Nitro-AR: A Compact AR Transformer for High-Quality Image Generation#

Recent years have witnessed remarkable progress in image generation, driven by two major modeling paradigms: diffusion-based models and autoregressive (AR) models. Building upon our previously released Nitro-E, a light-weight diffusion model for fast image synthesis, this blog explores a complementary direction, applying the architecture in an AR framework.
We adapt our E-MMDiT model to a masked modeling AR framework. Instead of denoising the whole image at each step, the model is trained to predict a subset of image tokens per step, progressively completing the image. To support continuous token prediction and maintain seamless compatibility with the VAE, we employ an MLP head for token sampling. Figure 1 provides an overview of this architectural adaptation, contrasting the diffusion-based Nitro-E with the masked autoregressive Nitro-AR built on the same E-MMDiT backbone.
Our compact 0.3B-parameter AR model, Nitro-AR, achieves a GenEval score of 0.66, matching the performance of our diffusion-based counterpart Nitro-E and demonstrating the robustness of our architecture across different paradigms. In addition, we explore some designs to accelerate sampling. By applying adversarial fine-tuning to the diffusion prediction head, Nitro-AR’s latency is reduced by 48% with no loss in generation quality. Combining this approach with a more aggressive approach, joint sampling, allows AR generation in a single step, achieving a GenEval of 0.60 while reducing latency by 88%. On a consumer-grade AMD Radeon™ RX 7900 XT GPU, Nitro-AR can generate a 512×512 image in just 0.23 seconds.
Our models and code have been released in line with AMD’s commitment to open-source research. We hope this work provides fresh perspectives on image generation and encourages further exploration in the field.
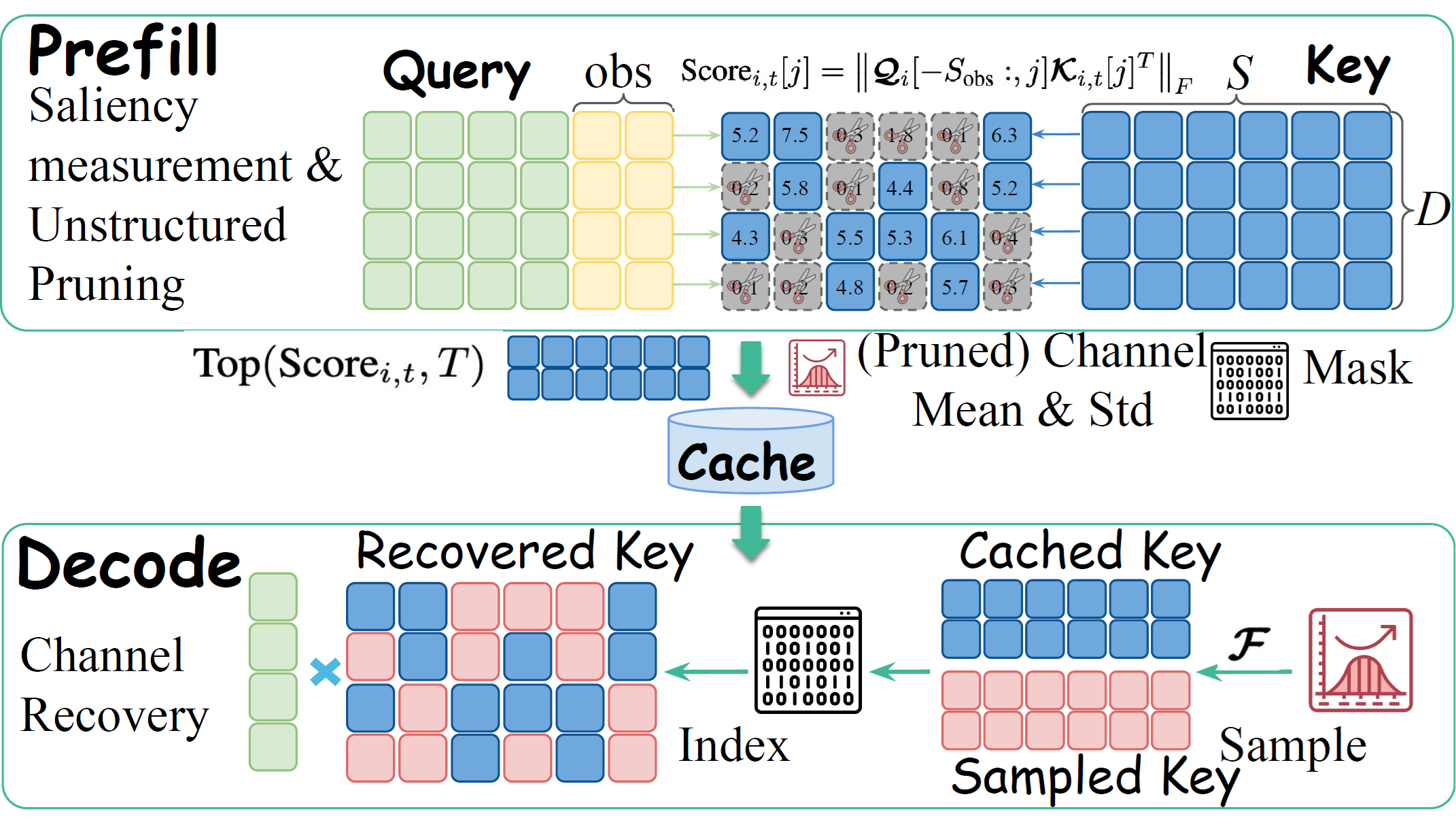
Figure 1. Illustration of the Nitro-E (left) and Nitro-AR (right) models, both built on the E-MMDiT backbone. Nitro-E iteratively removes noise to refine the image, while Nitro-AR progressively generates the image by predicting masked tokens step by step.#
Technical Details#
Masked Modeling AR Model#
The standard and basic form of an AR model is next-token prediction [1], where the model is trained to predict the next token conditioned on the previously generated tokens. Beyond this classical setup, there are several alternative formulations that also gained attention, including next-scale [2], next-neighbor [3] or even generalized next-x modeling [4].
In this work, we focus on another AR variant called masked modeling, which has been adopted by several recent and representative approaches such as MAR [5], Fluid [9], and LightGen [10]. Instead of predicting the next token, the model learns to reconstruct the masked regions conditioned on all visible tokens.
A key challenge for token-prediction models is that tokens are typically defined in a discrete space, as in Large Language Models (LLMs), which limits the expressiveness for images and requires a specific discrete tokenizer for the latent representation. MAR [5] addresses this by introducing a diffusion prediction head on top of the AR transformer, enabling sampling of continuous tokens while seamlessly compatible with any VAE models. We follow this design in our model.
Adapting E-MMDiT to the Paradigm#
E-MMDiT is the transformer architecture used in Nitro-E with several efficiency-oriented designs such as the token compression module, Alternating Subregion Attention (ASA), and AdaLN-affine. Although diffusion and AR paradigms differ (for example, AR models do not require timesteps), the core architecture can be easily adapted. We remove the timestep-injection module and add a diffusion MLP head on top of the E-MMDiT transformer to form our Nitro-AR base model. This simple adaptation works well in practice, achieving similar performance to the Nitro-E model, demonstrating the validity of our architecture.
Building on this base model, we also explore some designs that enable few-step sampling, which is termed as the joint-sampling version. We describe these designs in detail in the following sections.
Joint Sampling#
The original diffusion prediction head in MAR [5] is implemented as a simple Multilayer Perceptron (MLP) that takes the condition vector of each token and samples the continuous token independently without considering the other tokens. This process lacks contextual awareness, which leads to poor performance in few-step settings, such as generation within 1-4 AR steps. As illustrated in Figure 2, independently sampled tokens often result in incoherent structures in one-step generation, whereas joint sampling produces more globally consistent results.
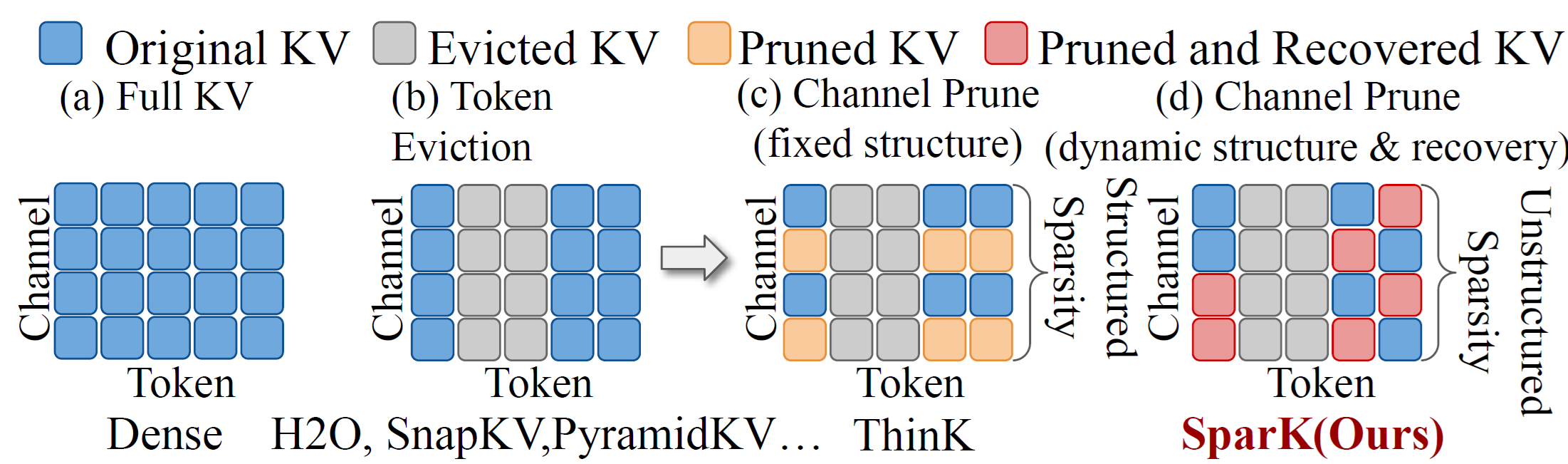
Figure 2. One-step generation results without (left) and with (right) joint sampling. With a standard MLP head, tokens are sampled independently, leading to degraded one-step generation quality. In contrast, joint sampling models token dependencies and produces more coherent results.#
To enable joint sampling and make tokens aware of each other, we replace the MLP head with a small transformer head, following [6]. The self-attention mechanism allows interactions between tokens, making the sampling perform in a joint manner. Although this transformer-based head introduces a modest amount of extra computation, it significantly improves generation quality in low-step sampling settings.
Global Token#
Another challenge we aim to address in Nitro-AR is diversity. Because the model always starts with the same initial state with all tokens masked, the transformer backbone produces the same output for a given prompt. Although the diffusion prediction head introduces some randomness during sampling, the diversity remains limited.
To enhance diversity, we introduce a global token that serves as the initial state of the masked tokens. During inference, we first sample this global token and different global tokens lead to various structural layouts, which in turn produce more diverse samples.
The global token is a special token defined in the same latent space as regular image tokens. It is obtained by resizing the input image to a small thumbnail and encoding it with the VAE. Because predicting such a single token does not require the full transformer backbone or the heavy diffusion prediction head, we instead use features extracted from the first four blocks along with a very lightweight MLP head. This ensures that the additional computational overhead is kept minimal.
Prediction Head Optimization#
The diffusion prediction head typically requires multiple denoising steps to generate image tokens, but many of these steps may be unnecessary. To improve efficiency without sacrificing quality, we explore several strategies to reduce the number of steps required by the head.
Diffusion Step Annealing (DiSA): We first adopt diffusion step annealing (DiSA) [7], a training-free technique designed to decrease the number of diffusion steps as image generation progresses. In early AR iterations when the image structure is still highly uncertain, we use more diffusion steps (e.g., 20 steps). As more tokens become visible and the image stabilizes, we gradually reduce the step count to as few as 5. Because DiSA is derived from empirical observations specific to diffusion-based AR models, it naturally complements other acceleration approaches designed for standalone diffusion models.
Adversarial Fine-Tuning of the Prediction Head: Beyond training-free methods, we apply an optimization that compresses the diffusion process to just 3–6 denoising steps. This is implemented via the Nitro-1 project, which realizes the latent adversarial diffusion distillation (LADD) [8] method, using a GAN-style discriminator. Here, the diffusion prediction head is treated as a generator and fine-tuned adversarially to align few-step generation with the real data distribution, thereby achieving behavior comparable to multi-step diffusion.
Figure 3. Adversarial fine-tuning pipeline: The prediction head is fine-tuned to enable few-step sampling of image tokens. A discriminator is applied to the generated images to align their distribution with that of real data.#
As shown in Figure 3, the adversarial fine-tuning framework follows the same masked-token reconstruction paradigm as Nitro-AR. We randomly mask a subset of image tokens and train the model to reconstruct them. During this stage, the E-MMDiT backbone is frozen, and only the diffusion prediction head (MLP or transformer-based joint sampling) is updated. The goal is to ensure that low-step diffusion generates token latents faithful to the ground-truth distribution.
To this end, we introduce a discriminator that evaluates the realism of reconstructed token latents. It uses the frozen E-MMDiT as a feature extractor, followed by a lightweight MLP head to classify latents as real or generated. Ground-truth token latents from real images serve as positives, while latents produced by the diffusion prediction head under a small number of steps serve as negatives.
The diffusion prediction head is trained with an adversarial loss, encouraging few-step generation to match the real data distribution under a reduced step budget. Empirically, just 6k adversarial iterations enable the Nitro-AR diffusion prediction head to achieve three-step denoising quality comparable to 20-step denoising, outperforming DiSA and substantially reducing sampling latency with minimal quality loss.
Experimental Results#
We train our model using the AMD Instinct™ MI325X GPU with the same amount of data as in Nitro-E. Our implementation is built on the training engine Accelerate with mixed precision training using the Bfloat16 datatype.
Generated Samples by Nitro-AR#

Figure 4. Generated samples by our Nitro-AR model.#
Figure 4 illustrates diverse image samples generated by Nitro-AR, covering a wide range of scenes and visual styles, including landscapes, indoor environments, urban scenes, food photography, and human portraits, demonstrating the model’s strong visual fidelity and compositional diversity.
| Model | Params | Latency (ms) | Single Obj. | Two Obj. | Counting | Colors | Position | Color Attri. | Overall |
|---|---|---|---|---|---|---|---|---|---|
| Diffusion Models | |||||||||
| LDM | 1.4B | - | 0.92 | 0.29 | 0.23 | 0.70 | 0.02 | 0.05 | 0.37 |
| DALL-E 2 | 4.2B | - | 0.94 | 0.66 | 0.49 | 0.77 | 0.10 | 0.19 | 0.52 |
| DALL-E 3 | - | - | 0.96 | 0.87 | 0.47 | 0.83 | 0.43 | 0.45 | 0.67 |
| SD3 | 8B | - | 0.98 | 0.84 | 0.66 | 0.74 | 0.40 | 0.43 | 0.68 |
| Transfusion | 7.3B | - | - | - | - | - | - | - | 0.63 |
| Nitro-E | 0.30B | 387 | 0.99 | 0.81 | 0.54 | 0.87 | 0.28 | 0.42 | 0.66 |
| Autoregressive Models | |||||||||
| Show-o | 1.3B | 5,187 | 0.95 | 0.52 | 0.49 | 0.82 | 0.11 | 0.28 | 0.53 |
| LlamaGen | 0.78B | 14,267 | 0.69 | 0.34 | 0.55 | 0.19 | 0.06 | 0.02 | 0.31 |
| LightGen | 0.70B | 54,846 | 0.98 | 0.58 | 0.37 | 0.86 | 0.14 | 0.28 | 0.53 |
| Fluid | 0.37B | - | 0.96 | 0.64 | 0.53 | 0.78 | 0.33 | 0.46 | 0.62 |
| Nitro-AR | 0.32B | 328 | 0.99 | 0.80 | 0.61 | 0.86 | 0.26 | 0.44 | 0.66 |
| Nitro-AR Joint Samp. | 0.39B | 74 | 0.97 | 0.68 | 0.52 | 0.84 | 0.24 | 0.37 | 0.60 |
Comparison with Existing Autoregressive Models#
Table 1 summarizes the quantitative comparison between Nitro-AR and representative diffusion-based and autoregressive image generation models. All latency measurements are conducted on AMD Instinct™ MI325X GPUs, reporting the end-to-end time required to generate a single 512×512 image. Generation quality is evaluated using GenEval [11], which assesses compositional reasoning abilities such as object counting, spatial relations, and color attributes.
We compare Nitro-AR with prior autoregressive image generation methods of similar or larger scale. Despite its significantly smaller size (0.3B parameters), Nitro-AR achieves a high GenEval score of 0.66, demonstrating superior generation quality. At the same time, it offers a clear efficiency advantage, with an inference latency of 328 ms—roughly one to two orders of magnitude faster than existing AR models. Further optimizing with joint sampling reduces latency to 74 ms. These results show that Nitro-AR strikes a strong balance between model compactness, generation fidelity, and inference speed, establishing a favorable Pareto frontier among sub-1B autoregressive models.
Comparison with Diffusion-Based Models#
Although large diffusion models such as DALL-E 3 and SD3 achieve slightly higher GenEval scores (0.67–0.68), they require much larger model sizes (4B–8B parameters) and incur significantly higher sampling costs. In comparison, Nitro-AR reaches a competitive GenEval score of 0.66 with only 0.3B parameters, and its generation quality and latency are roughly on par with its diffusion-based counterpart, Nitro-E. This shows that masked autoregressive generation with continuous token prediction can achieve diffusion-level quality in a much more compact and efficient setup.
Ablation Study#
To achieve the performance reported in Table 1, we explore several strategies to improve sampling efficiency, with the ablation results summarized in Table 2. The baseline model uses 20 autoregressive (AR) steps, each with a 20-step diffusion process, achieving a GenEval score of 0.66 at 633 ms latency. This baseline, along with its optimized variants (DiSA and Adversarial Fine-Tuning), falls under the Standard AR Sampling paradigm, where tokens are sampled independently by the MLP head.
We first apply Diffusion Step Annealing (DiSA), gradually reducing the number of denoising steps from 20 in early AR iterations to 5 in later ones. This reduces latency to 477 ms (25% faster) while maintaining a GenEval of 0.65. Adversarial fine-tuning further compresses the diffusion process, consistently using only 3 denoising steps per AR iteration. This yields a latency of 328 ms (48% faster) with no loss in GenEval (0.66), demonstrating a stronger effect than DiSA.
Finally, we introduce Joint AR Sampling, which enables a single AR step per generation, achieving a latency of 145 ms (77% faster) with a GenEval of 0.60. Combining Joint Sampling with adversarial fine-tuning reduces denoising steps from 20 to 6, further lowering latency to 74 ms (88% faster) while maintaining a GenEval of 0.60, showing that high-quality generation is possible even under extremely aggressive acceleration.
| Model | Params | Latency (ms) | Single Obj. | Two Obj. | Counting | Colors | Position | Color Attri. | Overall |
|---|---|---|---|---|---|---|---|---|---|
| Standard AR Sampling | |||||||||
| Baseline | 0.32B | 633 | 0.99 | 0.80 | 0.55 | 0.86 | 0.29 | 0.44 | 0.66 |
| + DiSA | 0.32B | 477 | 0.99 | 0.80 | 0.56 | 0.86 | 0.29 | 0.43 | 0.65 |
| Nitro-AR (+ Adversarial FT) | 0.32B | 328 | 0.99 | 0.80 | 0.61 | 0.86 | 0.26 | 0.44 | 0.66 |
| Joint AR Sampling | |||||||||
| Baseline | 0.39B | 145 | 0.96 | 0.66 | 0.51 | 0.85 | 0.24 | 0.38 | 0.60 |
| Nitro-AR Joint Samp. (+ Adversarial FT) | 0.39B | 74 | 0.97 | 0.68 | 0.52 | 0.84 | 0.24 | 0.37 | 0.60 |
Summary#
In this blog post, we extend our previous work Nitro-E by adapting the same E-MMDiT backbone to a masked modeling autoregressive framework, providing a complementary alternative to diffusion-based generation. Our AR variant, Nitro-AR, achieves comparable performance to its diffusion counterpart while significantly reducing inference latency, demonstrating that masked autoregressive generation with continuous token prediction differs fundamentally from traditional discrete-token AR models and can approach diffusion-level image quality in a compact setting.
Beyond the base model, we explore a series of designs that enable high-quality few-step and single-step generation within the AR paradigm, including joint sampling and adversarial optimization of the prediction head. These results highlight an increasingly blurred boundary between autoregressive and diffusion-based generation, and suggest promising future directions such as stronger one-step or low-step AR models and exploration of architectures that could integrate understanding to assist generation. We hope this work offers a useful perspective and encourages further exploration of efficient image generation models.
Resources#
Model: AMD/Nitro-AR · HuggingFace
Code: AMD-AIG-AIMA/Nitro-AR
Related Work from AMD team:
References#
Sun, Peize, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, and Zehuan Yuan. “Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation.” arXiv preprint arXiv:2406.06525 (2024).
Tian, Keyu, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. “Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction.” Advances in Neural Information Processing Systems 37 (2024): 84839-84865.
He, Yefei, Yuanyu He, Shaoxuan He, Feng Chen, Hong Zhou, Kaipeng Zhang, and Bohan Zhuang. “Neighboring Autoregressive Modeling for Efficient Visual Generation.” arXiv preprint arXiv:2503.10696 (2025).
Ren, Sucheng, Qihang Yu, Ju He, Xiaohui Shen, Alan Yuille, and Liang-Chieh Chen. “Beyond Next-Token: Next-X Prediction for Autoregressive Visual Generation.” arXiv preprint arXiv:2502.20388 (2025).
Li, Tianhong, Yonglong Tian, He Li, Mingyang Deng, and Kaiming He. “Autoregressive Image Generation without Vector Quantization.” Advances in Neural Information Processing Systems 37 (2024): 56424-56445.
Ren, Sucheng, Qihang Yu, Ju He, Xiaohui Shen, Alan Yuille, and Liang-Chieh Chen. “FlowAR: Scale-Wise Autoregressive Image Generation Meets Flow Matching.” arXiv preprint arXiv:2412.15205 (2024).
Zhao, Qinyu, Jaskirat Singh, Ming Xu, Akshay Asthana, Stephen Gould, and Liang Zheng. “DiSA: Diffusion Step Annealing in Autoregressive Image Generation.” arXiv preprint arXiv:2505.20297 (2025).
Sauer, Axel, Frederic Boesel, Tim Dockhorn, Andreas Blattmann, Patrick Esser, and Robin Rombach. “Fast High-Resolution Image Synthesis with Latent Adversarial Diffusion Distillation.” In SIGGRAPH Asia 2024 Conference Papers, pp. 1-11. 2024.
Fan, Lijie, Tianhong Li, Siyang Qin, Yuanzhen Li, Chen Sun, Michael Rubinstein, Deqing Sun, Kaiming He, and Yonglong Tian. “Fluid: Scaling Autoregressive Text-to-Image Generative Models with Continuous Tokens.” arXiv preprint arXiv:2410.13863 (2024).
Wu, Xianfeng, Yajing Bai, Haoze Zheng, Harold Haodong Chen, Yexin Liu, Zihao Wang, Xuran Ma, et al. “LightGen: Efficient Image Generation through Knowledge Distillation and Direct Preference Optimization.” arXiv preprint arXiv:2503.08619 (2025).
Ghosh, Dhruba, Hannaneh Hajishirzi, and Ludwig Schmidt. “GenEval: An Object-Focused Framework for Evaluating Text-to-Image Alignment.” Advances in Neural Information Processing Systems 36 (2023): 52132-52152.
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.