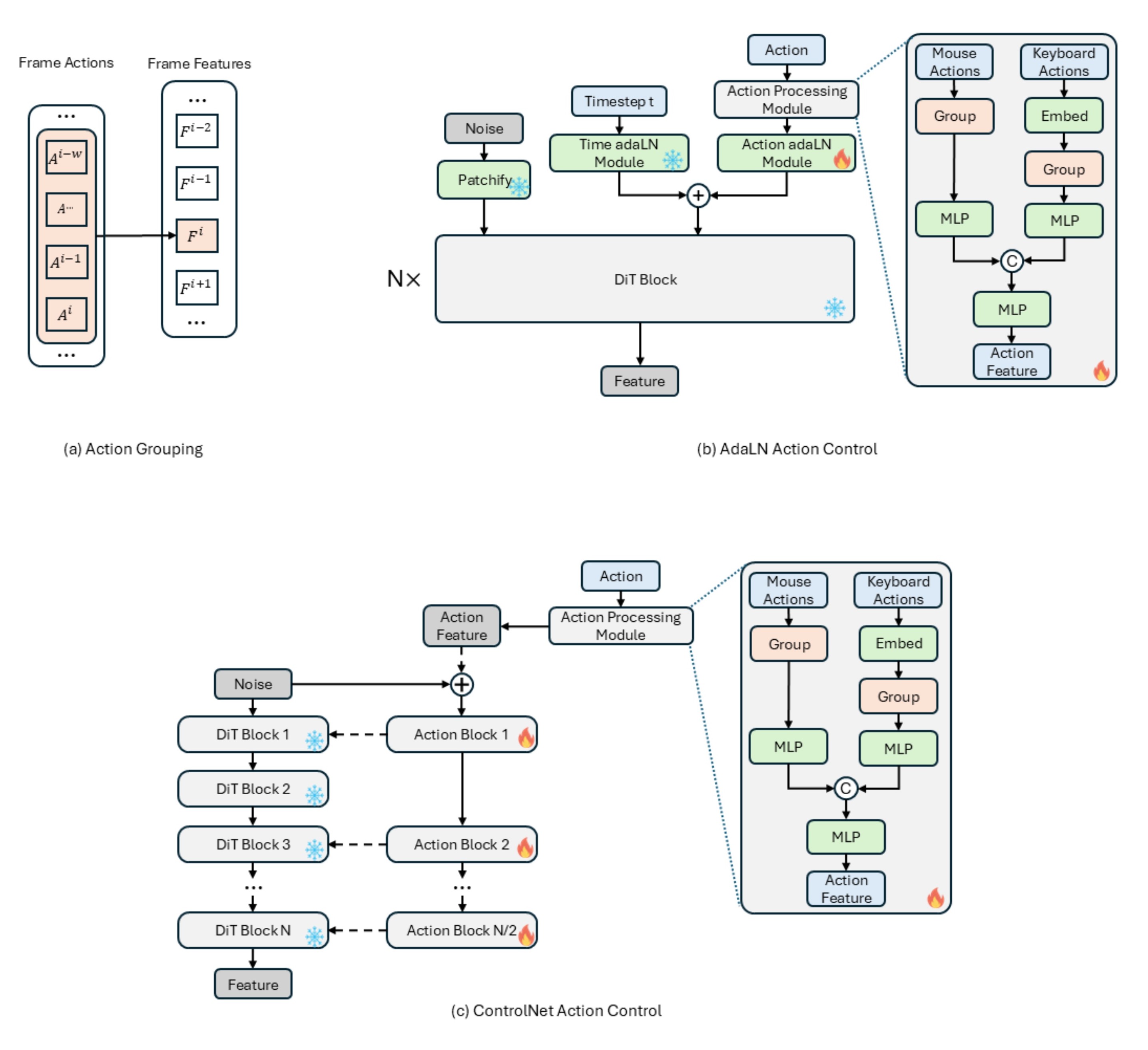
Figure 2. (a). Action grouping process. (b). AdaLN formulation. (c). ControlNet formulation. Dashed arrows indicate the zero linear process.#
Multi-Stage Training#
A major challenge in open-domain action control is data scarcity—collecting and annotating large-scale, diverse action datasets is often impractical. To address this, we adopt a two-stage training strategy. In the first stage, we train the model on the game dataset to learn a game-style LoRA, capturing domain-specific style and appearance priors. In the second stage, we merge this LoRA into the base model and train only the action module to learn generalizable action control, independent of the stylistic biases from the game data.
It is important to note that the original model parameters remain frozen during both stages. This decoupling allows the action module to focus solely on the underlying action dynamics, enabling stronger transferability to open-domain scenarios.
Open-domain Inference#
The model can naturally perform inference on game-style videos. However, for open-domain video generation, we remove the LoRA parameters to drop game style and rely on the knowledge encoded in the base model. Thanks to the decoupling training strategy, the action module remains domain-agnostic and can still drive the model to generate action-controlled videos.
Implementation Details#
Our model is implemented in PyTorch. We also employed advanced training libraries, including Accelerate, Diffusers, and Deepspeed to support multi-machine and mixed-precision training. Training and inference are performed using AMD Instinct MI325X GPUs.
Quantitative Comparison#
To better assess the performance of Micro-World, we evaluate it across multiple dimensions and compare it against Oasis on the GameWorld Benchmark [3].
Image Quality. We adopt standard visual metrics, including FVD, PSNR, and LPIPS, to measure the perceptual quality of the generated videos.
Action Controllability. To evaluate whether the generated videos correctly follow keyboard and mouse inputs, we introduce keyboard precision and camera precision. Specifically, an Inverse Dynamics Model (IDM) is used to predict actions between two consecutive generated frames, and the predicted actions are then compared against the input actions.
Temporal Quality. We assess temporal consistency and motion smoothness to measure the stability of backgrounds and scene dynamics over time.
| Model | Image Quality | Action Controllability | Temporal Quality | ||||
|---|---|---|---|---|---|---|---|
| PSNR ↑ | LPIPS ↓ | FVD ↓ | Keyboard Precision ↑ | Camera Precision ↑ | Temporal Consistency ↑ | Motion Smoothness ↑ | |
| Oasis | 14.90 | 0.5641 | 596.986 | 0.6474 | 0.3770 | 0.9589 | 0.9875 |
| Ours-I2W | 15.88 | 0.4128 | 175.371 | 0.7224 | 0.5055 | 0.9629 | 0.9750 |
Table 1. Game-World Score Benchmark Comparison.
From Table 1, Micro-World I2W outperforms Oasis across image quality, action controllability and temporal quality. These results illustrate the effectiveness of our model for interactive world-models in gaming environment.
| Dataset | Keyboard Precision ↑ | Camera Precision ↑ |
|---|---|---|
| Gamefactory dataset | 0.5209 | 0.2654 |
| Our curated dataset | 0.6009 | 0.3907 |
Table 2. Action Controllability Comparison of T2V in Different Datasets.
To evaluate the quality of our newly curated dataset, we trained the same T2V model on both Gamefactory dataset and our dataset. As shown in Table 2, the model trained on our dataset achieved superior precision on both keyboard and mouse controllability, indicating that the collected data provides more representative information for the task.
Visual Performance#
In this section, we present visual results of Micro-World, including T2W results in both in-domain and open-domain settings, as well as I2W open-domain action-controlled scenarios, shown in Figures 3, 4, and 5, respectively. All videos are generated on an AMD Instinct™ MI325X GPU using AMD ROCm™ software version 7.0.0.
We observe that fully decoupling the action module from game-specific styles in large-scale models remains challenging. As a result, we apply both the LoRA weights and the action module during inference for the I2W open-domain results.
Keyboard and mouse actions are annotated in the visualization. Keyboard controls including W (forward), A (left), S (backward), D (right), Ctrl (sprint), Shift (sneak), Space (jump).
|
S
|
A
|
|
D
|
W+Ctrl
|
W+Shift
|
|
Multiple control
|
Mouse down and up
|
Mouse right and left
|
Figure 3. T2W in-domain results.
View Prompt
A cozy living room with sunlight streaming through window, vintage furniture, soft shadows.
|
View Prompt
A cozy living room with sunlight streaming through window, vintage furniture, soft shadows.
|
View Prompt
Running along a cliffside path in a tropical island in first person perspective, with turquoise waters crashing against the rocks far below, the salty scent of the ocean carried by the breeze, and the sound of distant waves blending with the calls of seagulls as the path twists and turns along the jagged cliffs.
|
View Prompt
A young bear stands next to a large tree in a grassy meadow, its dark fur catching the soft daylight. The bear seems poised, observing its surroundings in a tranquil landscape, with rolling hills and sparse trees dotting the background under a pale blue sky.
|
View Prompt
A giant panda rests peacefully under a blooming cherry blossom tree, its black and white fur contrasting beautifully with the delicate pink petals. The ground is lightly sprinkled with fallen blossoms, and the tranquil setting is framed by the soft hues of the blossoms and the grassy field surrounding the tree.
|
View Prompt
Exploring an ancient jungle ruin in first person perspective surrounded by towering stone statues covered in moss and vines.
|
Figure 4. T2W open-domain results.
View Prompt
First-person perspective walking down a lively city street at night. Neon signs and bright billboards glow on both sides, cars drive past with headlights and taillights streaking slightly. camera motion directly aligned with user actions, immersive urban night scene.
|
View Prompt
First-person perspective standing in front of an ornate traditional Chinese temple. The symmetrical facade features red lanterns, intricate carvings, and a curved tiled roof decorated with dragons. Bright daytime lighting, consistent environment, camera motion directly aligned with user actions, immersive and interactive exploration.
|
View Prompt
First-person perspective of standing in a rocky desert valley, looking at a camel a few meters ahead. The camel stands calmly on uneven stones, its long legs and single hump clearly visible. Bright midday sunlight, dry air, muted earth tones, distant barren mountains. Natural handheld camera feeling, camera motion controlled by user actions, smooth movement, cinematic realism.
|
View Prompt
First-person perspective walking through a narrow urban alley, old red brick industrial buildings on both sides, cobblestone street stretching forward with strong depth, metal walkways connecting buildings above, overcast daylight, soft diffused lighting, cool and muted color tones, quiet and empty environment, no people, camera motion controlled by user actions, smooth movement, stable horizon, realistic scale and geometry, high realism, cinematic urban scene.
|
View Prompt
First-person perspective coastal exploration scene, walking along a cliffside stone path with wooden railings, green bushes lining the walkway, ocean to the left with gentle waves, distant islands visible under a clear sky, realistic head-mounted camera view, smooth forward motion, stable horizon, natural human eye level, high realism, consistent environment, camera motion directly aligned with user actions, immersive and interactive exploration.
|
View Prompt
First-person perspective inside a cozy living room, walking around a warm fireplace, soft carpet underfoot, furniture arranged neatly, bookshelves, plants, and warm table lamps on both sides, warm indoor lighting, calm and quiet atmosphere, natural head-level camera movement, camera motion driven by user actions, realistic scale and depth, high realism, cinematic lighting, no people, no distortion.
|
Figure 5. I2W open-domain results.
Summary#
We present Micro-World, a series of action-controlled interactive models designed to showcase the capabilities of AMD Instinct™ GPUs for both training and inference, while establishing a foundation for future research. Through a carefully designed model architecture and training pipeline, Micro-World achieves effective action control in real-world scenarios. Our models demonstrate strong performance in both video quality and action coherence. To support reproducibility and foster further research, we release the model weights, complete training and inference code, and a curated dataset to the open-source community.
In future work, we plan to extend Micro-World toward generating longer action-controlled videos, incorporate more efficient operators, and reduce computational overhead to enable real-time, streaming world models. Stay tuned!
Resources#
Huggingface Model Cards:
Huggingface Dataset Cards:
Code:
Related Work on Diffusion Models by the AMD Team:
Nitro-E: A 304M Diffusion Transformer Model for High Quality Image Generation
Nitro-T: Training a Text-to-Image Diffusion Model from Scratch in 1 Day
Related Technical Blogs on World Models:
Reference#
Valevski, Dani, et al. “Diffusion models are real-time game engines.” arXiv preprint arXiv:2408.14837 (2024).
Yu, Jiwen, et al. “GameFactory: Creating new games with generative interactive videos.” arXiv preprint arXiv:2501.08325 (2025).
Zhang, Yifan, et al. “Matrix-Game: Interactive World Foundation Model.” arXiv preprint arXiv:2506.18701 (2025).
Li, Jiaqi, et al. “Hunyuan-GameCraft: High-dynamic Interactive Game Video Generation with Hybrid History Condition.” arXiv preprint arXiv:2506.17201 (2025).
Wan, Team, et al. “Wan: Open and advanced large-scale video generative models.” arXiv preprint arXiv:2503.20314 (2025).
Yang, Mingyu, et al. “Playable game generation.” arXiv preprint arXiv:2412.00887 (2024).
Decart, et al. “Oasis: A Universe in a Transformer.” https://oasis-model.github.io/ (2024)
Hu, Edward J., et al. “LoRA: Low-rank adaptation of large language models.” ICLR 1.2 (2022): 3.
Fan, Linxi, et al. “Minedojo: Building open-ended embodied agents with internet-scale knowledge.” Advances in Neural Information Processing Systems 35 (2022): 18343-18362.
Yao, Yuan, et al. “MiniCPM-V: A GPT-4V level MLLM on Your Phone.” arXiv preprint arXiv:2408.01800 (2024).
Peebles, William, and Saining Xie. “Scalable diffusion models with transformers.” Proceedings of the IEEE/CVF international conference on computer vision. 2023.
Zhang, Lvmin, Anyi Rao, and Maneesh Agrawala. “Adding conditional control to text-to-image diffusion models.” Proceedings of the IEEE/CVF international conference on computer vision. 2023.
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.